【pytorch】如何在pytorch自定义优化函数?
pytorch 可以说是最简单易学的深度学习库了,为了加快神经网络的学习效率我们通常会使用一些加速技巧,但很多人都是使用的torch.optim自带的优化器,本文就将介绍如何自定义一个优化器并比较其与主流算法的加速效果
1.准备工作
首先下载minst数据库作为测试数据集合minst
我们需要train-images.idx3-ubyte和train-labels.idx1-ubyte这两个文件
读取数据并且定义全连接神经网络784→100→10作为测试网络
import torch
from torch.autograd import Variable
import numpy as np
import struct
import os
def loadImageSet(filename):
print ("加载图像数据中...",filename)
binfile= open(filename, 'rb')
buffers = binfile.read()
head = struct.unpack_from('>IIII' , buffers ,0)
print ("head,",head)
offset = struct.calcsize('>IIII')
imgNum = head[1]
width = head[2]
height = head[3]
#[60000]*28*28
bits = imgNum * width * height
bitsString = '>' + str(bits) + 'B' #like '>47040000B'
imgs = struct.unpack_from(bitsString,buffers,offset)
binfile.close()
imgs = np.reshape(imgs,[imgNum,1,width*height])
print ("图像数据加载完毕")
return imgs
def loadLabelSet(filename):
print ("加载标签中...",filename)
binfile = open(filename, 'rb')
buffers = binfile.read()
head = struct.unpack_from('>II' , buffers ,0)
print ("head,",head)
imgNum=head[1]
offset = struct.calcsize('>II')
numString = '>'+str(imgNum)+"B"
labels = struct.unpack_from(numString , buffers , offset)
binfile.close()
labels = np.reshape(labels,[imgNum,1])
print ('标签加载完毕')
return labels
if __name__=="__main__":
GPU=0
learning_rate = 0.01
path=os.path.split(os.path.realpath(__file__))[0]
os.chdir(path)
np.set_printoptions(suppress=True,precision=1, threshold=100)
imgs = loadImageSet("train-images.idx3-ubyte")
labels = loadLabelSet("train-labels.idx1-ubyte")
imgs=np.where(imgs>108,1,0)#图像二值化
N, D_in, H, D_out = 50000 , 784, 100, 10
start=0
"""
定义网络结构与初始参数
"""
if GPU:
print("GPU加速启用")
dtype = torch.cuda.FloatTensor
else:
dtype = torch.FloatTensor
print("GPU加速关闭")
print("初始化完毕开始训练MNIST数据集")
print("网络单批数量为" + str(N))
print("隐藏层节点数目为" + str(H))
x = imgs[start:start+N].squeeze()
