1、为什么编程中建议使用netty而不是用jdk nio?
2018-03-30 01:21
477 查看
如果对nio了解比较透彻的话,就不会纠结这个问题了,毕竟市面上流行的中间件,如mycat ,spark都是用的nio,当然使用netty的更多,如dubbo;
我们需要知道nio的原理,同时也不必乱造轮子。
使用jdk-nio你需要掌握linux-selector原理,就是将所有的channel注册到一个selector上,selector通过轮询检测,判断这些channel是否是可用的,如 可读,可写,已连接等。如果是可用的需要进一步处理,不能用当前线程进行处理,这样会造成线程阻塞,应该使用线程池来处理。
需要熟悉jdk-nio提供的几个关键类:Selector , SocketChannel , ServerSocketChannel , FileChannel ,ByteBuffer ,SelectionKey 。完成一次调用需要用到这些对象。
需要知道网络知识:
tcp粘包,半包
网络闪断
网路阻塞
包体溢出
包体重复发送
需要知道linux底层实现,如selector ,如何正确的关闭channel,如何退出注销selector ,如何避免selector太过于频繁。
需要知道如何让client端获得server端的返回值,然后才返回给前端,需要如何等待或在怎样作熔断机制。
需要知道对象序列化,及序列化算法。
Reliability ,提供TCP的可靠性,TCP的传输要保证数据能够准确到达目的地,如果不能,需要能检测出来并且重新发送数据。
Data Flow Control,提供TCP的流控特性,管理发送数据的速率,不要超过设备的承载能力
为了能够实现以上2点,TCP实现了很多细节的功能来保证数据传输,比如说 滑动窗口适应系统,超时重传机制,累计ACK等。
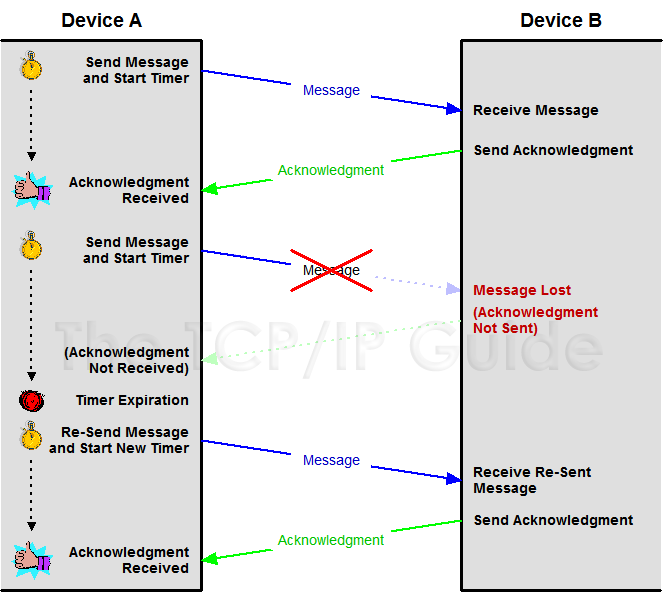
IP层协议属于不可靠的协议,IP层并不关系数据是否发送到了对端,TCP通过确认机制来保证数据传输的可靠性,在比较早的时候使用的是send–wait–send的模式,其实这种模式叫做stop-wait模式,发送数据方在发送数据之后会启动定时器,但是如果数据或者ACK丢失,那么定时器到期之后,收不到ACK就认为发送出现状况,要进行重传。这样就会降低了通信的效率,如下图所示,这种方式被称为 positive acknowledgment with retransmission (PAR):
可以假设一下,来优化一下PAR效率低的缺点,比如我让发送的每一个包都有一个id,接收端必须对每一个包进行确认,这样设备A一次多发送几个片段,而不必等候ACK,同时接收端也要告知它能够收多少,这样发送端发起来也有个限制,当然还需要保证顺序性,不要乱序,对于乱序的状况,我们可以允许等待一定情况下的乱序,比如说先缓存提前到的数据,然后去等待需要的数据,如果一定时间没来就DROP掉,来保证顺序性!

