Redis源码学习简记(八)quicklist原理与个人理解
2018-04-12 16:15
375 查看
在看t_list的时候发现,少研究了一个数据结构。还是先把这个快链分析一下,再看后面的东西。quicklist是3.2版本新增加的,所以看着网上博客学习很容易会忽略掉。
#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */旧版本的linkedlist基本上是被淘汰掉了,而是使用的为quicklist来代替。那么这种数据结构,快在哪里,优势又在哪里。首先,我们先来分析其数据结构。
/* quicklist is a 40 byte struct (on 64-bit systems) describing a quicklist.
* 'count' is the number of total entries.
* 'len' is the number of quicklist nodes.
* 'compress' is: -1 if compression disabled, otherwise it's the number
* of quicklistNodes to leave uncompressed at ends of quicklist.
* 'fill' is the user-requested (or default) fill factor. */
typedef struct quicklist {
//quicklist表头结构
quicklistNode *head;//头节点
quicklistNode *tail;//尾节点
unsigned long count; /* total count of all entries in all ziplists */
//所有的entries个数
unsigned long len; /* number of quicklistNodes */
//quicklistNodes节点个数
int fill : 16; /* fill factor for individual nodes */
//正数时,表示ziplist所包含的最大entry个数
//负数则有以下意义
/*
-1 ziplist大小不超过4kb
-2 ziplist大小不超过8kb
-3 ziplist大小不超过16kb
-4 ziplist大小不超过32kb
-5 ziplist大小不超过64kb
*/
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
//首尾两端不被压缩节点的个数
} quicklist; 从这个表头分析,该链表存储的数据增加了fill,count,compress这几个新的字段。具体的作用看了后面的函数就会清楚很多。 看完了表头,看看每个节点的数据结构吧。
/* Node, quicklist, and Iterator are the only data structures used currently. */
/* quicklistNode is a 32 byte struct describing a ziplist for a quicklist.
* We use bit fields keep the quicklistNode at 32 bytes.
* count: 16 bits, max 65536 (max zl bytes is 65k, so max count actually < 32k).
* encoding: 2 bits, RAW=1, LZF=2.
* container: 2 bits, NONE=1, ZIPLIST=2.
* recompress: 1 bit, bool, true if node is temporarry decompressed for usage.
* attempted_compress: 1 bit, boolean, used for verifying during testing.
* extra: 12 bits, free for future use; pads out the remainder of 32 bits */
typedef struct quicklistNode {
//quicklistNode的节点定义
struct quicklistNode *prev;//前驱节点 8字节 32bit
struct quicklistNode *next;//后继节点 8字节 32bit
unsigned char *zl;//使用ziplist或者lzf编码的数据 8字节 32bit
unsigned int sz; /* ziplist size in bytes */
//zl所占的字节数 32bit 4字节
unsigned int count : 16; /* count of items in ziplist */
//zl所包含的元素个数 16bit
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
//zl的编码模式1为ziplist 2为lzf 2bit
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
//zl的数据是否被压缩,压缩则为2,否则为1. 2bit
unsigned int recompress : 1; /* was this node previous compressed? */
//quicklist是否已经压缩过 1bit
unsigned int attempted_compress : 1; /* node can't compress; too small */
//测试使用
unsigned int extra : 10; /* more bits to steal for future usage */
