python爬虫初级,requests基本用法
2018-04-10 16:52
726 查看
1,requests的作用: 发送网络请求,返回响应数据
2,那为什么使用requests,而不是urllib? 1,requests的底层实现就是urllib 2,requests在python2和python3中通用,方法完全相同 3,requests简单易用 4,requests能够自动帮助我们解压网页内容3,使用方法举例 使用终端打开ipython3
b,获取百度首页源码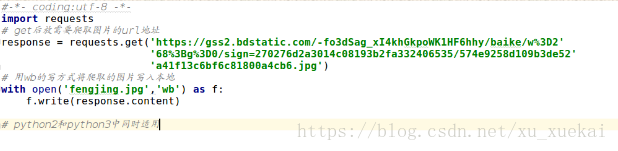
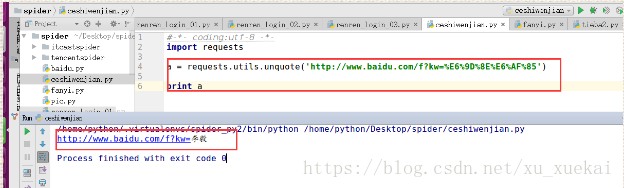
7,requests实现url地址的编码requests.utils.unquote(url编码后的地址)
2,那为什么使用requests,而不是urllib? 1,requests的底层实现就是urllib 2,requests在python2和python3中通用,方法完全相同 3,requests简单易用 4,requests能够自动帮助我们解压网页内容3,使用方法举例 使用终端打开ipython3
a,导入requests:
b,获取百度首页源码

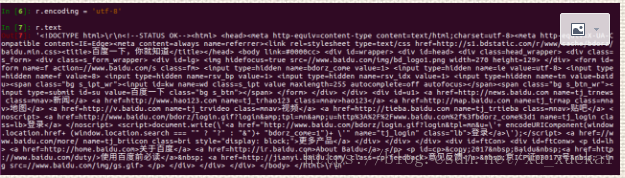
这时候我们会得到一个r,这个r其实就是百度返回的一个对象,我们需要把r变成字符串展示出来。两种方法:一,使用r.text
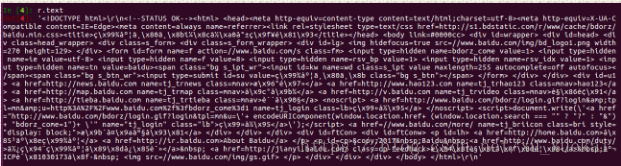
可以看出,内容中有乱码,并不能正常展示,这是因为我们在使用r.text的时候,该方法会自动猜测编码方式并解码,所以并不能准确的解码。如何解决:使用r.encoding可以查看编码方式
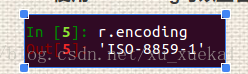
那么我们制定r.encoding的编码方式便可以解决问题。例:
二,另外一种方法就是使用r.content:如图:

我们使用r.content所获得的是一个bytes原生的二进制的数据然后使用r.content.decode()便可以得到我们想要的数据:

4,另外,怎么判断r.text中,这个text是r的属性还是r的方法?一般来说:text这个位置如果是一个名词,则是属性,而如果是一个动词,则应该是一个方法 5,


这三种方式能解决所有的编码问题
7,requests实现url地址的编码requests.utils.unquote(url编码后的地址)
8,requests可以获取cookie对象

9,访问https地址遇到的一些问题
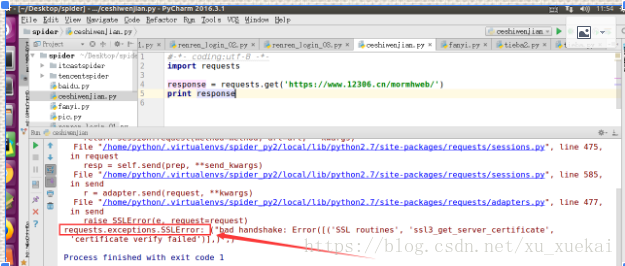
可以看出,当我们用https访问一个没有证书的http网址时,会出现一个错误,是因为该网站没有安全证书所造成,如果想解决这个问题,则:
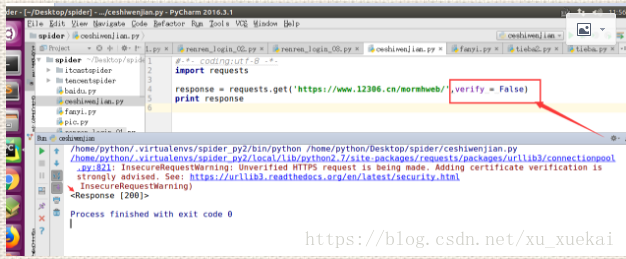
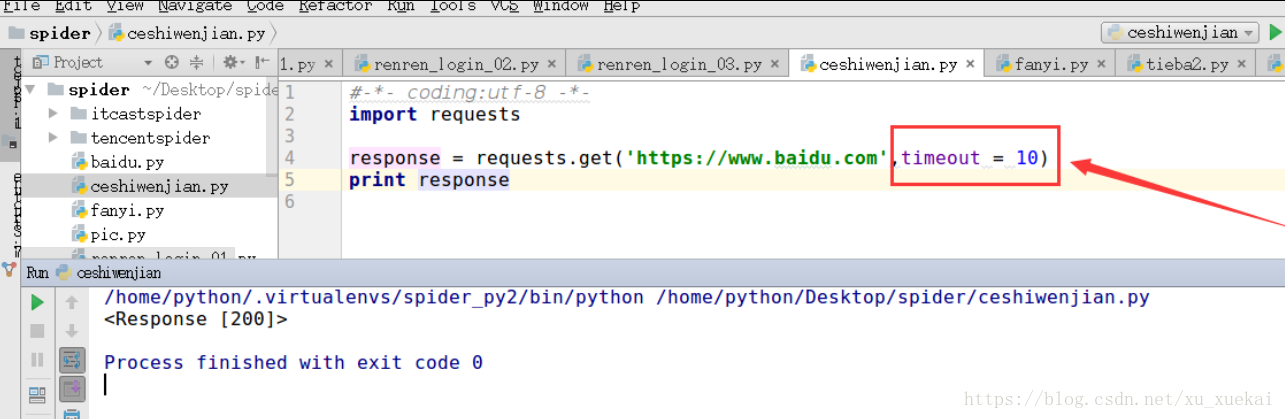
如果我们在10秒内,请求到网页,就正常显示,如果不能,则会报错,配合状态码判断是否成功。


相关文章推荐
- Python爬虫(2):Requests的基本用法
- Python爬虫(2):Requests的基本用法
- python爬虫系列(2)—— requests和BeautifulSoup库的基本用法
- [Python] - 爬虫之Requests基本使用
- 用Python做测试——Requests包的基本用法
- python爬虫入门-urllib的基本用法
- Python爬虫(3):Requests的高级用法
- Python爬虫之正则表达式基本用法实例分析
- 爬虫简单笔记——requests基本用法总结
- Python爬虫(3):Requests的高级用法
- Python爬虫—1入门_1_python内置urllib库的初级用法
- Python3 Requests库基本用法
- python爬虫之requests的基本使用
- Python爬虫框架Scrapy基本用法入门教程
- Python爬虫PyQuery库基本用法入门教程
- python爬虫学习笔记-requests用法
- python正则表达式--基本用法和函数(理论知识)
- 小鸟游的Python爬虫学习笔记——基本库的使用
- Python基本输出函数print()用法小结
- Python爬虫利器二之Beautiful Soup的用法