python爬虫日志(10)多进程爬取豆瓣top250
2018-07-29 11:42
701 查看
又是一个实践,这次准备爬取豆瓣电影top250,并把数据保存到mysql中,虽说数据量不大,对速度没有太大的要求,不过为了练习多进程爬虫,还是用多进程的方法写了这个爬虫。
多进程有什么用呢?在数据量少的时候,用不用多进程问题不大,但当数据量大的时候,多进程在效率提升上的作用就非常突出了。进程每多一个,速度就提升一倍,比如我的电脑是4核的,默认开4个进程(当然可以自己设置,但不宜过多),那么效率就能提升四倍。下面来看代码吧。
成果
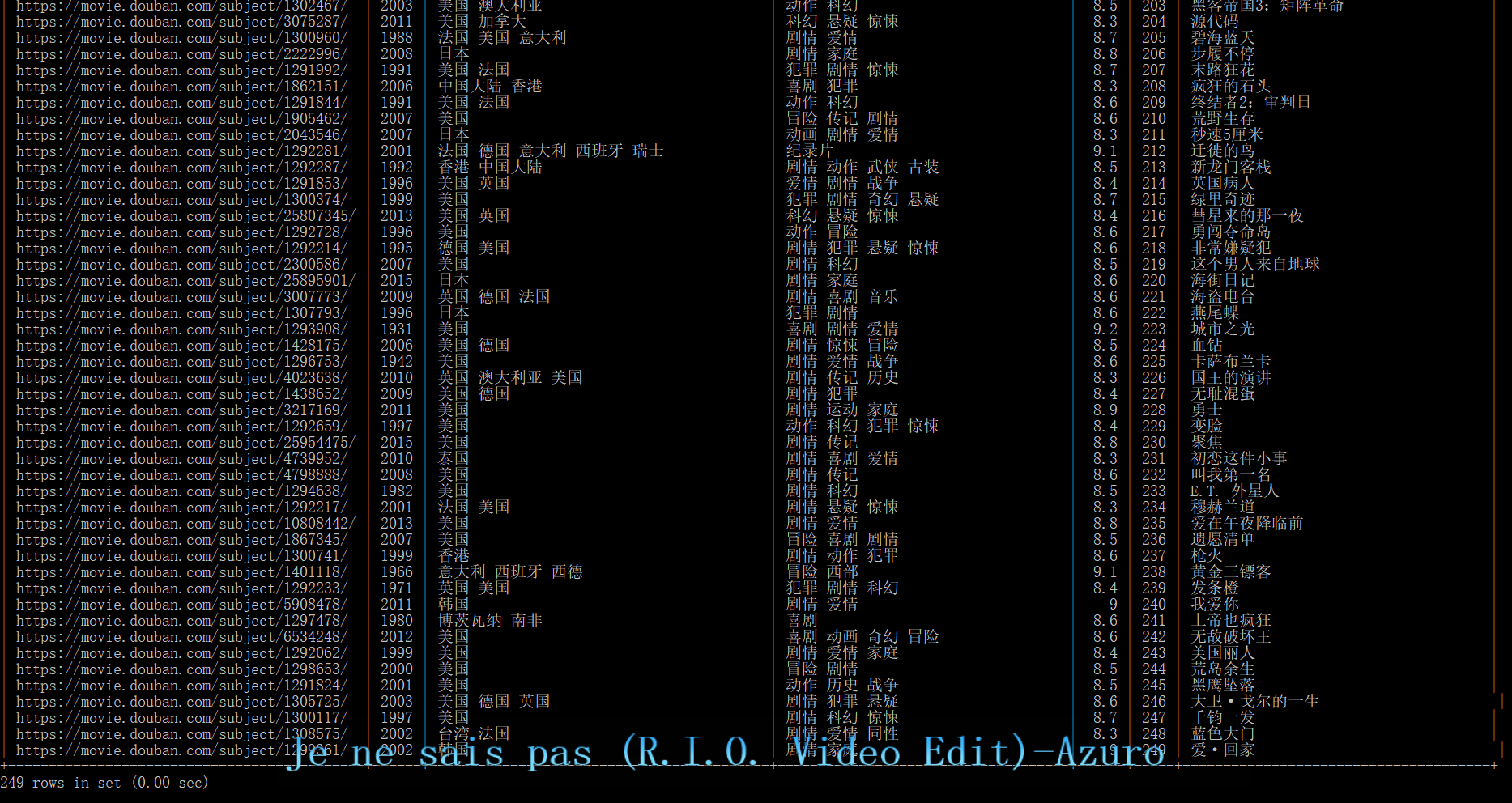
当然因为有一条数据比较特殊所以少了一条。少的那条是
可以看到这里有多个时间,并且后面有括号里的多余的内容,不过没关系,因为只有一条比较特殊,单独处理下就好了。
多进程有什么用呢?在数据量少的时候,用不用多进程问题不大,但当数据量大的时候,多进程在效率提升上的作用就非常突出了。进程每多一个,速度就提升一倍,比如我的电脑是4核的,默认开4个进程(当然可以自己设置,但不宜过多),那么效率就能提升四倍。下面来看代码吧。
from bs4 import BeautifulSoup
import requests, get_proxy, pymysql
from multiprocessing import Pool #多进程需要用到的库,pool可以称为进程池
douban_urls = ['https://movie.douban.com/top250?start={}&filter='.format(i) for i in range(0, 250, 25)]
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36"}
proxy_list = get_proxy.get_ip_list() #爬取代理的函数可以看我的上一篇日志
db = pymysql.connect('localhost', 'root', '', 'doubantop250') #链接数据库
cursor = db.cursor()
def get_info(douban_url):
proxies = get_proxy.get_random_ip(proxy_list) #设置代理,返回一个字典
wb_data = requests.get(douban_url, headers=headers, proxies=proxies)
soup = BeautifulSoup(wb_data.text, 'lxml')
item_list = soup.find_all('div', 'item')
for item in item_list:
link = item.select('div.hd > a')[0].get('href')
title = item.select('div.hd > a > span:nth-of-type(1)')[0].text
info = item.select('.info .bd p:nth-of-type(1)')[0].text.split('/')
year = info[-3].split()[-1]
country = info[-2].strip()
types = info[-1].strip()
