笔记:Scrapy 爬取豆瓣电影Top250
目标:用哪个Scarpy抓取豆瓣电影Top250的名称 主演 上映时间等,保存为csv json txt 等格式 最后保存到mondo数据库中,并用Robo 3T或NoSQL Manager for MongoDB操作查看
链接:https://movie.douban.com/top250
步骤:
1.新建项目:新建project,spider
2.明确目标:在Items中定义保存电影名字 主演等的容器
3.制作爬虫:设置settings Middlewares 信息并编写爬虫
4.存储内容:存储为csv json 等格式 并存储到mongo数据库
具体思路:
1.新建项目:scrapy startproject xxx ; scrapy genspider (-t basic ) spider movie.douban.com/top250;
2.明确目标:抓取电影名称 制作介绍 主演 星级 评价 描述,在items中分别建立容器
法一:from scrapy import Spider,Field 法二:(2)import scrapy
name = Field() name = scrapy.Field()
3.爬虫编写:
(1).常用的解析器可以用css,xpath,正则,BeautifulSoup等解析器这里采用xpath;xpath当不加extract_first()时提取的是selector标签,当要提取一个标签多行时用extract();xpath提取信息时尽量提取那些属性较少的大标签,提取属性时一定要注意提取的属性是在哪种颜色的字体中!!!;
(2).这里采用先把每个电影的selector大标签提取出来,然后才根据需要提取对应的title等属性
(3).多行数据的处理,split()方法,通过指定分隔符对字符串进行切片;"".join方法把字符串加到一起
(4).多页数据的提取一般是用递归的方法回调第一页数据...
4.数据存储
(1)在命令行中运行scrapy crawl spider -o csv或者-o json等用 -o保存文件,可以用notepad++,excel打开查看
(2)保存到mongo:
法一:采用4+2+2句保存(适用于简单的项目)这里采用这种简单的
法二:用函数方法实现(更正式)eg:
[code]class MongoPipeline(object):
collection_name = 'users'
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
self.db[self.collection_name].update({'url_token': item['url_token']}, dict(item), True)
return item
再在setting中设置mongo参数并开启Pipeline
(3)mongo数据库的操作:
输入: use spider;show collections ;db.douban.find().pretty()
(4)代理中间件Middlewares的编写
一.设置代理ip(这里先不管ip代理池)
代码:
[code]class my_proxy(object): def process_request(self, request, spider): request.meta['proxy'] = 'http-dyn.abuyun.com:9020'#代理服务器的端口号 proxy_name_pass = b'HR4474S5W0J699ED:EA713F44C2EE9F6C' #用户名和密码 encode_pass_name = base64.b64encode(proxy_name_pass) #用base64对密码进行加密 request.headers['Proxy-Authorization'] = 'Basic ' + encode_pass_name.decode()
这里注意:1.base64转码要求用户名和密码用bytes类型 2.最后一行Basic后面有个空格必须有
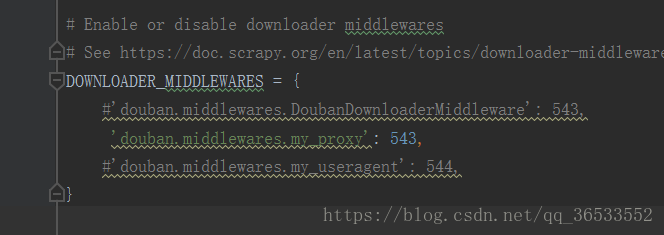
再在settings中间打开代理,且数字越小表示优先级越高:
二.设置http头部,随机添加User-Agent
