用python学习抓取借鉴取豆瓣电影top250
2017-11-25 14:40
731 查看
今天给大家带来的是用最近学习的python抓取豆瓣上面的top250电影,具体是将电影的title、电影描述(就是导演呀之类的是谁)、电影封面图片、电影的星级、电影评价数目以及电影的一句影评抓取下来,然后在控制台有格式的打印出来。
已经明确了要做的事情,接下来就考虑怎么来做这件事情了,第一步是打开豆瓣电影top250 这个页面,第二步骤是分析网页源代码,找到我们需要爬取的信息的标签,例如电影title的标签等等是什么。第三步就是写代码了,将整个html请求下来,然后解析网页,获取我们需要的信息,利用beautifulsoup进行解析,所有文字信息获取到后,第四步就是开启一个子线程将电影的封面下载下来,并且将其保存在本地。完成这四步我们就算是完成了我们的工作。
首先打开豆瓣电影top250,可以看到电影是按照一个列表呈现出来的,页面最底部也是通过12345酱紫的可以进行翻页查看,但是如何分析页面元素呢,可以用chrome的开发者工具,这可是前端工程师的调试利器呀,在mac上的快捷键组合是option+command键,之后可以看到如下页面
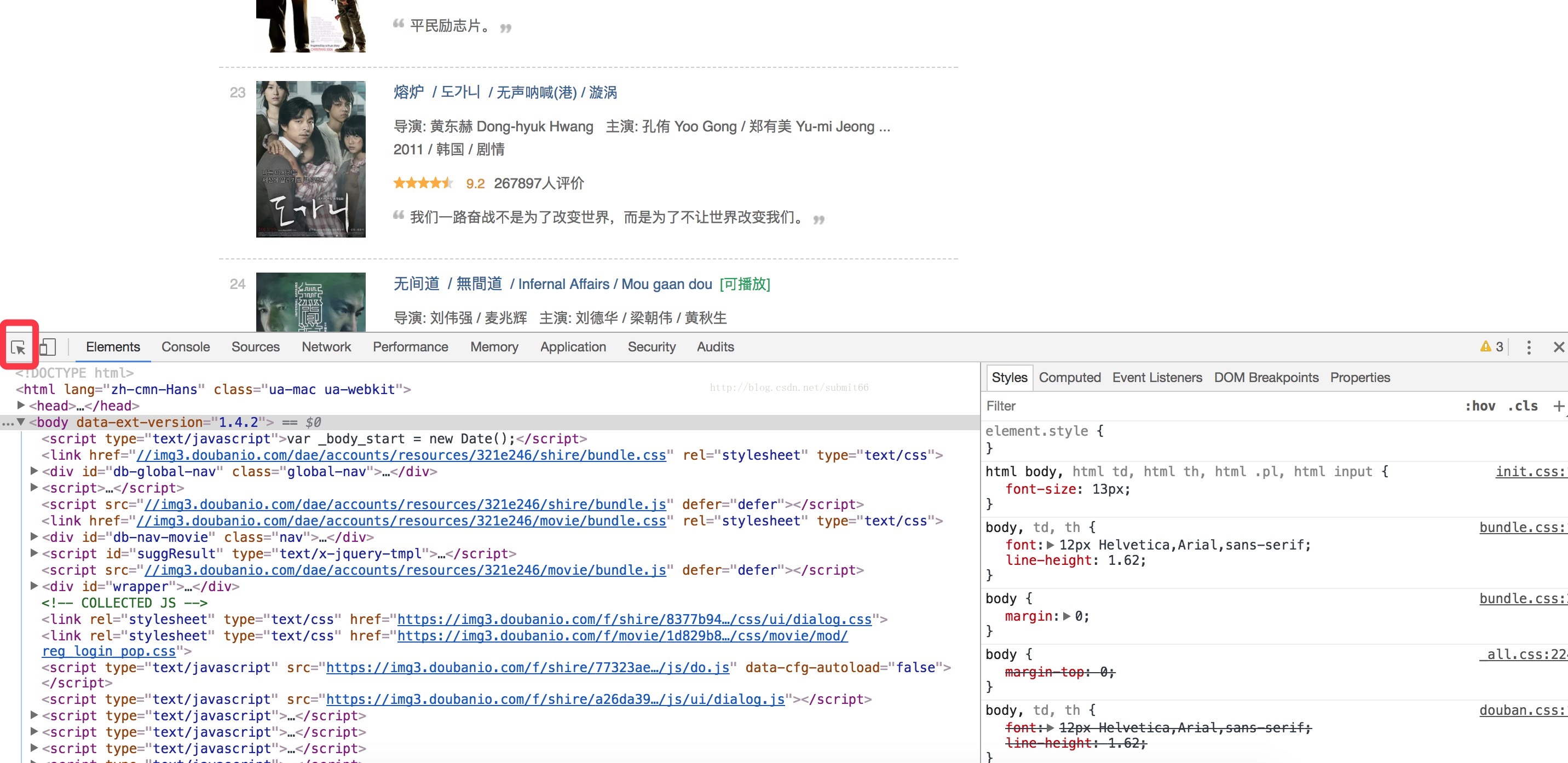
页面下部分就是网页源代码的一些展示,有些同学可能有疑问了,我们怎么找到页面上的元素在代码中对应的标签是什么呢?一种很方便的方式就是点击我图中画圆圈的图标,然后自己鼠标在页面上选中一部分,就会直接定位到具体的地方了,可以自己试下,效果还是很棒的,经过我刚刚说的操作在代码中发现所有列表是放在一个class为gridview的ol标签中的,这个标签中都是li标签,而每一个li就是每一部电影信息的Item,而在这一个个li中就有我们需要的信息,并且每一个li中都是一样子的,每个Item怎么获取信息,解析哪个标签我们算是搞懂了。
我们上面也说了下面是有翻页的,所以只请求一次肯定是不行的,所以肯定需要循环,那我们需要看看下面的翻页标签了,如下图:
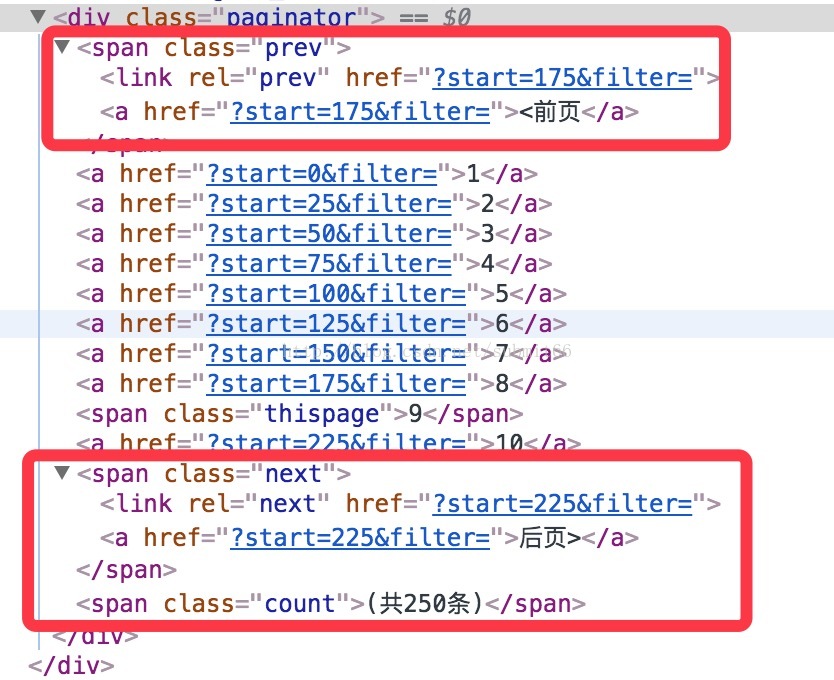
因为我们是在第九页所以在页面上会看到有“前页”和“后页”,但是当你在第十页的时候,后页里面就没有那个link的链接标签了,所以这就可以用来作为我们是否请求到了最后一页的判断条件了,我们也知道就是每页的请求链接都是不同的,但是细心的同学也已经发现了,请求的链接就是那个class为next的span标签里面的link标签的href属性加上跟地址了。至此我们的思路都已经理清楚了,接下来上代码。
代码的细节上标签解析都是用的beautifulsoup也比较简单,就是找好层级关系就好了,然后可以看到我的子线程用的threading而不是thread,原因上面的代码注释中也有说,就是threading开启的派生线程,如果不设置为守护进程,那么在派生线程执行结束之前主线程是不会退出的,能够满足我们的要求,但是如果用了thread,那么主线程不会等待thread执行完毕自己就退出了,所以虽然代码不报错,但是图片却不能下载下来,我刚开始就是用的这行代码“thread.start_new_thread
(downloadPicture, (listPicture,))”,自然是不ok的了。另外需要注意的是无论是start_new_thread方法还是threading.Thread方法,第一个参数都是方法名称,而不是方法的调用,第二个参数一定是一个元组,否则是会报错的哦。
最后代码已经上传githubgithub代码链接。以上就是本次全部内容,有问题欢迎批评指正。特此声明本次爬取仅用于学习使用,不用于任何商业用途。
已经明确了要做的事情,接下来就考虑怎么来做这件事情了,第一步是打开豆瓣电影top250 这个页面,第二步骤是分析网页源代码,找到我们需要爬取的信息的标签,例如电影title的标签等等是什么。第三步就是写代码了,将整个html请求下来,然后解析网页,获取我们需要的信息,利用beautifulsoup进行解析,所有文字信息获取到后,第四步就是开启一个子线程将电影的封面下载下来,并且将其保存在本地。完成这四步我们就算是完成了我们的工作。
