分布式日志收集框架Flume简介及环境安装部署
最近在做一个基于Spark Streaming的实时流处理项目,之间用到了Flume来收集日志信息,所以在这里总结一下Flume的用法及原理.
Flume是一个分布式、高可靠、高可用、负载均衡的进行大量日志数据采集、聚合和并转移到存储中的框架, 基于流式架构,容错性强,也很灵活简单,主要用于在线实时的引用分析,只能在Unix环境下运行,底层源码由Java实现.
Flume目前常见的应用场景:日志—>Flume—>实时计算(如Kafka+Storm或者Spark Streaming) 、日志—>Flume—>离线计算(如HDFS、HBase)、日志—>Flume—>ElasticSearch。
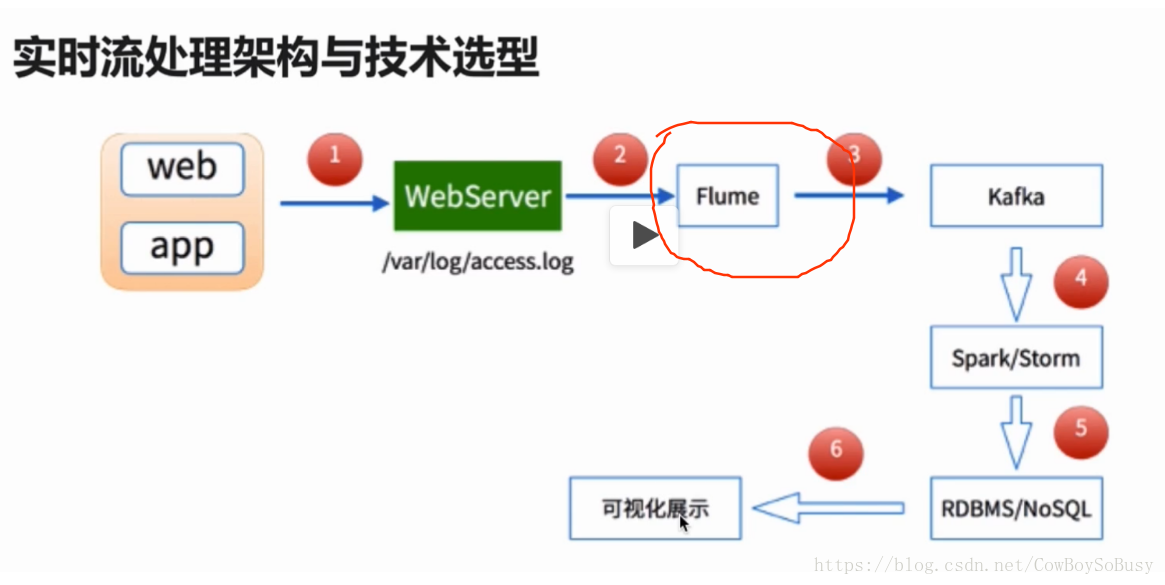
Flume架构及核心组件:

multi-agent

更多架构图见用户文档
https://flume.apache.org/FlumeUserGuide.html
Flume主要分为三个组件:Source、Channel、Sink
1、Source负责日志流入,比如从文件、网络、Kafka等数据源流入数据,数据流入的方式有两种,轮训拉取和事件驱动;
2、Channel负责数据聚合/暂存,比如暂存到内存、本地文件、数据库、Kafka等,类似于缓冲区,日志数据不会在管道停留很长时间,很快会被Sink消费掉;
3、Sink负责数据转移到存储,比如从Channel拿到日志后直接存储到HDFS、HBase、Kafka、ElasticSearch等,然后再有如Hadoop、Storm、ElasticSearch之类的进行数据分析或查询。
一个Agent会同时存在这三个组件,Source和Sink都是异步执行的,相互之间不会影响。
要想学得好,官网少不了.https://flume.apache.org/
安装部署:
首先Java环境要配好,JDK1.7或者1.8,配好环境变量等等,这个应该都没问题,不多说了
Flume下载:http://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.6.0-cdh5.7.1.tar.gz
自己选择相应版本即可
完成后解压缩,ls看到文件如下:

这里只需要注意bin和conf文件夹即可
现在将flume路径配置到环境变量里面
vi /etc/profile
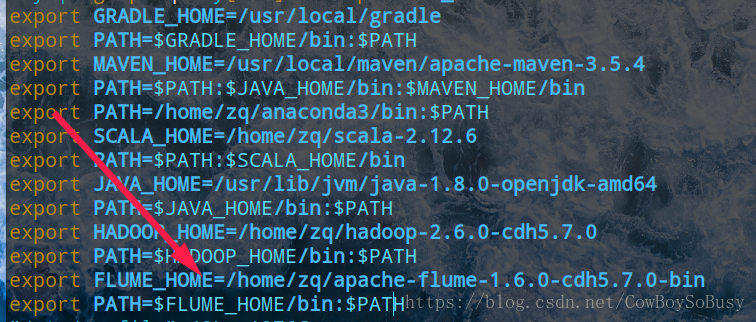
source /etc/profile
然后输入 echo $FLUME_HOME即可看到flume的路径
/home/zq/apache-flume-1.6.0-cdh5.7.0-bin
开始配置:
依次执行以下命令
cd conf cp flume-env.sh.template flume-env.sh
修改flume-env.sh文件
添加jdk路径
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
检测是否安装成功:
查看版本信息
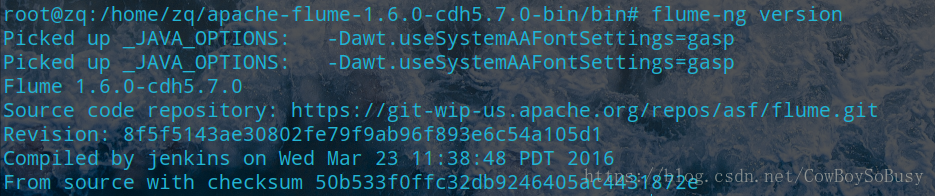
表示已经安装成功

- 日志采集框架Flume以及Flume的安装部署(一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统)
- 分布式日志收集框架Flume 部署说明
- 日志采集框架Flume以及Flume的安装部署(一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统)
- 分布式日志收集框架Flume:监控一个文件实时采集新增的数据输出到控制台
- 分布式数据日志收集之Flume的安装和使用
- 分布式日志收集框架flume实战
- 基于Hadoop的日志收集框架---Chukwa的安装部署
- 分布式日志收集框架Flume学习笔记
- 分布式日志收集框架Flume
- 分布式日志收集框架Flume:从指定网端口采集数据输出到控制台
- 日志抽取框架 flume 简介与安装配置
- 基于Hadoo的日志收集框架---Chukwa的安装部署
- C#实现多级子目录Zip压缩解压实例 NET4.6下的UTC时间转换 [译]ASP.NET Core Web API 中使用Oracle数据库和Dapper看这篇就够了 asp.Net Core免费开源分布式异常日志收集框架Exceptionless安装配置以及简单使用图文教程 asp.net core异步进行新增操作并且需要判断某些字段是否重复的三种解决方案 .NET Core开发日志
- 基于Hadoo的日志收集框架---Chukwa的安装部署
- Spark Streaming 02 分布式日志收集框架flume
- asp.Net Core免费开源分布式异常日志收集框架Exceptionless安装配置以及简单使用图文教程
- 日志收集框架flume的安装及简单使用
- 分布式消息队列Kafka简介及环境安装部署
- J2EE分布式框架--开发环境部署