如何在ubuntu上安装nvidia-docker同时与宿主共享GPU cuda加速
2018-05-19 15:43
1016 查看
1.去github网站下载nvdia-docker
下载和安装nvdia-docker的命令是
但是nvdia-docker的安装依赖于docker-ce或者docker-ee,所以必须先满足依赖条件,而且对docker-ce和docker-ee也有版本的要求。
2.安装docker-ce
(1)查询docker-ce的版本
(2)安装最新版本的docker-ce
3.正式安装nvdia-docker
docker tensorflow的镜像官网为https://hub.docker.com/r/tensorflow/tensorflow/,首先按照官方教程安装nvidia-docker2,之后的tensorflow-gpu镜像都需要nvidia-docker来启动,或者docker run --runtime=nvidia,当然这样就足够用了,如果你想用docker取代nvidia-docker可以修改/etc/docker/daemon.json为如下所示,即在第一行加入"default-runtime": "nvidia",这样就可以直接用docker取代nvidia-docker了
在这里需要注意reload一下
下载成功后执行:安装配置成功之后选择Tags标签可以看到不同tag的tensorflow镜像,官方实例代码选择的tag为latest-gpu的镜像,可以根据自己的需要下载镜像,博主选择的是1.8.0-devel-gpu-py3的镜像,这个镜像包含tensorflow-gpu=1.8.0版本,并且包含bazel等开发环境可以编译tensorflow的源代码。即此镜像既可以用于训练模型,又可以用来学习tensorflow源码。执行:
