【机器学习实战】10.k-means聚类算法(1)
2018-03-30 15:17
225 查看
这里主要记录对书上相关程序运行结果的一些展示。
程序:# -*- coding: utf-8 -*-
"""
Created on Fri Mar 30 10:42:00 2018
@author: ##
"""
from numpy import *
import matplotlib.pyplot as plt
def loadDataSet(filename):
'''
导入数据
'''
dataMat=[]
fr=open(filename)
for line in fr.readlines():
curLine=line.strip().split('\t')
#fltLine=map(float,curLine) #python2里返回列表,python3里返回迭代器
fitLine=[float(subLine) for subLine in curLine]
dataMat.append(fitLine)
return dataMat
def distEclude(vecA,vecB):
'''
量化误差指标,两向量的欧氏距离
'''
return sqrt(sum(power(vecA-vecB,2)))
def randCent(dataSet,k):
'''
构建包含k个质心的集合
'''
n=shape(dataSet)[1]
centroids=mat(zeros((k,n)))
for j in range(n):
minJ=min(dataSet[:,j])
rangeJ=float(max(dataSet[:,j])-minJ)
centroids[:,j]=minJ+rangeJ*random.rand(k,1)
return centroids
def kMeans(dataSet,k,distMeas=distEclude,createCent=randCent):
'''
kmeans主体算法
'''
m=shape(dataSet)[0]
clusterAssment=mat(zeros((m,2)))
centroids=createCent(dataSet,k) #随机选择质心
clusterChanged=True
g=0
while clusterChanged:
clusterChanged=False
g+=1
for i in range(m):
minDist=inf
minIndex=-1
#计算样本点到每一个质心的欧式距离,得到最小距离
for j in range(k):
distJI=distMeas(centroids[j,:],dataSet[i,:])
if distJI < minDist:
minDist=distJI
minIndex=j
if clusterAssment[i,0]!=minIndex:
clusterChanged =True
clusterAssment[i,:]=minIndex,minDist**2
'''
输出当前迭代次数、质心位置及相应聚类情况
'''
print(g)
print(centroids)
plotFig(dataSet,clusterAssment,centroids)
'''
#更新质心的位置
clusterAssment[:,0].A 返回基于矩阵的数组,得到各样本点所属的质心标号
nonzero(clusterAssment[:,0].A==cent)[0] 得到质心为cent的样本标号
'''
for cent in range(k):
ptsInClust=dataSet[nonzero(clusterAssment[:,0].A==cent)[0]]
centroids[cent,:]=mean(ptsInClust,axis=0) #在列方向上进行均值计算
return centroids,clusterAssment
def plotFig(dataSet,clusterAssment,centroids):
k=shape(centroids)[0]
plt.scatter(centroids[:,0].A,centroids[:,1].A,s=70,c='black',marker='+')
for i in range(k):
ptsInClust=dataSet[nonzero(clusterAssment[:,0].A==i)[0]]
plt.scatter(ptsInClust[:,0].A,ptsInClust[:,1].A,s=20)
plt.show()
if __name__=='__main__':
dataMat=mat(loadDataSet('testSet.txt'))
#查看数据点
plt.scatter(dataMat[:,0].A,dataMat[:,1].A)
plt.show()
#这里质心数量设为4
myCentroids,clusterAssing=kMeans(dataMat,4)
#print(myCentroids)
plotFig(dataMat,clusterAssing,myCentroids)运行结果:
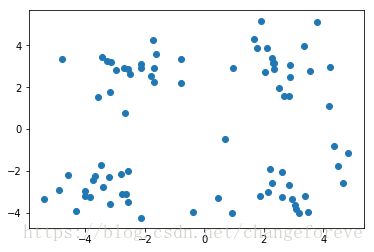
通过查看数据集的散点图,确定簇个数为4,具体数据分布情况为:
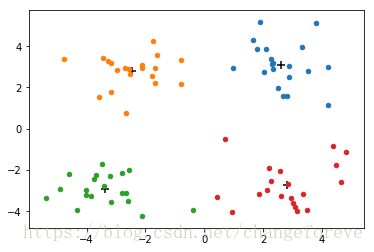
程序运行后,得到聚类结果如下图所示(黑色标记的为质心):
其各质心在迭代时的移动情况如下图所示:
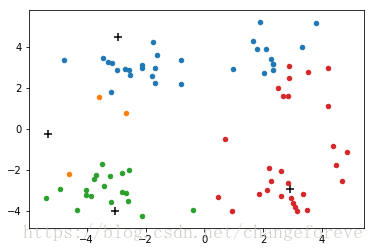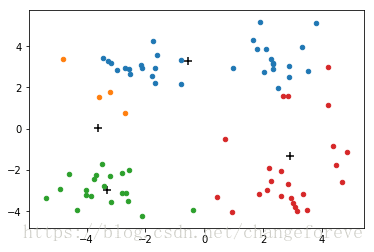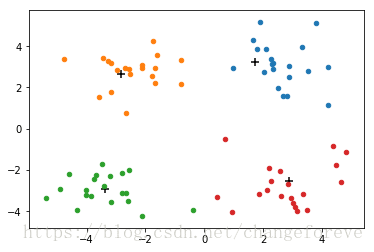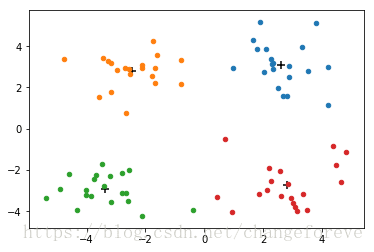
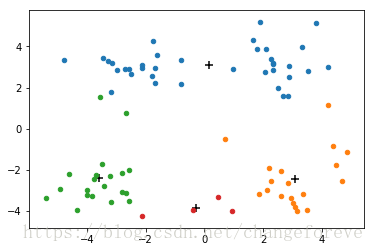
但是k-means可能会收敛到局部最小值,如下图所示:
程序:# -*- coding: utf-8 -*-
"""