//预留位 10bit
//该数据结构总共占32个字节
} quicklistNode;看完了节点的定义,那么整个链表的结构大概就能了解了。同样使用渣笔迹花了一下图。
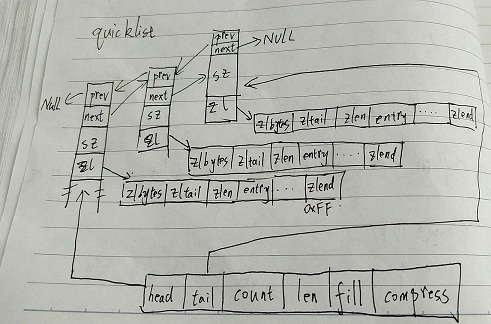
这样的结构,结合了ziplist与adlist的优点,但是变得更加复杂。
首先在插入与删除元素方面会有adlist快速的优点,其二在内存分配上,由于使用了ziplist连续的空间用于存储,减少了碎片的产生。除了这样的特性外,这种快速链还定义了压缩方法。
双向链表的特性是首尾元素使用频繁,中间元素比较少使用,为此,快速链定义compress字段。设置首尾压缩的深度。如下图所示。假设每个点为一个node。
/* |............|..........|............| |<-composer->|..........|<-composer->| | 不压缩 | 压缩 | 不压缩 | */
typedef struct quicklistIter {
//迭代器
const quicklist *quicklist;
//对应的quicklist
quicklistNode *current;
//当前指向的节点
unsigned char *zi;
//ziplist结构指针
long offset; /* offset in current ziplist */
//zi中的偏移
int direction;
//方向
} quicklistIter;
typedef struct quicklistEntry {
const quicklist *quicklist;
//对应的quicklist
quicklistNode *node;
//当前的节点
unsigned char *zi;
//ziplist结构指针
//当前entry的数据,或者是整数或者是字符串
unsigned char *value;
long long longval;
unsigned int sz;//当前zi的字节数
int offset;//entry的当前偏移量
} quicklistEntry;
/* quicklistLZF is a 4+N byte struct holding 'sz' followed by 'compressed'.
* 'sz' is byte length of 'compressed' field.
* 'compressed' is LZF data with total (compressed) length 'sz'
* NOTE: uncompressed length is stored in quicklistNode->sz.
* When quicklistNode->zl is compressed, node->zl points to a quicklistLZF */
typedef struct quicklistLZF {
//当被压缩时,节点的成员zl指向quicklistLZF
unsigned int sz; /* LZF size in bytes*/
char compressed[];
} quicklistLZF;这样做,进一步节省了存储空间,但是会添加了代码复杂度与时间复杂度。当然如果composer为0,而每个节点的ziplist为元素个数为1,则退化为一个普通的双向链表。
除了表头结构与结点结构外,还定义了迭代器,压缩后的数据结构与每个entry的结构。
分析完其数据结构后,让我们来分其中一些重要的函数吧。
基本上都是有创建开始。
/* Create a new quicklist.
* Free with quicklistRelease(). */
quicklist *quicklistCreate(void) {
//创建quicklist
struct quicklist *quicklist;
quicklist = zmalloc(sizeof(*quicklist));
//分配空间以及初始化
quicklist->head = quicklist->tail = NULL;
quicklist->len = 0;
quicklist->count = 0;
quicklist->compress = 0;//首尾被压缩的节点数为0
quicklist->fill = -2;//ziplist大小设置不超过8kb
return quicklist;
}设置压缩深度与ziplist中包含的最大entry值#define COMPRESS_MAX (1 << 16)
void quicklistSetCompressDepth(quicklist *quicklist, int compress) {
//设置压缩节点数由于为16bit
//设置最大为2^16次方
if (compress > COMPRESS_MAX) {
compress = COMPRESS_MAX;
} else if (compress < 0) {
compress = 0;
}
quicklist->compress = compress;
}
#define FILL_MAX (1 << 15)//正数时每个ziplist所包含的最大entry
void quicklistSetFill(quicklist *quicklist, int fill) {
//保证fill小于最大值并且大于-5
if (fill > FILL_MAX) {
fill = FILL_MAX;
} else if (fill < -5) {
fill = -5;
}
quicklist->fill = fill;
}void quicklistSetOptions(quicklist *quicklist, int fill, int depth) {
//设置fill与compress的值