star = item.select('.rating_num')[0].text
db.ping(reconnect=True) #不知道为什么使用多进程,总会发生InterfaceError (0, '')这个错误,所以每次执行语句之前先确保连接正常,就是Ping一下
sql = '''INSERT INTO top250(link,title,year,country,type,star) VALUES("{}","{}",{},"{}","{}",{})'''.format(link, title, year, country, types, star)
try:
cursor.execute(sql)
db.commit() #这个函数用于同步数据库数据,如果不想因为可能引发一个错误,中止程序运行,使得前面抓的数据没有记录到数据库中就每次做修改后调用一下
except pymysql.err.ProgrammingError:
print(sql, '\n', douban_url) #这里有一条数据比较特殊,所以会引发语法错误,没关系先跳过
if __name__ == '__main__': #这条语句是必须的,至于为什么,可以不写这行,直接运行下面两行看看,ide会有提示说必须在这下面运行,所以要加上。其实这个__name__ == '__main__'就是证明程序是独自运行,而不是被其他程序调用而运行的,意思就像是我就是我自己。多进程就得在这种状态下才可以进行。
pool = Pool() #可以用Pool(processes=)来设置进程数
pool.map(get_info, douban_urls) #map这个函数,可以将后面的列表里的元素,一个个作为参数放到前面的函数中运行,有个约定函数在map中作为参数可以不写括号
db.close()成果
当然因为有一条数据比较特殊所以少了一条。少的那条是
可以看到这里有多个时间,并且后面有括号里的多余的内容,不过没关系,因为只有一条比较特殊,单独处理下就好了。

相关文章推荐
- 运维学python之爬虫高级篇(五)scrapy爬取豆瓣电影TOP250
- [Python爬虫]2.豆瓣图书Top250
- python第一只爬虫:爬豆瓣top250
- Python爬虫——豆瓣电影Top250
- Python爬虫豆瓣电影top250
- [python爬虫] BeautifulSoup和Selenium对比爬取豆瓣Top250电影信息
- Python爬虫(二)—— 再探豆瓣Top250
- python 爬虫 保存豆瓣TOP250电影海报及修改名称
- Python爬虫----抓取豆瓣电影Top250
- 简单的python爬虫爬豆瓣图书TOP250
- 实践Python的爬虫框架Scrapy来抓取豆瓣电影TOP250
- Python爬虫小案例:豆瓣电影TOP250
- Python爬虫实战——豆瓣电影top250
- [Python/爬虫]利用xpath爬取豆瓣电影top250
- Python 采用Scrapy爬虫框架爬取豆瓣电影top250
- Python爬虫初学(1)豆瓣电影top250评论数
- [python爬虫入门]爬取豆瓣电影排行榜top250
- python爬虫 Scrapy2-- 爬取豆瓣电影TOP250
- python爬虫实现获取豆瓣图书的top250的信息-beautifulsoup实现
- python 爬虫实战(一)爬取豆瓣图书top250