docker images
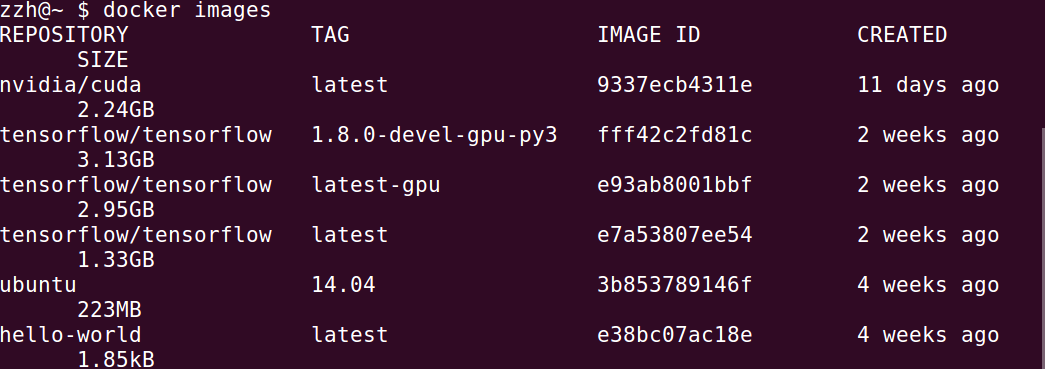
可以查看下载的镜像,如下图所示:
可以看到有一个TAG名为1.8.0-devel-gpu-py3的镜像,证明下载成功。
2.启动容器
如果在前面配置了"default-runtime": "nvidia",那么执行:
其中docker run的参数含义如下:
(1)--rm 退出容器清除数据
(2)-it 启动交互式终端
(3)-v 挂在目录
(4)--name 容器名称
3.在容器中训练cifar10
cifar10教程:https://www.tensorflow.org/tutorials/deep_cnn
在本机某一路径下创建好项目,执行脚本后可以看到训练的速度,如下图所示:
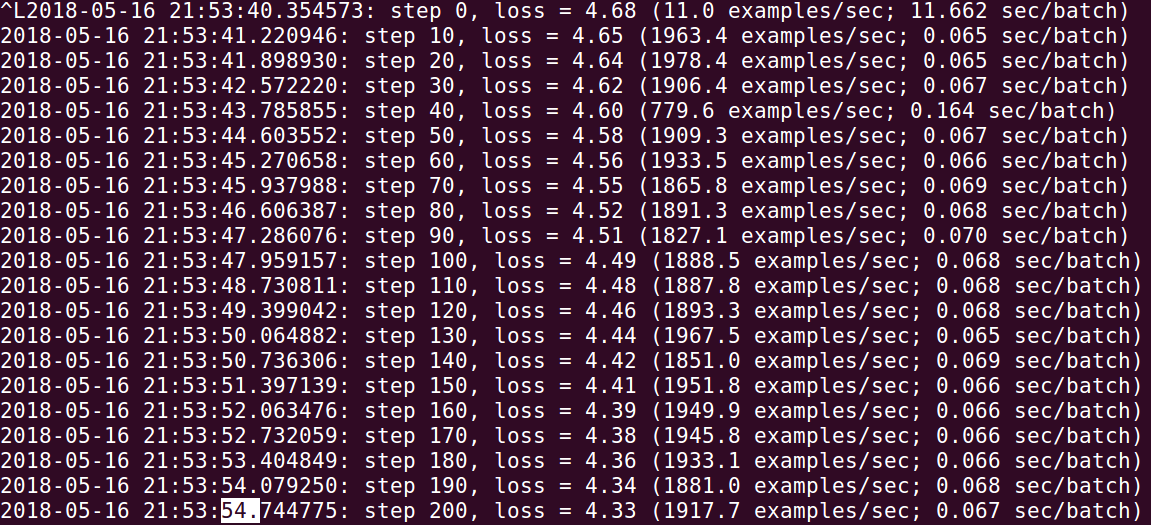
可以看到,step 0到200的时间是13.52秒。
将这个目录挂在到容器中,在容器中训练,速度如下图所示:
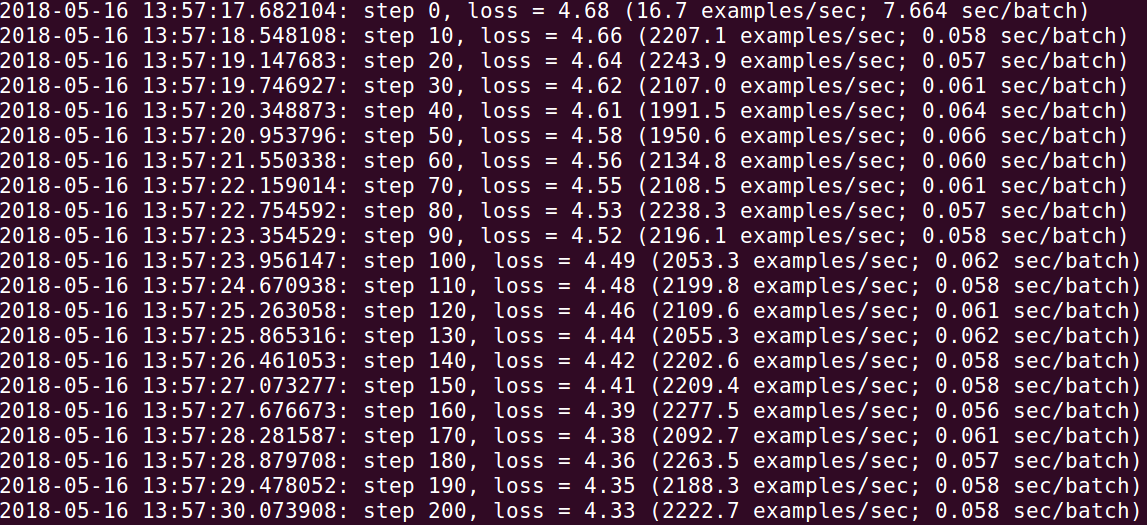
可以看到,step 0到200的时间是12.39秒(快了的原因是容器中的是tensorflow1.8,而本机由于驱动版本的原因只能安装tensorflow1.4)
可以看到性能基本是无损的,并且由于本机显卡驱动版本低不能安装高版本的tf问题也能通过docker解决。看看,docker是不是屌炸天,性能居然基本无损,真的值得研究研究!!!