y = labels[start:start+N]
ss = np.zeros((N, 10))
for i in range(N):
ss[i][int(y[i])]=1
x = torch.from_numpy(x)
y = torch.from_numpy(ss)
x = Variable(x.type(dtype), requires_grad=False)
y = Variable(y.type(dtype), requires_grad=False)
w1 = Variable(torch.randn(D_in, H).type(dtype), requires_grad=True)
w2 = Variable(torch.randn(H, D_out).type(dtype), requires_grad=True)
net = torch.nn.Sequential(
torch.nn.Linear(D_in, H),
torch.nn.ReLU(),
torch.nn.Linear(H, D_out),
torch.nn.Sigmoid()
)
if GPU:
net.cuda()
loss_func = torch.nn.MSELoss() #使用MSE损失函数
#net.load_state_dict(torch.load('net_params.pkl'))
2.编写优化函数
其实优化函数的编写目前主要靠修改梯度值和学习率从而改变参数的步进值
这里我们选用Momentum来改变梯度的值再使用Rprop算法来改变学习率
Momentum算法简介
动量算法通过累积梯度来改变动量,也就是说当前梯度的值会受到历史梯度的影响
当当前梯度与历史梯度一致时,动量就会被加大,最大值为1/(1-γ),反之,如果梯度来回震荡那么动量就会被当前梯度抵消减弱。
动量更新公式:V(t)=γV(t−1)+η∇(θ).J(θ)
Rprop算法简介
Rprop算法非常的直观,如果梯度方向连续增大就提高学习率,如果梯度震荡就减小学习率。使用这种方法必须给学习率增加一个安全阈值,防止学习率爆炸和学习率过低。
学习率更新公式:
if g(t)*g(t-1)>0
lr=lr*a
if g(t)*g(t-1)<0
lr=lr*b
其中学习率是为每个参数都单独设置的,a为增量,b为衰减量。显然其对平坦区域的加速效率为(a)^t,是指数级的加速效果。其对沟谷的减速效果同样为(b)^t,是指数级的衰减效果。
我们的设置
我们设置动量保留值γ为0.75,学习率衰减率b=0.55,学习率增加量a=1.05
def myopt():
pre=[] #pre储存当前梯度与历史梯度方向是否一致的信息
lr=[] #lr储存各层各参数学习率
vdw=[] #vdw储存各层各参数动量
y_pred = net(x)
loss = loss_func(y_pred, y)
net.zero_grad()
loss.backward()
for param in net.parameters():
lr.append(param.grad.data.clamp(min=0.01,max=0.01))
pre.append(torch.sign(param.grad.data))
vdw.append(param.grad.data)
#首先初始化列表
for i in range(2000):
y_pred = net(x)
loss = loss_func(y_pred, y)
print("第"+str(i)+"步 损失值="+str(loss.item()))
net.zero_grad()
loss.backward()
m=0
for param in net.parameters():
vdw[m] = 0.75 * vdw[m] + param.grad.data
pre[m]=torch.sign(param.grad.data)*torch.sign(vdw[m])
lr[m] = lr[m]*(0.8+pre[m]*0.25)
lr[m] = lr[m].clamp(min=1e-8,max=100)
param.data -= vdw[m] * lr[m]
m+=1
3.优化效果比较
最后定义自带的优化器与原始下降方法