[code]class my_useragent(object): def process_request(self, request, spider): user_agent_list = [ 'MSIE (MSIE 6.0; X11; Linux; i686) Opera 7.23', 'Opera/9.20 (Macintosh; Intel Mac OS X; U; en)', 'Opera/9.0 (Macintosh; PPC Mac OS X; U; en)', 'iTunes/9.0.3 (Macintosh; U; Intel Mac OS X 10_6_2; en-ca)', 'Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)', 'iTunes/4.2 (Macintosh; U; PPC Mac OS X 10.2)', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0', 'Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)', 'Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)' ] agent = random.choice(user_agent_list) request.headers['User_Agent'] = agent
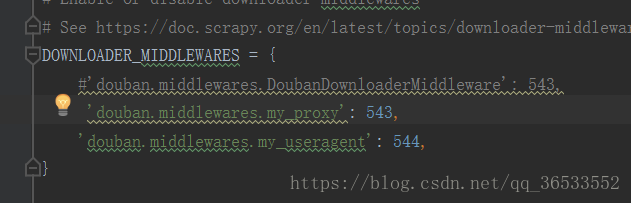
同理在settings打开download 中间件:
备注小知识:
1.爬虫名和项目名不能一致; scrapy crawl spider启动爬虫可以加上--nolog不看日志;启动爬虫时最好吧User-Agent开启,因为一般现在的网站都要有User-Agent才能访问否则返回 500的错误
2.文件夹自带的scrapy.cfg文件作用:项目的配置文件,文件路径,部署信息,或者搭建监控爬虫的项目等
3.settings作用:项目的设置文件,可以定义项目的全局设置eg:User-Agent;Robot协议;并发量一边默认16;下载延迟可以自己改;以及更改每个域名的并发量和每个ip的并发量;开启cookie;开启中间件;扩展中间件
4.查找元素时先查看网页的编码方式
5.Middlewares是设置中间件的地方,比如:User-Agent, Proxy,Cookies代理
6.xpath提取信息的理解: eg://div[@class = 'article']//ol[@class = 'grid_view']/li 理解为提取div,这个div标签的特征是class='article'..提取ol标签,其特征是class='grid_view'; //意思是提取 ,# 表示id,/表示下一层
7.Pipeline中用process_item方法进行数据的插入,但必须返回return item或者return Dropitem
代码:
新建个main.py的文件可以不用在命令行启动直接启动main函数就能运行
main:
[code]from scrapy import cmdline
cmdline.execute('scrapy crawl movie_spider'.split())
spider:
[code]import scrapy
from movie.items import MovieItem
class MovieSpiderSpider(scrapy.Spider):
#爬虫名字
name = 'movie_spider'
#允许的域名
allowed_domains = ['movie.douban.com']
#入口URL
start_urls = ['https://movie.douban.com/top250']
#默认的解析方法
def parse(self, response):
#用xpath提取电影的selector标签
movie_list = response.xpath("//div[@class = 'article']//ol[@class = 'grid_view']/li")
for i_item in movie_list:
#把item文件导入
movie_item = MovieItem()
'''
具体的xpath,提取所需的内容
extract()提取多条信息,相应的first提取第一条信息
'''
movie_item['serial_number'] = i_item.xpath(".//div[@class = 'item']//em/text()").extract_first()
movie_item['name'] = i_item.xpath(".//div[@class = 'hd']//span[1]/text()").extract_first()
content = i_item.xpath(".//div[@class = 'bd']/p[1]/text()").extract()
#多行数据的处理,split()方法,通过指定分隔符对字符串进行切片;"".join方法把字符串加到一起
for i_content in content:
content_s = "".join(i_content.spli
20000
t())
