Redis源码学习简记(五)skiplist跳跃表原理与个人理解
2018-04-09 16:17
381 查看
跳跃表的实现异常精妙,其本质是一个有序链表。结合了概率学,利用内存换时间,使得链表查找达到了o(logn)的速度。媲美红黑树。不过使用的空间应该要多于红黑树。但是其实现比红黑树简单很多,不存在红黑树纷繁复杂的左旋,右旋的操作。今天让我们来看看跳跃表的具体实现吧。同理先撸一下其数据结构。
数据结构
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele; //链表存储的实体,大部分是字符串?
double score;//用于对节点排序。以score作为排序的准则。
struct zskiplistNode *backward;//前驱节点
struct zskiplistLevel { //该节点所存储的层
struct zskiplistNode *forward; //每一层的后继节点
unsigned int span; //该节点走到下一个节点中间跳过的节点数
} level[]; //level数组
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail; //链表头包含头结点和位节点
unsigned long length;//存储链表的长度,不包含头结点
int level;//链表中的最大的层数
} zskiplist;基本数据结构已经看完,渣笔迹花的一个图。
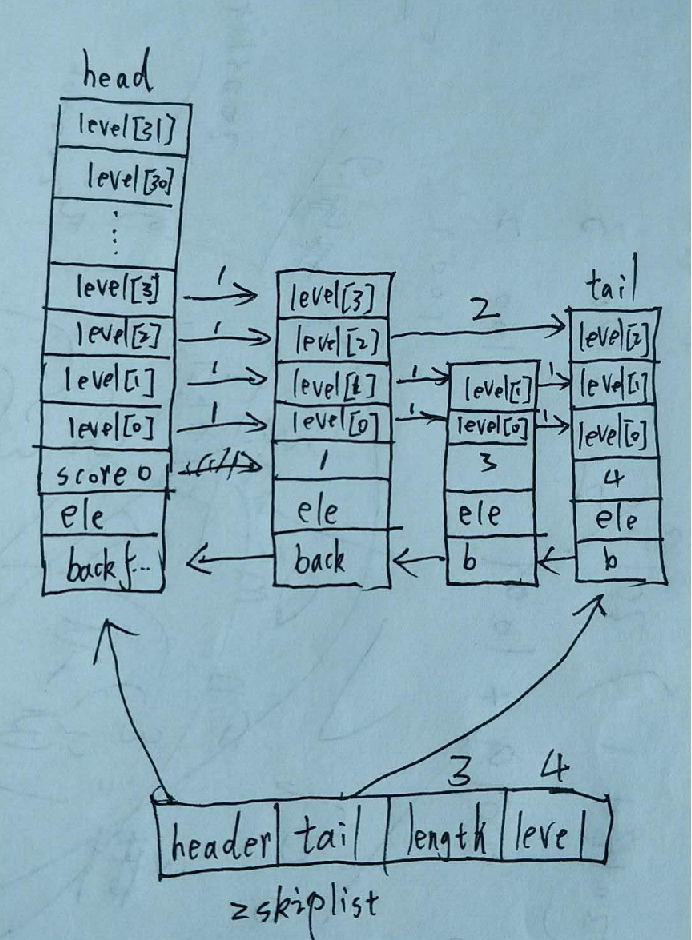
以这个图为例。length长度为3,level为4。而每一个level线上的数字就是该span。大概样子就是这个样子,下面直接撸代码,看看其原理吧。
先来看基本的创建操作。
/* Create a skiplist node with the specified number of levels.