quicklistSetFill(quicklist, fill);
quicklistSetCompressDepth(quicklist, depth);
}创建新的list的接口函数,调用了上述的函数
/* Create a new quicklist with some default parameters. */
quicklist *quicklistNew(int fill, int compress) {
//根据fill与compress创建新表,调用前面所述的函数
quicklist *quicklist = quicklistCreate();
quicklistSetOptions(quicklist, fill, compress);
return quicklist;
}创建新的结点REDIS_STATIC quicklistNode *quicklistCreateNode(void) {
//REDIS_STATIC 相当于static
//创建节点
quicklistNode *node;
node = zmalloc(sizeof(*node));
//分配空间并且初始化
node->zl = NULL;
node->count = 0;
node->sz = 0;
node->next = node->prev = NULL;
node->encoding = QUICKLIST_NODE_ENCODING_RAW;
node->container = QUICKLIST_NODE_CONTAINER_ZIPLIST;
node->recompress = 0;
return node;
}返回链表元素个数与释放整个链表空间/* Return cached quicklist count */
unsigned long quicklistCount(const quicklist *ql) { return ql->count; }
//返回quicklist的entry个数
/* Free entire quicklist. */
void quicklistRelease(quicklist *quicklist) {
//释放整个链表空间
unsigned long len;
quicklistNode *current, *next;
current = quicklist->head;
//获取链表头
len = quicklist->len;
//链表节点个数
while (len--) {
next = current->next;/* Compress the ziplist in 'node' and update encoding details.
* Returns 1 if ziplist compressed successfully.
* Returns 0 if compression failed or if ziplist too small to compress. */
REDIS_STATIC int __quicklistCompressNode(quicklistNode *node) {
#ifdef REDIS_TEST
node->attempted_compress = 1;
#endif
/* Don't bother compressing small values */
if (node->sz < MIN_COMPRESS_BYTES)
//小于48个字节则不压缩
//MIN_COMPRESS_BYTES 定义为48
return 0;
quicklistLZF *lzf = zmalloc(sizeof(*lzf) + node->sz);
//初始化空间
/* Cancel if compression fails or doesn't compress small enough */
//对元素使用lzf算法进行压缩,保证压缩后,能节省至少8字节容量。
//对于压缩怎么做的,实在是非本人所能研究透彻的
//跟hash函数一样包含大量的数学知识
if (((lzf->sz = lzf_compress(node->zl, node->sz, lzf->compressed,
node->sz)) == 0) ||
lzf->sz + MIN_COMPRESS_IMPROVE >= node->sz) {
/* lzf_compress aborts/rejects compression if value not compressable. */
zfree(lzf);
return 0;
}
lzf = zrealloc(lzf, sizeof(*lzf) + lzf->sz);
//重新分配空间,使用zlf压缩后的数据替换原来ziplist数据
zfree(node->zl);
node->zl = (unsigned char *)lzf;
node->encoding = QUICKLIST_NODE_ENCODING_LZF;
//设置编码模式
node->recompress = 0;
//数据已经压缩完成
return 1;
}zfree(current->zl);//释放zlist quicklist->count -= current->count; //减少整体元素个数 zfree(current); //释放对应的node quicklist->len--; //长度减1 current = next; } zfree(quicklist); //释放链表头} 下来就是压缩节点函数,主要调用了lzf的压缩算法,同时保证压缩后,有相应的字节存储效率提升,否则不压缩。压缩完成后会替换原来zl(原来存储的为ziplist)。
/* Compress the ziplist in 'node' and update encoding details.
* Returns 1 if ziplist compressed successfully.
