python爬虫之微信文章抓取
2018-09-03 16:36
381 查看
版权声明:如有使用转载,请附加出处 https://blog.csdn.net/jia666666/article/details/82350761
模块安装
这里涉及到的模块,没有安装的可以自己安装
MangoDB环境配置pip install xxx
https://blog.csdn.net/jia666666/article/details/82191990
python爬虫之ProxyPool(代理ip地址池的构建)
实现目的
通过搜狗搜素相关关键词的微信文章,通过解析,提取相关信息,保存到mongdb数据库中,
关键词可以进行修改,获取目标内容
源码
import requests
from urllib.parse import urlencode
from requests.exceptions import ConnectionError
from pyquery import PyQuery as pq
import pymongo
client=pymongo.MongoClient('localhost')
db=client['weixin']
#url请求地址
base_utl='http://weixin.sogou.com/weixin?'
#搜索关键词
keyword='风景'
#最大请求失败次数
max_count=5
#代理是否启用
proxy=None
#获取代理的本地端口
proxy_pool_url='http://localhost:5555/random'
#代理获取
def get_proxy():
try:
#网页请求
response=requests.get(proxy_pool_url)
#请求成功,返回数据
if response.status_code==200:
return response.text
return None
except ConnectionError:
return None
#网页获取
def get_html(url,count=1):
#正在爬取的网页,次数
print('Crawling',url)
print('craw time',count)
global proxy
#最大失败数判断
if count>=max_count:
print('tried too many counts')
return None
try:
#代理判断是否为真
if proxy:
#代理地址拼接
proxyies={
'http':'http://'+proxy
}
#代理网页请求
response = requests.get(url, allow_redirects=False,proxies=proxyies)
else:
#本机ip地址请求,不允许自动跳转链接
response=requests.get(url,allow_redirects=False)
#网页状态码判断是否成功获取
if response.status_code==200:
#返回数据
return response.text