* The SDS string 'ele' is referenced by the node after the call. */
zskiplistNode *zslCreateNode(int level, double score, sds ele) {
zskiplistNode *zn =zmalloc(sizeof(*zn)+level*sizeof(struct zskiplistLevel));
//根据level创建出level个skiplistLvel 与一个zskiplistnode 用于存储backward
zn->score = score;//初始化
zn->ele = ele;
return zn;
}
/* Create a new skiplist. */
zskiplist *zslCreate(void) { //创建一个空链表
int j;
zskiplist *zsl;
zsl = zmalloc(sizeof(*zsl)); //初始化空间
zsl->level = 1;//level至少为1
zsl->length = 0;//长度为0
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
//每个跳跃表头结点是必备的,并且都是以ZSKIPLIST_MAXLEVEL来初始化,而该值默认为32。
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
//初始化每个level。
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
zsl->header->backward = NULL;//前驱与尾节点初始化
zsl->tail = NULL;
return zsl;
}下面观察一下删除操作 如果所有节点都是level=1(head节点除外),那么就相当于退化为简单的双向链表。/* Free the specified skiplist node. The referenced SDS string representation
* of the element is freed too, unless node->ele is set to NULL before calling
* this function. */
void zslFreeNode(zskiplistNode *node) {
sdsfree(node->ele);//删除sds的ele
zfree(node);//删除node结点空间
}
/* Free a whole skiplist. */
void zslFree(zskiplist *zsl) {
zskiplistNode *node = zsl->header->level[0].forward, *next;
// 选择level[0],由于每个结点必定存在level[0] 对于level[0]来说就是简单的双向链表
//通过对level进行遍历,就可以遍历每个链表元素
zfree(zsl->header);
//提前存好第一个结点的地址后,就可以释放头结点空间
while(node) {
//不断遍历释放
next = node->level[0].forward;
zslFreeNode(node);
node = next;
}
//释放链表头
zfree(zsl);
}在看插入之前,先来看看每个节点的level是怎么来,redis使用的是随机函数。/* Returns a random level for the new skiplist node we are going to create.
* The return value of this function is between 1 and ZSKIPLIST_MAXLEVEL
* (both inclusive), with a powerlaw-alike distribution where higher
* levels are less likely to be returned. */
int zslRandomLevel(void) {
int level = 1;
//level至少为1
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
/*
random()&0xFFFF得到的数必定少于等于0xFFFF。
其意义就是去0~0xFFFF之间的随机数
而ZSKIPLIST_P默认为0.25;
那么整个式子就是有0.25的概率进入循环
level-----------概率
1-------------0.75
2-------------0.25*0.25
3-------------0.25*0.25*0.25
4-------------0.25*0.25*0.25*0.25
*/
//得到的数要保证小于等于32。大于32时则为32
//然而大于32的概率几乎是不可能的,除非数据量足够大
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}接下来就可以正式撸插入操作了。/* Insert a new node in the skiplist. Assumes the element does not already
* exist (up to the caller to enforce that). The skiplist takes ownership
* of the passed SDS string 'ele'. */
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
//score为插入的分数,根据该分数进行查找的。
//ele则为插入的元素。
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
/*update 存储插入的每一层的前驱
|8|->
|7|->
|6|----------x----->|6|
|5|->|5|-----|----->|5|
|4|->|4|-----|----->|4|
|3|->|3|-----|>|3|->|3|
|2|->|2|-----|>|2|->|2|
|1|->|1|-----|>|1|->|1|
|0|->|0|->|0||>|0|->|0|
a b c d e
假设插入点为x,x位于c与d之间
那么对插入x的update数据则存了
update[8]=a.level[8]
update[7]=a.levle[7]
update[6]=a.level[6]
update[5]=b.level[5]
update[4]=b.level[4]
update[3]=b.level[3]
update[2]=b.level[2]
update[1]=b.level[1]
update[0]=c.level[0]
*/
unsigned int rank[ZSKIPLIST_MAXLEVEL];
//rank 用于存储level[i]插入点前驱所经过的节点数
int i, level;
serverAssert(!isnan(score));
x = zsl->header;//获取头结点
for (i = zsl->level-1; i >= 0; i--) {
//从高的level开始初始化rank与update
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
//若为第一个节点则将rank[level-1)]先设为0。
//否则为上一个节点rank[i+1]
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
//当后继节点存在并且其score小于后者则继续往后找
//若两个score相等则比较eld的字典序
rank[i] += x->level[i].span;
//span存的为该指针走过的节点数
x = x->level[i].forward;