def origin():
for i in range(2000):
y_pred = net(x)
loss = loss_func(y_pred, y)
print("第"+str(i)+"步 损失值="+str(loss.item()))
net.zero_grad()
loss.backward()
for param in net.parameters():
param.data -= learning_rate * param.grad.data
def opt():
opt_SGD = torch.optim.SGD(net.parameters(), lr=learning_rate)
opt_Momentum = torch.optim.SGD(net.parameters(), lr=learning_rate, momentum=0.8)
opt_RMSprop = torch.optim.RMSprop(net.parameters(), lr=learning_rate, alpha=0.9)
opt_Adam = torch.optim.Adam(net.parameters(), lr=learning_rate, betas=(0.9, 0.99))
opt=[opt_SGD,opt_Momentum,opt_RMSprop,opt_Adam]
choose=3
loss_func = torch.nn.MSELoss()
for i in range(2000):
# 对x进行预测
prediction = net(x)
# 计算损失
loss = loss_func(prediction, y)
# 每次迭代清空上一次的梯度
print("第"+str(i)+"步 损失值="+str(loss.item()))
opt[choose].zero_grad()
# 反向传播
loss.backward()
# 更新梯度
opt[choose].step()
opt()
torch.save(net.state_dict(), "net_params.pkl")
最后附上我们自定义的优化器与公认最好的优化器Adma的以及RMSprop优化效果的比较
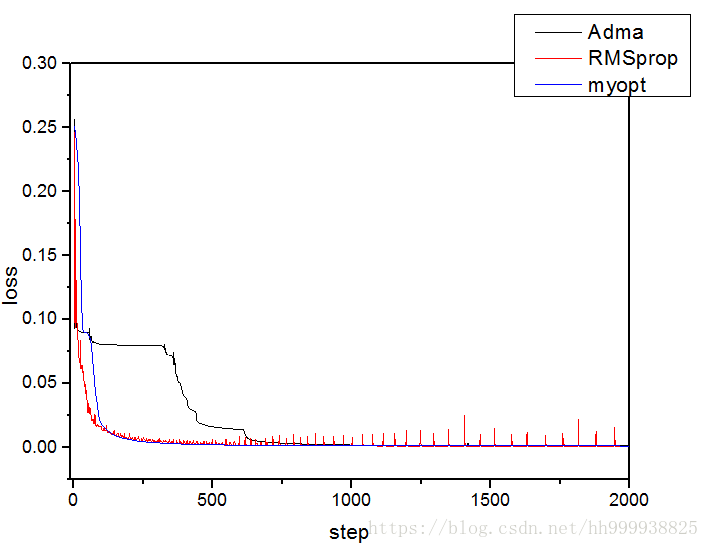
可以看出前期的下降速率RMSprop>myopt>Adma
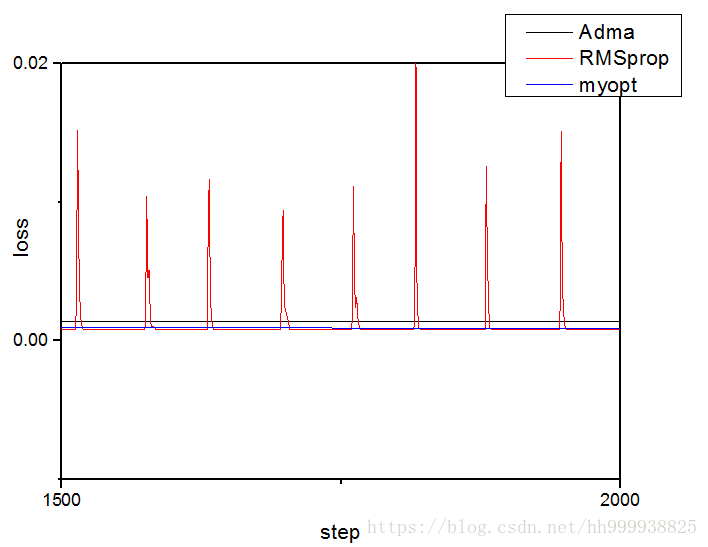
列出了后期的下降速率,在这个模型中RMSprop基本与myopt的最低值相等,但是RMSprop震荡严重而myopt基本没有震荡,这两种算法的后期优化结果在这个模型中都优于Adma

- pytorch里一些函数的说明记录
- pytorch中的pre-train函数模型或者旧的模型的引用及修改(增减网络层,修改某层参数等) finetune微调等
- Pytorch打怪路(一)pytorch进行CIFAR-10分类(3)定义损失函数和优化器
- 【python】如何在某.py文件中调用其他.py内的函数
- 算法优化,如何从120秒到0.5秒【数据结构的选择、数据类型的选择、运算优先级的选择、函数调用关系】
- 如何优化JQuery each()函数的性能
- 如何在某.py文件中调用其他.py内的函数
- 编译静态库时,如何让编译器自动优化掉未使用的函数?
- JQuery each()函数如何优化循环DOM结构的性能
- 如何优化JQuery each()函数的性能
- pytorch 如何加载部分预训练模型
- 【python】如何在某.py文件中调用其他.py内的函数
- 算法优化,如何从120秒到0.5秒【数据结构的选择、数据类型的选择、运算优先级的选择、函数调用关系】
- 【python】如何在某.py文件中调用其他.py内的函数
- PyTorch快速入门教程七(pytorch下RNN如何做自然语言处理)
- 【python】如何在某.py文件中调用其他.py内的函数
- 如何为TensorFlow和PyTorch自动选择空闲GPU,解决抢卡争端
- pytorch如何自定义自己的MyDatasets
- 【python】如何在某.py文件中调用其他.py内的函数
- python 一个.py文件如何调用另一个.py文件中的类和函数