if response.status_code==302:
#启用代理
proxy=True
#获取代ip:port
proxy=get_proxy()
#使用代理,重新执行
if proxy:
print('USing Proxy',proxy)
return get_html(url)
else:
#代理获取失败
print('get proxy failed')
return None
except ConnectionError as e :
#输入错误信息
print('Error Occurred',e.args)
#失败次数加一
count+=1
#代理ip地址获取
proxy=get_proxy()
#重新执行
return get_html(url)
def get_index(keyword,page):
#请求的数据
data={
'query':keyword,
'type':2,
'page':page
}
#url编码
queries=urlencode(data)
#url拼接
url=base_utl+queries
#函数调用
html = get_html(url)
#返回网页
return html
def parse_index(html):
#网页解析
doc=pq(html)
#信息提取
items=doc('.news-box .news-list li .txt-box h3 a').items()
#返回文章链接
for item in items:
yield item.attr('href')
#获取文章链接的内容
def get_detail(url):
try:
response=requests.get(url)
if response.status_code==200:
return response.text
return None
except ConnectionError:
return None
#文章内容的信息解析提取
def parse_detail(html):
doc=pq(html)
title=doc('.rich_media_title').text()
content=doc('.rich_media_content ').text()
date=doc('#publish_time').text()
nickname=doc('#js_name').text()
name=doc('#js_profile_qrcode > div > p:nth-child(3) > span').text()
return {
'title':title,
'date':date,
'nickname':nickname,
'name':name,
'content': content
}
#保存到mongodb数据库
def save_to_mongo(data):
if db['articles'].insert(data):
print('save to mongo',data['title'])
else:
print('save to mongo failed',data['title'])