首先打开豆瓣电影top250,可以看到电影是按照一个列表呈现出来的,页面最底部也是通过12345酱紫的可以进行翻页查看,但是如何分析页面元素呢,可以用chrome的开发者工具,这可是前端工程师的调试利器呀,在mac上的快捷键组合是option+command键,之后可以看到如下页面
页面下部分就是网页源代码的一些展示,有些同学可能有疑问了,我们怎么找到页面上的元素在代码中对应的标签是什么呢?一种很方便的方式就是点击我图中画圆圈的图标,然后自己鼠标在页面上选中一部分,就会直接定位到具体的地方了,可以自己试下,效果还是很棒的,经过我刚刚说的操作在代码中发现所有列表是放在一个class为gridview的ol标签中的,这个标签中都是li标签,而每一个li就是每一部电影信息的Item,而在这一个个li中就有我们需要的信息,并且每一个li中都是一样子的,每个Item怎么获取信息,解析哪个标签我们算是搞懂了。
我们上面也说了下面是有翻页的,所以只请求一次肯定是不行的,所以肯定需要循环,那我们需要看看下面的翻页标签了,如下图:
因为我们是在第九页所以在页面上会看到有“前页”和“后页”,但是当你在第十页的时候,后页里面就没有那个link的链接标签了,所以这就可以用来作为我们是否请求到了最后一页的判断条件了,我们也知道就是每页的请求链接都是不同的,但是细心的同学也已经发现了,请求的链接就是那个class为next的span标签里面的link标签的href属性加上跟地址了。至此我们的思路都已经理清楚了,接下来上代码。
#!/usr/bin/env python
# encoding: utf-8
'''
爬取豆瓣top250 电影 信息
'''
import requests;
from bs4 import BeautifulSoup;
import os;
import time;
import threading;
'''
定义一个类 属性包含图片的名称以及下载的url
'''
class Picture:
def __init__(self,picName,picSrcUrl):
self.picName = picName;
self.picSrcUrl = picSrcUrl;
'''
下载图片,因为它比较耗时所以将其放在子线程中
'''
def downloadPicture(pictureList):
fileDir = "/Users/aaa/Documents/douban/";
if not os.path.isdir(fileDir):
os.makedirs(fileDir);
for index in range(len(pictureList)):
try:
picture = pictureList[index];
filename = fileDir + picture.picName + ".webp";
file = open(filename, "w");
file.write(requests.get(picture.picSrcUrl, timeout=5).content);
file.close();
except:
print picture.picSrcUrl,'下载失败'
pass
print "爬取耗时:", time.time().__float__()- cuttentTime.__float__() , 's';
param = "";# 后面分页时候拼接的参数
cuttentTime = time.time();
listPicture = [];
while True:
# 请求豆瓣top250 电影的url
baseUrl = 'https://movie.douban.com/top250' + param;