* Returns 0 if compression failed or if ziplist too small to compress. */
REDIS_STATIC int __quicklistCompressNode(quicklistNode *node) {
#ifdef REDIS_TEST
node->attempted_compress = 1;
#endif
/* Don't bother compressing small values */
if (node->sz < MIN_COMPRESS_BYTES)
//小于48个字节则不压缩
//MIN_COMPRESS_BYTES 定义为48
return 0;
quicklistLZF *lzf = zmalloc(sizeof(*lzf) + node->sz);
//初始化空间
/* Cancel if compression fails or doesn't compress small enough */
//对元素使用lzf算法进行压缩,保证压缩后,能节省至少8字节容量。
//对于压缩怎么做的,实在是非本人所能研究透彻的
//跟hash函数一样包含大量的数学知识
if (((lzf->sz = lzf_compress(node->zl, node->sz, lzf->compressed,
1e378
node->sz)) == 0) ||
lzf->sz + MIN_COMPRESS_IMPROVE >= node->sz) {
/* lzf_compress aborts/rejects compression if value not compressable. */
zfree(lzf);
return 0;
}
lzf = zrealloc(lzf, sizeof(*lzf) + lzf->sz);
//重新分配空间,使用zlf压缩后的数据替换原来ziplist数据
zfree(node->zl);
node->zl = (unsigned char *)lzf;
node->encoding = QUICKLIST_NODE_ENCODING_LZF;
//设置编码模式
node->recompress = 0;
//数据已经压缩完成
return 1;
}解压函数,同样替换掉node中的zl数据。/* Uncompress the ziplist in 'node' and update encoding details.
* Returns 1 on successful decode, 0 on failure to decode. */
REDIS_STATIC int __quicklistDecompressNode(quicklistNode *node) {
//对lzf压缩的数据进行解压
#ifdef REDIS_TEST
node->attempted_compress = 0;
#endif
void *decompressed = zmalloc(node->sz);
quicklistLZF *lzf = (quicklistLZF *)node->zl;
if (lzf_decompress(lzf->compressed, lzf->sz, decompressed, node->sz) == 0) {
/* Someone requested decompress, but we can't decompress. Not good. */
zfree(decompressed);
return 0;
}
zfree(lzf);
node->zl = decompressed;
node->encoding = QUICKLIST_NODE_ENCODING_RAW;
return 1;
}根据compress的值更新压缩解压首尾两端的节点,并且对判断当前node是否需要压缩,需要则压缩,否则不压缩。/* Force 'quicklist' to meet compression guidelines set by compress depth.
* The only way to guarantee interior nodes get compressed is to iterate
* to our "interior" compress depth then compress the next node we find.
* If compress depth is larger than the entire list, we return immediately. */
REDIS_STATIC void __quicklistCompress(const quicklist *quicklist,
quicklistNode *node) {
/* If length is less than our compress depth (from both sides),
* we can't compress anything. */
if (!quicklistAllowsCompression(quicklist) ||
quicklist->len < (unsigned int)(quicklist->compress * 2))
return;
//判断要压缩深度大于总体长度
#if 0
/* Optimized cases for small depth counts */
if (quicklist->compress == 1) {
quicklistNode *h = quicklist->head, *t = quicklist->tail;
quicklistDecompressNode(h);
quicklistDecompressNode(t);
if (h != node && t != node)
quicklistCompressNode(node);
return;
} else if (quicklist->compress == 2) {
quicklistNode *h = quicklist->head, *hn = h->next, *hnn = hn->next;
quicklistNode *t = quicklist->tail, *tp = t->prev, *tpp = tp->prev;
quicklistDecompressNode(h);
quicklistDecompressNode(hn);
quicklistDecompressNode(t);
quicklistDecompressNode(tp);
if (h != node && hn != node && t != node && tp != node) {
quicklistCompressNode(node);
}
if (hnn != t) {
quicklistCompressNode(hnn);
}
if (tpp != h) {
quicklistCompressNode(tpp);
}
return;
}
#endif
/* Iterate until we reach compress depth for both sides of the list.a
* Note: because we do length checks at the *top* of this function,
* we can skip explicit null checks below. Everything exists. */
quicklistNode *forward = quicklist->head;
quicklistNode *reverse = quicklist->tail;
int depth = 0;
int in_depth = 0;
while (depth++ < quicklist->compress) {
//将常用的首尾两端进行解压操作
quicklistDecompressNode(forward);
quicklistDecompressNode(reverse);
if (forward == node || reverse == node)
in_depth = 1;
//当node为所找到的节点,那么该节点属于压缩深度外
if (forward == reverse)
return;
forward = forward->next;
reverse = reverse->prev;
}
if (!in_depth)
quicklistCompressNode(node);
//若node不在压缩深度外,则进行压缩
if (depth > 2) {
//最后压缩深度外的元素
/* At this point, forward and reverse are one node beyond depth */
quicklistCompressNode(forward);
quicklistCompressNode(reverse);
}
}插入新的节点,根据after判断实在old_node前面还是右面。同时会根据需求调用数据压缩函数。/* Insert 'new_node' after 'old_node' if 'after' is 1.