movie_item["introduce"] = content_s
movie_item['star'] = i_item.xpath(".//div[@class = 'star']//span[@class = 'rating_num']/text()").extract_first()
movie_item['evaluate'] = i_item.xpath(".//div[@class = 'star']//span[4]/text()").extract_first()
movie_item['describe'] = i_item.xpath(".//p[@class = 'quote']//span[@class = 'inq']/text()").extract_first()
#将数据yield到piplines里面去
yield movie_item
#提取下一页的xpath
next_link = response.xpath("//span[@class = 'next']//link/@href").extract()
#如果存在的话返回给调度器一个Request请求
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250" + next_link, callback=self.parse)
items:
[code]import scrapy class MovieItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() serial_number = scrapy.Field() star = scrapy.Field() introduce = scrapy.Field() evaluate = scrapy.Field() describe = scrapy.Field() name = scrapy.Field()
Pipleines:
[code]import pymongo from movie.settings import mongo_db_collection,mongo_db_name,mongo_port,mongo_host # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html class MoviePipeline(object): def __init__(self): host = mongo_host port = mongo_port dbname = mongo_db_name sheetname = mongo_db_collection client = pymongo.MongoClient(host = host, port = port) mydb = client[dbname] self.post = mydb[sheetname] def process_item(self, item, spider): data = dict(item) self.post.insert(data) return item
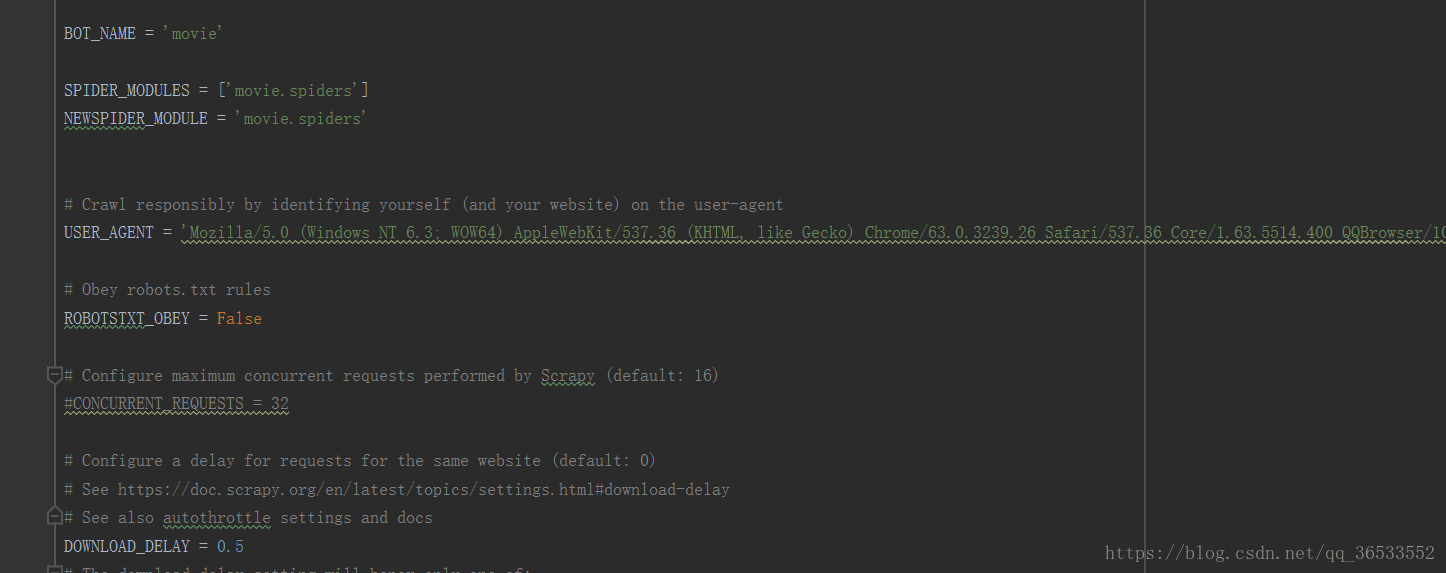
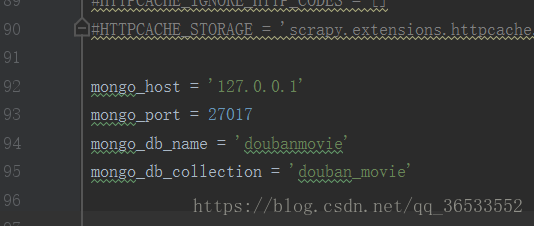
Settings:

- 爬虫框架scrapy,爬取豆瓣电影top250
- Python+Scrapy 爬取豆瓣电影排行榜Top250
- Scrapy框架学习 - 爬取豆瓣电影排行榜TOP250所有电影信息并保存到MongoDB数据库中
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
- python爬虫 Scrapy2-- 爬取豆瓣电影TOP250
- Scrapy爬虫(4)爬取豆瓣电影Top250图片
- scrapy ------ 爬取豆瓣电影TOP250
- scrapy入门实战练习(一)----爬取豆瓣电影top250
- Python 采用Scrapy爬虫框架爬取豆瓣电影top250
- Scrapy爬虫(4)爬取豆瓣电影Top250图片
- 实践Python的爬虫框架Scrapy来抓取豆瓣电影TOP250
- 使用scrapy+mongodb爬取豆瓣电影TOP250
- 运维学python之爬虫高级篇(五)scrapy爬取豆瓣电影TOP250
- 1.【python爬虫学习笔记】爬取豆瓣电影top250
- scrapy1.3爬取豆瓣电影top250
- 实践Python的爬虫框架Scrapy来抓取豆瓣电影TOP250
- Scrapy+mongoDB爬取豆瓣TOP250
- python+beautifulsoup爬取豆瓣电影TOP250
- Python爬取豆瓣电影top250
- 用python学习抓取借鉴取豆瓣电影top250