4.其他docker使用技巧
(1)通过[docker commit CONTAINER_ID newImageName]保存对镜像的修改,CONTAINER_ID可以通过docker ps查看
(2)通过[docker save -o 文件名 镜像名] 将镜像存储至磁盘,例如docker save -o tensorflow.tar tensorflow/tensorflow:1.8.0-devel-gpu-py3
(3)通过[docker load --input 文件名] 从磁盘导入镜像,例如docker load --input tensorflow.tar
(4)容器一旦退出里面的信息就都会被清除,若不想保存修改又不想丢失信息,那么可以CTRL+P+Q让容器在后台运行,然后通过docker attach CONTAINER_ID重新连接进容器
下载和安装nvdia-docker的命令是
# If you have nvidia-docker 1.0 installed: we need to remove it and all existing GPU containers
docker volume ls -q -f driver=nvidia-docker | xargs -r -I{} -n1 docker ps -q -a -f volume={} | xargs -r docker rm -f
sudo apt-get purge -y nvidia-docker
# Add the package repositories
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | \
sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64/nvidia-docker.list | \
sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update
# Install nvidia-docker2 and reload the Docker daemon configuration
sudo apt-get install -y nvidia-docker2
sudo pkill -SIGHUP dockerd
# Test nvidia-smi with the latest official CUDA image
docker run --runtime=nvidia --rm nvidia/cuda nvidia-smi但是nvdia-docker的安装依赖于docker-ce或者docker-ee,所以必须先满足依赖条件,而且对docker-ce和docker-ee也有版本的要求。
# If you have nvidia-docker 1.0 installed: we need to remove it and all existing GPU containers
docker volume ls -q -f driver=nvidia-docker | xargs -r -I{} -n1 docker ps -q -a -f volume={} | xargs -r docker rm -f
sudo apt-get purge -y nvidia-docker
# Add the package repositories
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | \
sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64/nvidia-docker.list | \
sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update
# Install nvidia-docker2 and reload the Docker daemon configuration
sudo apt-get install -y nvidia-docker2
sudo pkill -SIGHUP dockerd
# Test nvidia-smi with the latest official CUDA image
docker run --runtime=nvidia --rm nvidia/cuda nvidia-smi2.安装docker-ce
(1)查询docker-ce的版本
apt-cache madison docker-ce docker-ce | 17.12.0~ce-0~ubuntu | https://download.docker.com/linux/ubuntu xenial/stable amd64 Packages
(2)安装最新版本的docker-ce
sudo apt-get install docker-ce=17.12.0~ce-0~ubuntu 正在读取软件包列表... 完成 正在分析软件包的依赖关系树 正在读取状态信息... 完成 推荐安装的软件包: aufs-tools 下列软件包将被【降级】: docker-ce 升级了 0 个软件包,新安装了 0 个软件包,降级了 1 个软件包,要卸载 0 个软件包,有 463 个软件包未被升级。 需要下载 30.2 MB 的软件包。 解压缩后将会空出 17.3 MB 的空间。 您希望继续执行吗? [Y/n] Y 获取:1 https://download.docker.com/linux/ubuntu/ trusty/edge docker-ce amd64 17.12.0~ce-0~ubuntu [30.2 MB] 下载 30.2 MB,耗时 52秒 (574 kB/s) dpkg:警告:即将把 docker-ce 从 18.01.0~ce-0~ubuntu 降级到 17.12.0~ce-0~ubuntu (正在读取数据库 ... 系统当前共安装有 302951 个文件和目录。) 正准备解包 .../docker-ce_17.12.0~ce-0~ubuntu_amd64.deb ... 正在将 docker-ce (17.12.0~ce-0~ubuntu) 解包到 (18.01.0~ce-0~ubuntu) 上 ... 正在处理用于 ureadahead (0.100.0-16) 的触发器 ... 正在处理用于 man-db (2.6.7.1-1ubuntu1) 的触发器 ... 正在设置 docker-ce (17.12.0~ce-0~ubuntu) ... 正在安装新版本的配置文件 /etc/bash_completion.d/docker ... docker start/running, process 17636
3.正式安装nvdia-docker