Created on Fri Mar 30 10:42:00 2018
@author: ##
"""
from numpy import *
import matplotlib.pyplot as plt
def loadDataSet(filename):
'''
导入数据
'''
dataMat=[]
fr=open(filename)
for line in fr.readlines():
curLine=line.strip().split('\t')
#fltLine=map(float,curLine) #python2里返回列表,python3里返回迭代器
fitLine=[float(subLine) for subLine in curLine]
dataMat.append(fitLine)
return dataMat
def distEclude(vecA,vecB):
'''
量化误差指标,两向量的欧氏距离
'''
return sqrt(sum(power(vecA-vecB,2)))
def randCent(dataSet,k):
'''
构建包含k个质心的集合
'''
n=shape(dataSet)[1]
centroids=mat(zeros((k,n)))
for j in range(n):
minJ=min(dataSet[:,j])
rangeJ=float(max(dataSet[:,j])-minJ)
centroids[:,j]=minJ+rangeJ*random.rand(k,1)
return centroids
def kMeans(dataSet,k,distMeas=distEclude,createCent=randCent):
'''
kmeans主体算法
'''
m=shape(dataSet)[0]
clusterAssment=mat(zeros((m,2)))
centroids=createCent(dataSet,k) #随机选择质心
clusterChanged=True
g=0
while clusterChanged:
clusterChanged=False
g+=1
for i in range(m):
minDist=inf
minIndex=-1
#计算样本点到每一个质心的欧式距离,得到最小距离
for j in range(k):
distJI=distMeas(centroids[j,:],dataSet[i,:])
if distJI < minDist:
minDist=distJI
minIndex=j
if clusterAssment[i,0]!=minIndex:
clusterChanged =True
clusterAssment[i,:]=minIndex,minDist**2
'''
输出当前迭代次数、质心位置及相应聚类情况
'''
print(g)
print(centroids)
plotFig(dataSet,clusterAssment,centroids)
'''
#更新质心的位置
clusterAssment[:,0].A 返回基于矩阵的数组,得到各样本点所属的质心标号
nonzero(clusterAssment[:,0].A==cent)[0] 得到质心为cent的样本标号
'''
for cent in range(k):
ptsInClust=dataSet[nonzero(clusterAssment[:,0].A==cent)[0]]
centroids[cent,:]=mean(ptsInClust,axis=0) #在列方向上进行均值计算
return centroids,clusterAssment
def plotFig(dataSet,clusterAssment,centroids):
k=shape(centroids)[0]
plt.scatter(centroids[:,0].A,centroids[:,1].A,s=70,c='black',marker='+')
for i in range(k):
ptsInClust=dataSet[nonzero(clusterAssment[:,0].A==i)[0]]
plt.scatter(ptsInClust[:,0].A,ptsInClust[:,1].A,s=20)
plt.show()
if __name__=='__main__':
dataMat=mat(loadDataSet('testSet.txt'))
#查看数据点
plt.scatter(dataMat[:,0].A,dataMat[:,1].A)
plt.show()
#这里质心数量设为4
myCentroids,clusterAssing=kMeans(dataMat,4)
#print(myCentroids)
plotFig(dataMat,clusterAssing,myCentroids)运行结果:
通过查看数据集的散点图,确定簇个数为4,具体数据分布情况为:
程序运行后,得到聚类结果如下图所示(黑色标记的为质心):
其各质心在迭代时的移动情况如下图所示:
但是k-means可能会收敛到局部最小值,如下图所示:

相关文章推荐
- 机器学习实战-KNN算法
- 机器学习-实战-入门-MNIST手写数字识别
- 机器学习实战---读书笔记: 第3章 决策树
- 机器学习项目实战之贷款申请最大利润
- 机器学习之实战朴素贝叶斯算法
- [机器学习实战] 决策树ID3算法
- 实战8.Spark MLlib(上)--机器学习及SparkMLlib简介
- 【机器学习实战】-01KNN近邻算法
- 【机器学习实战】Logistic回归例程调试(1)
- 机器学习实战之 决策树——ID3算法
- 机器学习实战之朴素贝叶斯
- PYTHON机器学习实战——SVM支持向量机
- 机器学习实战笔记 k 近邻算法 函数解析
- 机器学习实战(二)决策树
- 机器学习入门实战——感知机算法实战Iris数据集
- 机器学习理论与实战(十六)概率图模型04
- 机器学习实战—第1章
- 【机器学习实战】制作五子棋AI之二:界面组合与棋子放置(pygame)