* Insert 'new_node' before 'old_node' if 'after' is 0.
* Note: 'new_node' is *always* uncompressed, so if we assign it to
* head or tail, we do not need to uncompress it. */
REDIS_STATIC void __quicklistInsertNode(quicklist *quicklist,
quicklistNode *old_node,
quicklistNode *new_node, int after) {
//在old_node前面或者后面插入节点
//若afeter为1,则是后面插入,如果为0则在前面插入
if (after) {//插入的一些列操作考虑到首尾的问题
new_node->prev = old_node;
if (old_node) {
new_node->next = old_node->next;
if (old_node->next)
old_node->next->prev = new_node;
old_node->next = new_node;
}
if (quicklist->tail == old_node)
quicklist->tail = new_node;
} else {
new_node->next = old_node;
if (old_node) {
new_node->prev = old_node->prev;
if (old_node->prev)
old_node->prev->next = new_node;
old_node->prev = new_node;
}
if (quicklist->head == old_node)
quicklist->head = new_node;
}
/* If this insert creates the only element so far, initialize head/tail. */
if (quicklist->len == 0) {
//若插入前节点长度为0,则需要同时更新头尾结点
quicklist->head = quicklist->tail = new_node;
}
//维护插入后,压缩的深度,可能要对old_node进行压缩操作
if (old_node)
quicklistCompress(quicklist, old_node);
quicklist->len++;
}插入元素接口,用于调用上述函数/* Wrappers for node inserting around existing node. */
//调用上述函数唯一区别在与前面插入还是后面插入
REDIS_STATIC void _quicklistInsertNodeBefore(quicklist *quicklist,
quicklistNode *old_node,
quicklistNode *new_node) {
__quicklistInsertNode(quicklist, old_node, new_node, 0);
}
REDIS_STATIC void _quicklistInsertNodeAfter(quicklist *quicklist,
quicklistNode *old_node,
quicklistNode *new_node) {
__quicklistInsertNode(quicklist, old_node, new_node, 1);
}粗略判断是否会因为元素插入产生ziplist容量爆表。#define sizeMeetsSafetyLimit(sz) ((sz) <= SIZE_SAFETY_LIMIT)
//size_safety_limit默认为8192
REDIS_STATIC int _quicklistNodeAllowInsert(const quicklistNode *node,
const int fill, const size_t sz) {
if (unlikely(!node))
return 0;
//假设pre的size与当前大致size相同
//那么prelen则是两种情况,小于254时为1字节否则为5字节
int ziplist_overhead;
/* size of previous offset */
if (sz < 254)
ziplist_overhead = 1;
else
ziplist_overhead = 5;
//计算encoding长度时,小于64则为1字节,字符与整型是统一的。
//否则根据其编码规则进行添加
/* size of forward offset */
if (sz < 64)
ziplist_overhead += 1;
else if (likely(sz < 16384))
ziplist_overhead += 2;
else
ziplist_overhead += 5;
/* new_sz overestimates if 'sz' encodes to an integer type */
unsigned int new_sz = node->sz + sz + ziplist_overhead;
//大致计算插入sz的节点所产生的长度,忽略因为插入所产生的连锁更新反应
//先判断fill,根据其正负进行不同的判断
if (likely(_quicklistNodeSizeMeetsOptimizationRequirement(new_sz, fill)))
return 1;
else if (!sizeMeetsSafetyLimit(new_sz))
return 0;
else if ((int)node->count < fill)
return 1;
else
return 0;
}从链表头或者从尾部插入结点。/* Add new entry to head node of quicklist.