maya@maya-g450:~$ sudo apt-get install -y nvidia-docker2 正在读取软件包列表... 完成 正在分析软件包的依赖关系树 正在读取状态信息... 完成 将会安装下列额外的软件包: libnvidia-container-tools libnvidia-container1 nvidia-container-runtime 下列【新】软件包将被安装: libnvidia-container-tools libnvidia-container1 nvidia-container-runtime nvidia-docker2 升级了 0 个软件包,新安装了 4 个软件包,要卸载 0 个软件包,有 464 个软件包未被升级。 需要下载 2,044 kB 的软件包。 解压缩后会消耗掉 9,755 kB 的额外空间。 获取:1 https://nvidia.github.io/libnvidia-container/ubuntu16.04/amd64/ libnvidia-container1 1.0.0~alpha.3-1 [54.3 kB] 获取:2 https://nvidia.github.io/libnvidia-container/ubuntu16.04/amd64/ libnvidia-container-tools 1.0.0~alpha.3-1 [14.5 kB] 获取:3 https://nvidia.github.io/nvidia-container-runtime/ubuntu16.04/amd64/ nvidia-container-runtime 1.1.1+docker17.12.0-1 [1,972 kB] 获取:4 https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64/ nvidia-docker2 2.0.2+docker17.12.0-1 [2,782 B] 下载 2,044 kB,耗时 17秒 (120 kB/s) 正在选中未选择的软件包 libnvidia-container1:amd64。 (正在读取数据库 ... 系统当前共安装有 302951 个文件和目录。) 正准备解包 .../libnvidia-container1_1.0.0~alpha.3-1_amd64.deb ... 正在解包 libnvidia-container1:amd64 (1.0.0~alpha.3-1) ... 正在选中未选择的软件包 libnvidia-container-tools。 正准备解包 .../libnvidia-container-tools_1.0.0~alpha.3-1_amd64.deb ... 正在解包 libnvidia-container-tools (1.0.0~alpha.3-1) ... 正在选中未选择的软件包 nvidia-container-runtime。 正准备解包 .../nvidia-container-runtime_1.1.1+docker17.12.0-1_amd64.deb ... 正在解包 nvidia-container-runtime (1.1.1+docker17.12.0-1) ... 正在选中未选择的软件包 nvidia-docker2。 正准备解包 .../nvidia-docker2_2.0.2+docker17.12.0-1_all.deb ... 正在解包 nvidia-docker2 (2.0.2+docker17.12.0-1) ... 正在处理用于 libc-bin (2.19-0ubuntu6.9) 的触发器 ... 正在设置 libnvidia-container1:amd64 (1.0.0~alpha.3-1) ... 正在设置 libnvidia-container-tools (1.0.0~alpha.3-1) ... 正在设置 nvidia-container-runtime (1.1.1+docker17.12.0-1) ... 正在设置 nvidia-docker2 (2.0.2+docker17.12.0-1) ... 正在处理用于 libc-bin (2.19-0ubuntu6.9) 的触发器 ...
docker tensorflow的镜像官网为https://hub.docker.com/r/tensorflow/tensorflow/,首先按照官方教程安装nvidia-docker2,之后的tensorflow-gpu镜像都需要nvidia-docker来启动,或者docker run --runtime=nvidia,当然这样就足够用了,如果你想用docker取代nvidia-docker可以修改/etc/docker/daemon.json为如下所示,即在第一行加入"default-runtime": "nvidia",这样就可以直接用docker取代nvidia-docker了
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}在这里需要注意reload一下
sudo systemctl daemon-reload sudo systemctl restart docker
docker pull tensorflow/tensorflow:1.8.0-devel-gpu-py3
下载成功后执行:安装配置成功之后选择Tags标签可以看到不同tag的tensorflow镜像,官方实例代码选择的tag为latest-gpu的镜像,可以根据自己的需要下载镜像,博主选择的是1.8.0-devel-gpu-py3的镜像,这个镜像包含tensorflow-gpu=1.8.0版本,并且包含bazel等开发环境可以编译tensorflow的源代码。即此镜像既可以用于训练模型,又可以用来学习tensorflow源码。执行:
docker images
可以查看下载的镜像,如下图所示:
可以看到有一个TAG名为1.8.0-devel-gpu-py3的镜像,证明下载成功。
2.启动容器
如果在前面配置了"default-runtime": "nvidia",那么执行:
docker run --rm -it -v /home/zzh/:/root/tensorflow --name zzh tensorflow/tensorflow:1.8.0-devel-gpu-py3 没有配置则可以执行: nvidia-docker run --rm -it -v /home/zzh/:/root/tensorflow --name zzh tensorflow/tensorflow:1.8.0-devel-gpu-py3 或者执行: docker run --runtime=nvidia --rm -it -v /home/zzh/:/root/tensorflow --name zzh tensorflow/tensorflow:1.8.0-devel-gpu-py3
其中docker run的参数含义如下:
(1)--rm 退出容器清除数据
(2)-it 启动交互式终端
(3)-v 挂在目录
(4)--name 容器名称
3.在容器中训练cifar10
cifar10教程:https://www.tensorflow.org/tutorials/deep_cnn
在本机某一路径下创建好项目,执行脚本后可以看到训练的速度,如下图所示:
可以看到,step 0到200的时间是13.52秒。
将这个目录挂在到容器中,在容器中训练,速度如下图所示:
可以看到,step 0到200的时间是12.39秒(快了的原因是容器中的是tensorflow1.8,而本机由于驱动版本的原因只能安装tensorflow1.4)
可以看到性能基本是无损的,并且由于本机显卡驱动版本低不能安装高版本的tf问题也能通过docker解决。看看,docker是不是屌炸天,性能居然基本无损,真的值得研究研究!!!