myResponse = requests.get(baseUrl, timeout=5);
myResponse.raise_for_status();
responseString = myResponse.text;
soup = BeautifulSoup(responseString, 'lxml');
olArticle = soup.find('ol', class_='grid_view');# 获取存储文章的ol对象
lilist = divItem = olArticle.find_all('li');
for index in range(len(lilist)):
# 下面是关于电影的一些信息文字信息
divItemInfo = lilist[index].find('div', class_='info');
divBd = divItemInfo.find('div', class_='bd');
titleList = divItemInfo.find('div', class_='hd').a.find_all('span');
stringTitle = '';
# 影片的大致描述,导演、演员以及上映时间等
strContentDescription = divBd.p.getText();
# 影片的星级
strRatingStar = divBd.div.find_all('span')[1].getText();
# 影片的评价数目
strComment = divBd.div.find_all('span')[3].getText();
# 对于影片的一句话总结(有的没有影评所以要判空)
if divBd.find('p', class_='quote'):
strQuote = divBd.find('p', class_='quote').span.getText();
# 进行电影名称的拼接,因为电影在不同的地方上映可能名字不同
for indexTitle in range(len(titleList)):
stringTitle = stringTitle + titleList[indexTitle].getText();
print "电影名称:"+stringTitle.encode('utf8')\
+"\n电影星级:"+strRatingStar.encode('utf8')\
+"\n电影评价数目:"+strComment.encode('utf8')\
+"\n电影一句话总结:"+strQuote.encode('utf8')\
+"\n电影大致内容信息:"+strContentDescription.encode('utf8').strip()+"\n";
divItemPic = lilist[index].find('div', class_='pic');
listPicture.append(Picture(divItemPic.a.img.get('alt'),divItemPic.a.img.get('src')));
print "\n";
divpaginator = soup.find('div', class_='paginator');# 获取底部分页的导航条
spanNext = divpaginator.find('span', class_='next');# 获取后页
# 如果后一页没有link,那么意味着已经到了最后一页了,所以需要跳出循环
if not spanNext.link:
break;
# 获取link的某个属性,可以使用get方法
param = spanNext.link.get('href');
'''
在所有数据内容爬取完毕后开始一个新的线程下载图片,这里还非得用threading模块了,因为它开启的派生线程在运行时候,主线程不会退出,直至派生线程执行完毕
但是如果派生线程被设置为守护线程,即设置setDaemon为true的话,主线程退出派生线程也就不执行了(但是这个不是我们想要的)
