Python中关于URL的处理(基于Python2.7版本)
2018-07-15 09:27
232 查看
版权声明:请大家使用时记得显示原创的博主哦!! https://blog.csdn.net/qq_33472765/article/details/81050209
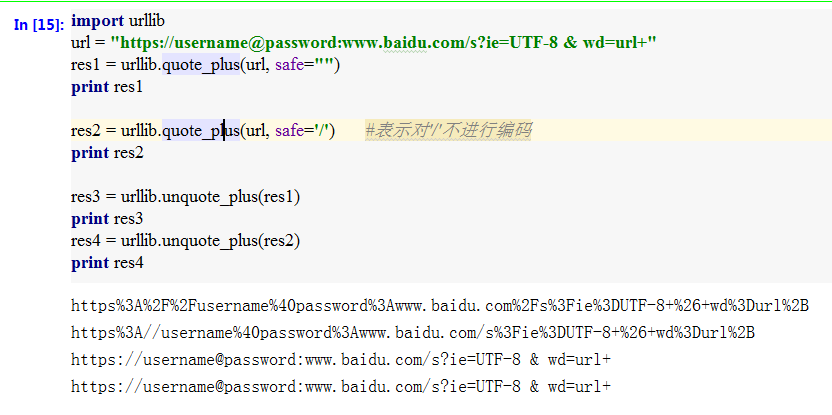
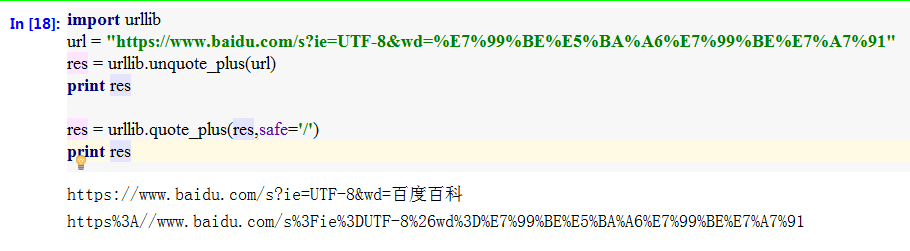
urllib模块的quote_plus()方法实现对url的编码,包括对中文的编码;unquote_plus()方法实现对url的解码,包括对中文的解码。
参考官方文档:https://docs.python.org/3/library/urllib.html点击打开链接
1、 完整的url语法格式:
协议://用户名@密码:子域名.域名.顶级域名:端口号/目录/文件名.文件后缀?参数=值#标识
2 、urlparse模块对url的处理方法
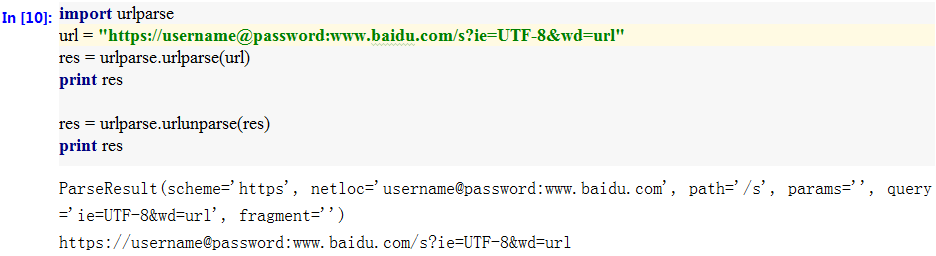
urlparse模块对url的主要处理方法有:urljoin/urlsplit/urlunsplit/urlparse等。该模块对url的定义采用六元组的形式:schema://netloc/path;parameters?query#fragment。其中,netloc包含下表的后4个属性
urlparse()
利用urlparse()方法对url进行解析,返回六元组;urlunparse()对六元组进行组合
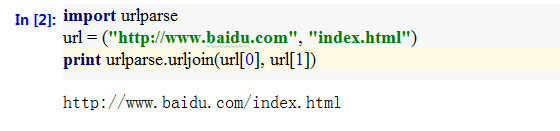
- urljoin()
利用urljoin()方法对绝对url地址与相对url地址进行拼合
主要使用urljoin()比较常用——给出以下示例:
>>>from urllib.parse import urljoin
>>> urljoin("http://www.chachabei.com/folder/currentpage.html", "anotherpage.html")
'http://www.chachabei.com/folder/anotherpage.html'
>>> urljoin("http://www.chachabei.com/folder/currentpage.html", "/anotherpage.html")
'http://www.chachabei.com/anotherpage.html'
>>> urljoin("http://www.chachabei.com/folder/currentpage.html", "folder2/anotherpage.html")
'http://www.chachabei.com/folder/folder2/anotherpage.html'
>>> urljoin("http://www.chachabei.com/folder/currentpage.html", "/folder2/anotherpage.html")
'http://www.chachabei.com/folder2/anotherpage.html'
>>> urljoin("http://www.chachabei.com/abc/folder/currentpage.html", "/folder2/anotherpage.html")
'http://www.chachabei.com/folder2/anotherpage.html'
>>> urljoin("http://www.chachabei.com/abc/folder/currentpage.html", "../anotherpage.html")
'http://www.chachabei.com/abc/anotherpage.html'- urlsplit()
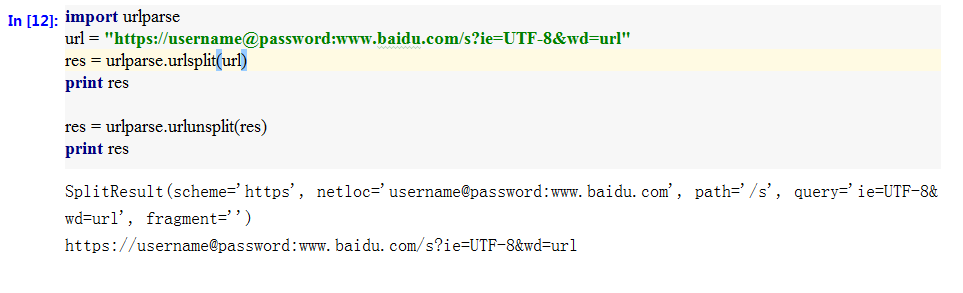
利用urlsplit()方法可以对URL进行分解;与urlparse()相比,urlsplit()函数返回一个五元组,没有parameter参数。
相应的,urlunsplit()方法可以对urlsplit()分解的五元组进行合并。两种方法组合在一起,可以对URL进行有效地格式化,特殊字符在此过程中得到转换。
urllib模块的quote_plus()方法实现对url的编码,包括对中文的编码;unquote_plus()方法实现对url的解码,包括对中文的解码。

相关文章推荐
- 关于python的url处理
- 基于python 爬虫爬到含空格的url的处理方法
- Python字符串处理(版本2.7)-学习笔记
- python2.7和python3.4网络编程处理二进制数据区别
- 修改默认的pip版本为对应python2.7
- Python:关于3.0版本后的一些问题
- 关于python的bottle框架跨域请求报错问题的处理方法
- 关于Python2.0版本与3.0版本中类的区别
- 【脚本语言系列】关于Python结构化文本文件处理HTML,你需要知道的事
- Centos5.x下升级python到python2.7版本教程
- 关于iOS各个版本的icon处理
- python 中关于struct处理二进制数据
- Python 2.7中文显示与处理
- mysql 5.5和5.6版本关于timestamp插null和0的处理
- mac python从2.7版本升级至3.6
- 基于Win7、Python2.7安装一系列机器学习工具
- 关于python类继承中metaclass conflict的处理
- Python 2.7中文显示与处理方法
- Python2.7安装Scrapy错误处理
- 关于iOS中webView中url特殊字符处理