(译)奇异值谱分析
#前言
本文翻译自Kspectra -tool
有兴趣的人可以去原文看看,话不多说开始讲解。
#奇异值谱分析
奇异值谱分析是一种非参数方法。它试图避免使用参数化方法-假定一个模型拟合时间序列,并且克服有限采样点数和采样噪声带来的问题。该方法使用一个数据自适应的基,而不是使用Blackman-Tukey方法-固定的sine或者cousine。
Vautard and Ghil (1989: VG 之后) 意识到经典的延迟协方差分析和延迟方法之间的形式相似性。
他们指出成对的奇异值谱分析特征模式相关于近乎相等的特征值和在相位均方上相联的可以有效代表一个非线性,非谐波的振荡的(时域)主成份,更进一步探究了这个相似性。
这是因为一个单一成对的数据自适应特征模式可以抓住方波和锯齿振荡的基本的周期性,也就是说,而不是使用固定方法会分析出的更多的信息(其实并不需要的)。
SSA方法有三个基本步骤:1在一个向量维度空间里面嵌入采样时间序列;2计算MM维的数据延迟协方差矩阵CDC_DCD;3可视对角化CDC_DCD
步骤一:时间序列x(t):t=1,....,N{x(t):t=1,....,N}x(t):t=1,....,N 被嵌入到一个M维的向量空间,M是延迟矩阵的维度,其中总共有M份延迟的拷贝:x(t−j):j=1,.....,M{x(t-j):j=1,.....,M}x(t−j):j=1,.....,M 对于M的选择并没有什么金标准,但是SSA方法,在分析尺度为(M/5,M)的时候都比较成功易于实现。
步骤二:一个人定义了MM的延迟协方差矩阵估计器CDC_DCD。这里有三个不同的方法被广泛地用来定义矩阵CDC_DCD.在BK(Broomhead 和 king)的方法,一个长度为M的窗口在时间序列上进行平滑,产生了一个在嵌入空间里面长度为N‘=N-M+1的向量.这个序列被用来获得N’×M的轨迹矩阵D,其中第i行是时间序列的第i个视图。
在这个定义下,CDC_DCD被定义为奇异值谱分析:

在VG的算法里面,CDC_DCD通过对角线恒定的Toeplitz矩阵直接估计获得,即,它的元素CijC_{ij}Cij只取决于延迟|i-j|

奇异值谱Toeplitz矩阵
Burg 协方差估计是一个基于拟合AR成分数目和SSA窗口数目相等的AR模型的迭代算法。
Burg和VG的方法都需要自协方差矩阵是toeplitz的,但BK的方法不需要这个。
Burg的方法原则傻瓜会导致更少的因为采样点数有限导致的谱泄漏问题并且因此提高分辨率。
然而,Burg的估计可以导致显著的偏差当时间序列非平稳同时在时间序列里面有超低频波动的时候。因此,有时候VG方法是值得尝试的。同样,对于长的时间序列(N 大于等于5000时),VG的估计会带来更少的计算负担同时实现的更快。
在实践中,VG的方法相比Burg方法更有可能带来计算的数值不稳定性(产生了负的特征值),特别是分析纯粹的振荡。BK的方法因此有些时候会更少倾向于产生非平稳时间序列的问题。虽然 VG方法看起来是最没有问题的,但确实是极端不稳定的。然而,Toeplitz方法确实显得导致了更稳定的结果,即使在时间序受到了轻微的抖动影响。
kSpectra Toolkit里面实现了Burg,BK,和VG算法
步骤三:n点采样的协方差矩阵计算后,对矩阵进行了对角化,同时对特征值(λk\lambda_kλkk=1…M)进行了降序排列。特征值『λk,k=1,...,M\lambda _k,k=1,...,Mλk,k=1,...,M』给出了对应的特征向量Ek对应的特定方向的时间序列的方差。特征值的均方根是奇异值,对应的集合是奇异谱。这些概念给定了SSA是它的名字;BK 展示了如何通过将SVD方法应用到迹矩阵Matrix D从而获得奇异值谱。VG调用了EK向量的时间经验正交函数(EOFs),通过在仿真的气象学数据,使用在空域的PCA验证。
如果我们排列和画出降序的奇异值,就可以区分始降的斜坡,代表着信号,或者平坦的阶梯代表着噪声,为了正确的区分信号与噪声,这个可视化的观测谱值区分,必须用后文所示的,一个合适的准则使用统计显著性进行区分。
一旦这些斜坡被实现,一些其他的有趣的结果同样也可以获得。
对于每一个经验正交函数Ek,带着成分 {Ek(j): j=1, …M},我们可以构建长度为N的时间序列,通过以下公式:
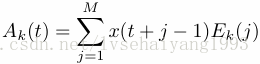
奇异值谱分析的主成分:
被称作第K个主成份,它代表着原时间序列在K阶经验正交函数上的投射,主成份的功率谱的和等价于时间序列的功率谱;因此,我们可以学习到区分不同成分特征谱的贡献。主成份,然而,有长度N‘,而不是N,并且不包含相位信息。
为了提取出长度为N的时间序列,对应于选择出来的K个特征元素的子集。相关的主成分被用来重建部分原始时间序列X(t)。时间序列的主要成分。
奇异值谱重建。

和

这些时间长度为N的时间序列被叫做重建成份。他们对保持时间序列的相位信息有重要的价值。因此,对应于x(t)和RK(t)可以被强化。当k包含了单个奇异值向量Ek的成分,RK(t)被称作K阶RC。这个时间序列可以累加RC从而不丢失任何信息地完全重建,当存在一个线性趋势,基于BK算法的重建在采样的终点拥有准确的优势。
对于准确的部分重建信号,即,在正确的集合K={1,2,…S}的经验正交函数上重建,诱导了相对于白噪声,最优的信噪比增强。极大熵谱估计在这个干净的信号上会工作地非常好,而不是原始的时间序列,是带宽限制的。作为一个结果,一个低阶的自回归模型拟合可以诱导好的谱分辨率,同时没有假影峰值。
为了表现一个好的信号重建或者它的振荡部分检测,有几个方法——或者启发式的或者基于蒙特卡罗的想法可以用来分开信号和噪声或者准确识别振荡部分或者趋势,在kSpectra 工具箱里也有。

- 机器学习之SVD奇异值原理分析及举例
- 主成分分析与奇异值分解的关系
- 16.PCA续,奇异值分解SVD,独立成分分析ICA
- 数据降维:特征值分解和奇异值分解的实战分析
- 蒙特卡罗奇异值谱分析
- 斯坦福ML公开课笔记15—隐含语义索引、奇异值分解、独立成分分析
- 几种线程池的实现算法分析
- 利用grep命令查找字符串分析log文件的一次实践
- PPP协议实例分析与理解
- Android App启动流程分析
- GC之七--gc日志分析工具
- 微信 小程序前端源码详解及实例分析
- 深入分析由前序和中序重构二叉树问题
- STM32串口第一个字节丢失问题的分析过程
- 数值分析 追赶法求解三对角线性方程组 MATLAB实现
- (二)启动代码分析 01
- 织梦Dedecms buy_action.php SQL注入漏洞分析
- 【译】理解与分析ios应用的崩溃报告
- JBoss 系列五十八:jBPM Human Task 源代码分析 - I
- findbugs 错误分析