如果直接使用thread模块就会存在主线程提前退出派生线程无法执行完毕,导致下载失败的情况
'''
try:
# 需要注意的一点是 第一个参数是方法名,第二个参数一定是一个tuple元组,否则均会报错
threadDownload = threading.Thread(target=downloadPicture, args=(listPicture,));
threadDownload.setDaemon(False)
threadDownload.start();
except:
print "Error: unable to start thread" 以上就是代码,注释写的还是比较清楚的。代码就是首先循环将每一页上面的每一条电影信息的名称等文字信息先抓取下来,然后将电影的封面url和电影的名称作为类Picture的两个属性存起来,然后这些对象又存储在listPicture这个数组中,当所有的文字信息都抓取完毕时候,开启新的线程调用downloadPicture方法传入listPicture数组,循环将图片下载下来并且存储到本地。其实最初我没有将图片下载单拉出来,最初图片也是随着每一条电影信息下载并且存储的,但是想到图片的下载是一个耗时的过程且失败的可能性还是挺高的,所以不能因为某张图片的下载失败影响了其他文字信息的获取,所以综上所有原因就将所有的图片下载放在一个子线程中单独执行了。代码的细节上标签解析都是用的beautifulsoup也比较简单,就是找好层级关系就好了,然后可以看到我的子线程用的threading而不是thread,原因上面的代码注释中也有说,就是threading开启的派生线程,如果不设置为守护进程,那么在派生线程执行结束之前主线程是不会退出的,能够满足我们的要求,但是如果用了thread,那么主线程不会等待thread执行完毕自己就退出了,所以虽然代码不报错,但是图片却不能下载下来,我刚开始就是用的这行代码“thread.start_new_thread
(downloadPicture, (listPicture,))”,自然是不ok的了。另外需要注意的是无论是start_new_thread方法还是threading.Thread方法,第一个参数都是方法名称,而不是方法的调用,第二个参数一定是一个元组,否则是会报错的哦。
最后代码已经上传githubgithub代码链接。以上就是本次全部内容,有问题欢迎批评指正。特此声明本次爬取仅用于学习使用,不用于任何商业用途。

相关文章推荐
- 实践Python的爬虫框架Scrapy来抓取豆瓣电影TOP250
- 实践Python的爬虫框架Scrapy来抓取豆瓣电影TOP250
- 1.【python爬虫学习笔记】爬取豆瓣电影top250
- 小猪的Python学习之旅 —— 14.项目实战:抓取豆瓣音乐Top 250数据存到Excel中
- 萌新的Python学习日记 - 爬虫无影 - 爬取豆瓣电影top250并入库:豆瓣电影top250
- Python爬虫----抓取豆瓣电影Top250
- Python爬虫初学(1)豆瓣电影top250评论数
- Python爬虫豆瓣电影top250
- 爬取豆瓣电影top250(python3)
- Python 采用Scrapy爬虫框架爬取豆瓣电影top250
- 使用Python3.5爬取豆瓣电影Top250
- xpath方法抓取豆瓣电影top250
- [python爬虫入门]爬取豆瓣电影排行榜top250
- python3[爬虫基础入门实战] 爬取豆瓣电影排行top250
- Python爬虫实战——豆瓣电影Top250
- Python+Scrapy 爬取豆瓣电影排行榜Top250
- (7)Python爬虫——爬取豆瓣电影Top250
- Python爬虫,用于抓取豆瓣电影Top前100的电影的名称
- 简单爬虫学习---爬取豆瓣电影top250
- 运维学python之爬虫高级篇(五)scrapy爬取豆瓣电影TOP250