4.其他docker使用技巧
(1)通过[docker commit CONTAINER_ID newImageName]保存对镜像的修改,CONTAINER_ID可以通过docker ps查看
(2)通过[docker save -o 文件名 镜像名] 将镜像存储至磁盘,例如docker save -o tensorflow.tar tensorflow/tensorflow:1.8.0-devel-gpu-py3
(3)通过[docker load --input 文件名] 从磁盘导入镜像,例如docker load --input tensorflow.tar
(4)容器一旦退出里面的信息就都会被清除,若不想保存修改又不想丢失信息,那么可以CTRL+P+Q让容器在后台运行,然后通过docker attach CONTAINER_ID重新连接进容器

相关文章推荐
- Ubuntu 16.04 LTS 安装 Cuda 配置 GPU加速,不断在登录界面循环,如何解决?
- 使用GPU Docker:Nvidia-Docker进行人工智能学习 之Ubuntu安装
- pytorch-0.2成功调用GPU:ubuntu16.04,Nvidia驱动安装以及最新cuda9.0与cudnnV7.0配置
- 双显卡 ubuntu16.04 安装 NVIDIA驱动 + CUDA + cuDNN + tensorflow-gpu + keras
- 【Docker】在ubuntu14.04镜像上安装GPU显卡驱动, CUDA和CUDNN
- Ubuntu17.04+Nvidia GT 640LE+CUDA9.0+cuDNN7.05+Tensorflow1.5r0(GPU)+Anaconda5.01(python3.6)安装
- Ubuntu16.04安装cuda8.0,cudnn6.0,并在conda里安tensorflow1.3(与cuda8.0匹配),pycharm的gpu加速环境变量配置
- 如何在k8s集群中安装nvidia、cuda并使用GPU进行训练
- 【Linux】【Docker】CentOS6.9主机上Docker Ubuntu14.04系统安装CUDA问题Module nvidia-uvm not found
- Ubuntu 16.04安装CUDA9+Docker CE+NVIDIA-Docker+TensorFlow/XGBoost
- ubuntu 15 安装cuda,开启GPU加速
- 如何在ubuntu14.04上安装nvidia-docker
- Ubuntu 16.04lts 安装NVIDIA 私有驱动、cuda、cudnn、tensorflow-gpu等问题
- Ubuntu 16.04安装CUDA9+Docker CE+NVIDIA-Docker+TensorFlow/XGBoost
- [置顶] Tensorflow GPU安装指南 (Ubuntu 16.04 anaconda cuda8.0 cuDNN6.0)
- Ubuntu16.04下安装Cuda8.0+Caffe+TensorFlow-gpu+Pycharm过程(Simple)
- Installing Nvidia CUDA on Ubuntu 14.04 for Linux GPU Computing
- ubuntu16.04安装+cuda8.0+cudnn5.1+MXNET gpu版本安装+tensorflow gpu版本安装+chainerGPU版本安装
- 如何在Ubuntu13.10中安装最新版的NVIDIA 331.20驱动
- ubuntu16.04上安装CUDA8.0 + cuDNN v6 + tensorflow-gpu1.4