def main():
#获取10页
for page in range(1,10):
html=get_index(keyword,page)
if html:
article_urls=parse_index(html)
for article_url in article_urls:
article_html=get_detail(article_url)
if article_html:
article_data=parse_detail(article_html)
print(article_data)
save_to_mongo(article_data)
if __name__ == '__main__':
main()
这里只是采集前10页的内容,所有内容的采集需要微信登录才可以,一共会有100页,搜狗具有反爬虫处理,当一个ip过于频繁的访问会出现301或302错误,这是搜狗反爬虫检测到异常,我们这里只是10页,效果还不太明显,几十页的访问时就会出现错误,这里启动了ip地址代理服务,会替换被封禁的ip继续进行访问,直至目标信息访问完成,代理会提供一个api接口,使程序用来得到ip地址
写入数据库后,打开查看如图,里面记录爬取的所有信息
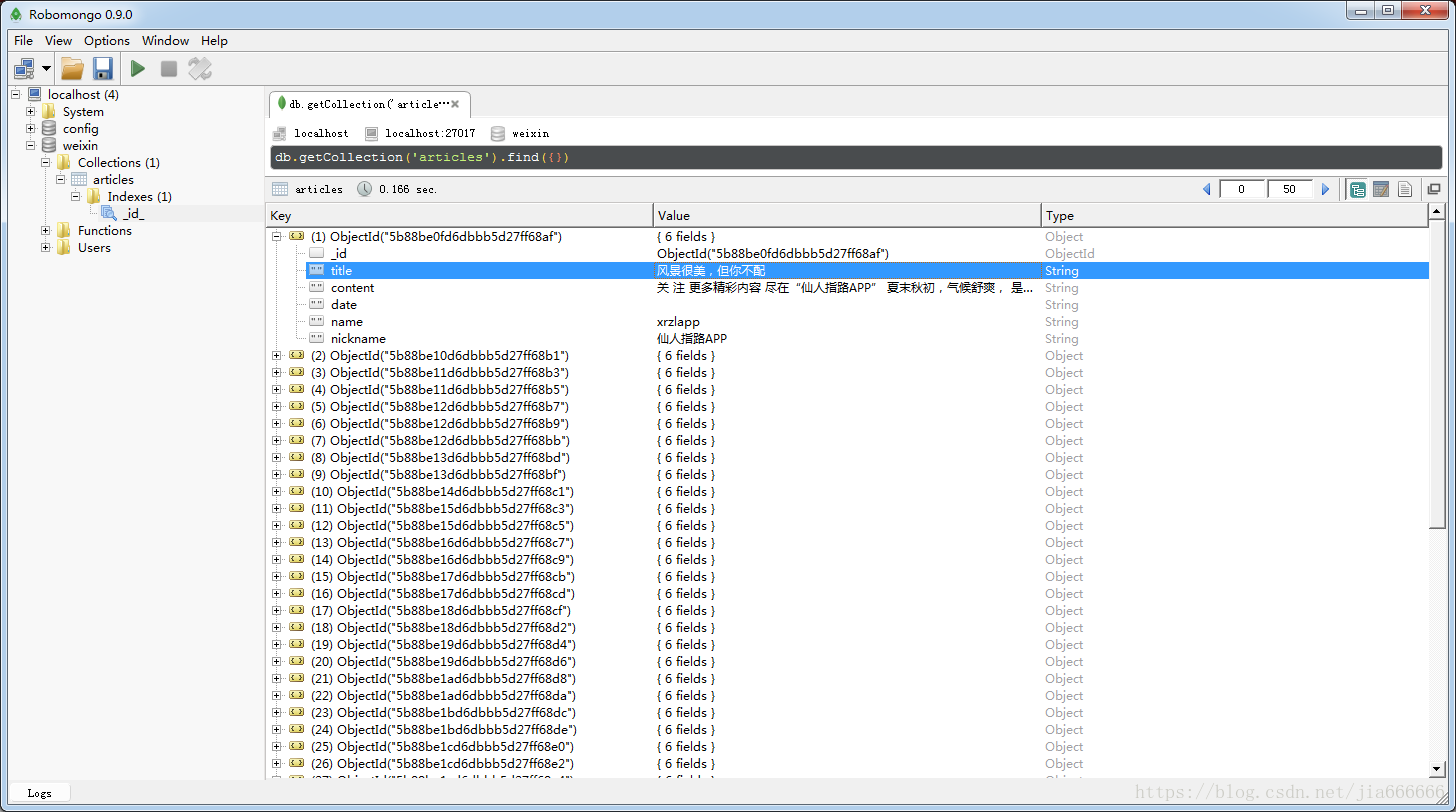
右键可以选择浏览文件
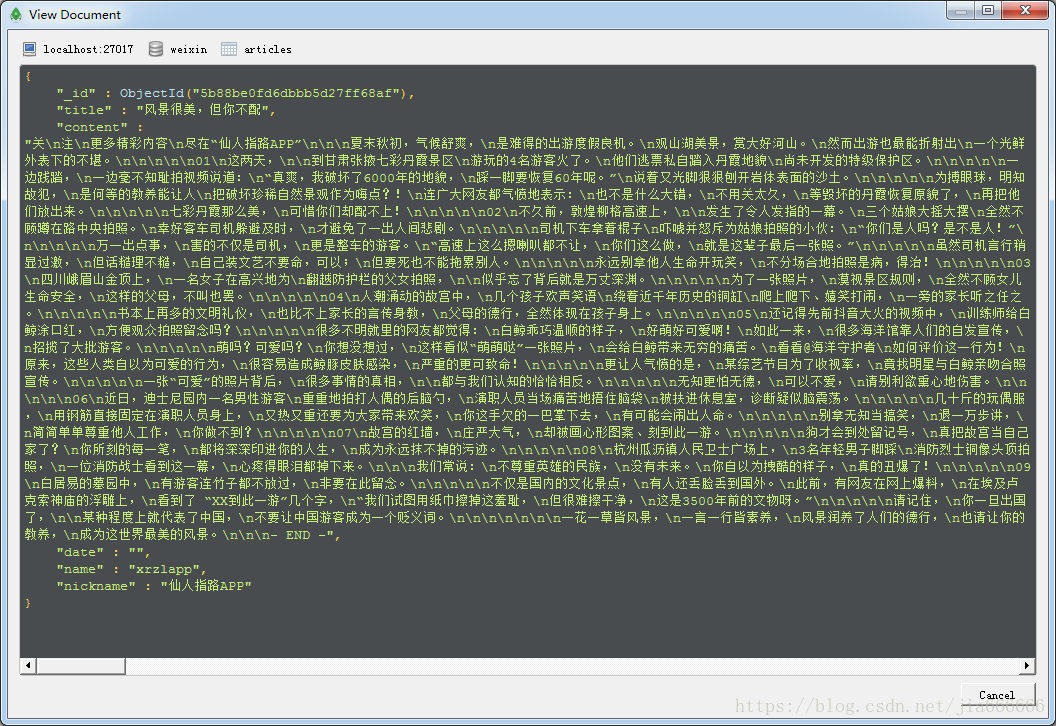

相关文章推荐
- [Python爬虫] 之十五:Selenium +phantomjs根据微信公众号抓取微信文章
- nodejs爬虫-通过抓取搜狗微信网站获取微信文章信息
- python爬虫实战(三)--------搜狗微信文章(IP代理池和用户代理池设定----scrapy)
- python爬虫——爬取微信文章
- python爬虫之python2.7.8抓取csdn博客文章
- python爬虫CSDN文章抓取
- python爬虫(17)爬出新高度_抓取微信公众号文章(selenium+phantomjs)(上)
- python爬虫,抓取新浪科技的文章(beautifulsoup+mysql)
- Hello Python!用python写一个抓取CSDN博客文章的简单爬虫
- [Python学习] 简单网络爬虫抓取博客文章及思想介绍
- python爬虫CSDN文章抓取
- Python爬虫练习之二:抓取游民星空搞笑动态图文章链接
- python爬虫实战--------搜狗微信文章(IP代理池和用户代理池设定----scrapy)
- python爬虫抓取51cto博客大牛的文章保存到本地excel文件
- [Python学习] 简单网络爬虫抓取博客文章及思想介绍
- nodejs爬虫抓取搜狗微信文章详解
- python爬虫抓取51cto博客大牛的文章保存到MySQL数据库
- [Python学习] 简单网络爬虫抓取博客文章及思想介绍
- python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息,抓取政府网新闻内容
- Python爬虫实战(三) — 微信文章爬虫