//继续往下找
}
update[i] = x;
//找到后则直接赋值给updata数组
}
/* we assume the element is not already inside, since we allow duplicated
* scores, reinserting the same element should never happen since the
* caller of zslInsert() should test in the hash table if the element is
* already inside or not. */
level = zslRandomLevel();
//获取随机level
if (level > zsl->level) {
//若获取的level大于最大值,则更新update[zsl->level~level-1部分数据]
for (i = zsl->level; i < level; i++) {
rank[i] = 0;//由于只有头结点有
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
//在没有插入的时候该节点的下一个节点为NULL,设为越过所有的节点
}
zsl->level = level;//更新表头的level值
}
x = zslCreateNode(level,score,ele);//创建要插入的节点
for (i = 0; i < level; i++) {
//进行节点插入
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
//计算x节点的level 如下图
//插入节点x.span为 上式
/*
header update[i] insert update[i]->forward
|-------------------------------|----------x----------|-------------------|
|<--update[i].span--->|
|<------------rank[i]---------->|---------------------|-------------------|
|<----------------------rank[0]------------>|-----------------------------|
*/
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
//更新前面节点的span。
}
/* increment span for untouched levels */
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
//存在level小于zsl->level时,那么大于level的层则需要加一 由于插入了x节点
x->backward = (update[0] == zsl->header) ? NULL : update[0];
//更新前驱节点
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
//更新后继节点的前驱节点若有的话
zsl->length++;
//更新长度
return x;
}删除节点操作int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
//updata数组的意义与插入时的一样。
int i;
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
x = x->level[i].forward;
}
update[i] = x;
}
//获取的做法也跟插入一样。同样从高level往下找。
/* We may have multiple elements with the same score, what we need
* is to find the element with both the right score and object. */
x = x->level[0].forward;//取要删除的结点。
if (x && score == x->score && sdscmp(x->ele,ele) == 0) {
//再次检验
zslDeleteNode(zsl, x, update);
//调用删除函数,可以说是unlink,实际空间并没有free
if (!node)//若node不为空则是需要返回要删除的结点,不使用free否则释放空间。
zslFreeNode(x);
else
*node = x;
return 1;//成功返回1
}
return 0; /* not found */
}删除的指针操作都在zslDeleteNode中,该函数实际做的东西应为unlink/* Internal function used by zslDelete, zslDeleteByScore and zslDeleteByRank */
void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update) {
int i;
//传进来的updata数组则为要删除元素的所有level的上一个节点。
for (i = 0; i < zsl->level; i++) {
if (update[i]->level[i].forward == x) {
//删除操作包括span的更新,forwad指针的重新指定
update[i]->level[i].span += x->level[i].span - 1;
update[i]->level[i].forward = x->level[i].forward;
} else {
update[i]->level[i].span -= 1;
}
}
if (x->level[0].forward) {//重新指定前驱指针
x->level[0].forward->backward = x->backward;
} else {
zsl->tail = x->backward;
//若x的后继指针为空,那么x为尾元素,那么更新头表。
}
while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL)
zsl->level--;
//更新整个链表的level
zsl->length--;
1fa48
//更新长度
}跳跃表的基本操作就到这里。还有一些别的操作,大概看看就能了解。主要是其设计思路与数据结构。
阅读更多

相关文章推荐
- Redis源码学习简记(十)t_list原理与个人理解
- Redis源码学习简记(八)quicklist原理与个人理解
- Redis源码学习简记(九)t_hash原理与个人理解
- 结合redis设计与实现的redis源码学习-5-skiplist(跳跃表)
- 源码分析redis的有序集合,学习skiplist跳跃表数据结构
- 【从下而上学习Redis】数据结构篇(一):跳跃表(skiplist)
- (转)跳跃表skiplist-原理及Java实现
- Skip List(跳跃表)原理详解与实现【转】
- Redis Skip List(跳跃表)
- 浅析SkipList跳跃表原理及代码实现
- 跳跃表SkipList原理代码实现
- 结合redis设计与实现的redis源码学习-8.3-t_list.c(列表键)
- 【算法导论33】跳跃表(Skip list)原理与java实现
- Skip List(跳跃表)原理详解与实现
- 跳跃表Skip List的原理和实现(Java)
- 【算法导论33】跳跃表(Skip list)原理与java实现
- Skip List(跳跃表)原理详解与实现
- redis源码分析(四)、redis命令学习总结—链表List
- 学习common-upload源码,理解上传原理
- Skip List(跳跃表)原理详解与实现