*
* Returns 0 if used existing head.
* Returns 1 if new head created. */
//最后再看一波插入,分为了头插法和尾插法
int quicklistPushHead(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_head = quicklist->head;
//两种做法,若允许在原有的ziplist中插入则再其中插入
//否则新建一个节点,再节点中插入
//这样保证了每个ziplist足够短,
//后面的未插入结果差不多,区别不大
//返回时若是新增则返回1,若是在原来的基础上插入则返回0
if (likely(
_quicklistNodeAllowInsert(quicklist->head, quicklist->fill, sz))) {
quicklist->head->zl =
ziplistPush(quicklist->head->zl, value, sz, ZIPLIST_HEAD);
quicklistNodeUpdateSz(quicklist->head);
} else {
quicklistNode *node = quicklistCreateNode();
node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);
quicklistNodeUpdateSz(node);
_quicklistInsertNodeBefore(quicklist, quicklist->head, node);
}
quicklist->count++;
quicklist->head->count++;
return (orig_head != quicklist->head);
}
/* Add new entry to tail node of quicklist.
*
* Returns 0 if used existing tail.
* Returns 1 if new tail created. */
int quicklistPushTail(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_tail = quicklist->tail;
if (likely(
_quicklistNodeAllowInsert(quicklist->tail, quicklist->fill, sz))) {
quicklist->tail->zl =
ziplistPush(quicklist->tail->zl, value, sz, ZIPLIST_TAIL);
quicklistNodeUpdateSz(quicklist->tail);
} else {
quicklistNode *node = quicklistCreateNode();
node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_TAIL);
quicklistNodeUpdateSz(node);
_quicklistInsertNodeAfter(quicklist, quicklist->tail, node);
}
quicklist->count++;
quicklist->tail->count++;
return (orig_tail != quicklist->tail);
}后面还有很多像delete,merge等的函数。理解了数据结构以后,弄清楚并不难。有兴趣的可以自行查看该部分的实现方式。
相关文章推荐
- Redis源码学习简记(十)t_list原理与个人理解
- Redis源码学习简记(九)t_hash原理与个人理解
- redis源码分析(八)、redis数据结构之压缩ziplist--------ziplist.c ziplist.h学习笔记
- redis源码解读(六):基础数据结构之quicklist
- redis源码分析(9)redis源码链表学习总结 adlist.h adlist.c
- redis源码阅读理解,及相关语言细节---adlist.c
- Redis源码学习-NoSql复杂类型对象的hash管理(二:List)
- 结合redis设计与实现的redis源码学习-8.3-t_list.c(列表键)
- 3.5学习内容 宽带测速原理,RESTful架构,rpc个人理解
- redis源码分析(四)、redis命令学习总结—链表List
- 源码分析redis的有序集合,学习skiplist跳跃表数据结构
- 学习common-upload源码,理解上传原理
- 结合redis设计与实现的redis源码学习-5-skiplist(跳跃表)
- TLD(Tracking-Learning-Detection)学习与源码理解之(五) .
- redis 个人理解和常用命令以及应用场景
- 深入理解Spark 2.1 Core (九):迭代计算和Shuffle的原理与源码分析
- 分布式缓存技术redis学习系列(四)——redis高级应用(集群搭建、集群分区原理、集群操作)
- Thinking in Java之List接口、ArrayList类源码学习
- TLD(Tracking-Learning-Detection)学习与源码理解之(二)
- Redis源码学习2-内存管理