在TCP/IP协议栈中,滑动窗口的引入可以解决此问题,先来看从概念上数据分为哪些类
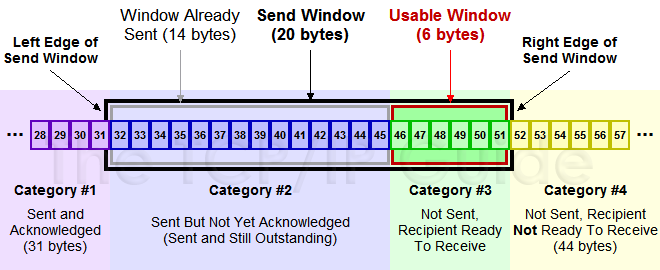
Sent and Acknowledged:这些数据表示已经发送成功并已经被确认的数据
28~31中的bytes,这些数据其实的位置是在窗口之外,因为窗口内顺序最低的被确认之后,要移除窗口,实际上是窗口进行合拢,同时打开接收新的带发送的数据
Send But Not Yet Acknowledged:这部分数据称为发送但没有被确认,数据被发送出去,没有收到接收端的ACK,认为并没有完成发送,这个属于窗口内的数据。
Not Sent,Recipient Ready to Receive:这部分是尽快发送的数据,这部分数据已经被加载到缓存中,也就是窗口中了,等待发送,其实这个窗口是完全有接收方告知的,接收方告知还是能够接受这些包,所以发送方需要尽快的发送这些包
Not Sent,Recipient Not Ready to Receive: 这些数据属于未发送,同时接收端也不允许发送的,因为这些数据已经超出了发送端所接收的范围
接收端也是有一个接收窗口的,类似发送端,接收端的数据有3个分类,因为接收端并不需要等待ACK所以它没有类似的接收并确认了的分类,情况如下
Received and ACK Not Send to Process:这部分数据属于接收了数据但是还没有被上层的应用程序接收,也是被缓存在窗口内
Received Not ACK: 已经接收并,但是还没有回复ACK,这些包可能输属于Delay ACK的范畴了
Not Received:有空位,还没有被接收的数据。
对于发送方来讲,窗口内的包括两部分,就是发送窗口(已经发送了,但是没有收到ACK);可用窗口,接收端允许发送但是没有发送的那部分称为可用窗口。
Send Window : 20个bytes 这部分值是有接收方在三次握手的时候进行通告的,同时在接收过程中也不断的通告可以发送的窗口大小,来进行适应
Window Already Sent: 已经发送的数据,但是并没有收到ACK。
举一个例子来说明一下滑动窗口的原理:
假设32~45 这些数据,是上层Application发送给TCP的,TCP将其分成四个Segment来发往internet
seg1 32~34 seg3 35~36 seg3 37~41 seg4 42~45 这四个片段,依次发送出去,此时假设接收端之接收到了seg1 seg2 seg4
此时接收端的行为是回复一个ACK包说明已经接收到了32~36的数据,并将seg4进行缓存(保证顺序,产生一个保存seg3 的hole)
发送端收到ACK之后,就会将32~36的数据包从发送并没有确认切到发送已经确认,提出窗口,这个时候窗口向右移动
假设接收端通告的Window Size仍然不变,此时窗口右移,产生一些新的空位,这些是接收端允许发送的范畴
对于丢失的seg3,如果超过一定时间,TCP就会重新传送(重传机制),重传成功会seg3 seg4一块被确认,不成功,seg4也将被丢弃
不断重复着上述的过程,随着窗口不断滑动,将真个数据流发送到接收端,实际上接收端的Window Size通告也是会变化的,接收端根据这个值来确定何时及发送多少数据,从对数据流进行流控。原理图如下图所示:
滑动窗口动态调整
主要是根据接收端的接收情况,动态去调整Window Size,然后来控制发送端的数据流量
客户端不断快速发送数据,服务器接收相对较慢,看下实验的结果
a. 包175,发送ACK携带WIN = 384,告知客户端,现在只能接收384个字节
b. 包176,客户端果真只发送了384个字节,Wireshark也比较智能,也宣告TCP Window Full
c. 包177,服务器回复一个ACK,并通告窗口为0,说明接收方已经收到所有数据,并保存到缓冲区,但是这个时候应用程序并没有接收这些数据,导致缓冲区没有更多的空间,故通告窗口为0, 这也就是所谓的零窗口,零窗口期间,发送方停止发送数据
d. 客户端察觉到窗口为0,则不再发送数据给接收方
e. 包178,接收方发送一个窗口通告,告知发送方已经有接收数据的能力了,可以发送数据包了
f. 包179,收到窗口通告之后,就发送缓冲区内的数据了.
总结一点,就是接收端可以根据自己的状况通告窗口大小,从而控制发送端的接收,进行流量控制。
cd21
的信息(粘包);如果可用窗体较小,就有可能发生对一个tcp的请求信息进行拆包。
由于tcp不能理解应用层(http/..)的业务数据,所以tcp无法保证数据不被拆包或粘包。这只能由业务层对其解决。
常见的解决方法:
1、业务数据定长,不足用空格填充,缺点是业务数据比设定的数据更长。
2、特定字符分割,如回车健。
3、对业务数据长度进行统计,放在消息体的前4位byte中;这是通用做法。
这些都是通过应用层的处理方法,有没有在传输控制层的解决方法呢?解决方法就是模拟应用层发送和接收消息,来解决tcp的粘包问题。
但不能处理拆包问题,因为最后一行没有出现(\r\n,\n)就到达可用包体尾部。
如果最后一行没有出现(\r\n,\n),LineBasedFrameDecoder会抛出异常。
LineBasedFrameDecoder 一般和StringDecoder配合使用,LineBasedFrameDecoder负责对拆分,StringDecoder把一行数据转换为字符串,方便后面使用,也可不用StringDecoder,使用ByteBuf对象。
缺点是如果业务数据比定长还长,解码会有问题。
byteOrder:表示字节流表示的数据是大端还是小端,用于长度域的读取;默认是“BIG_ENDIAN” ,//LITTLE_ENDIAN
maxFrameLength:表示的是包的最大长度,超出包的最大长度netty将会做一些特殊处理;
lengthFieldOffset:指的是长度域的偏移量,表示跳过指定长度个字节之后的才是业务数据长度域;如果有header的话需要做考虑。
lengthFieldLength:用来记录该帧数据长度的字段本身的长度;
如
lengthAdjustment:该字段加长度字段等于数据帧的长度,包体长度调整的大小,长度域的数值表示的长度加上这个修正值表示的就是带header的包;
initialBytesToStrip:从数据帧中跳过的字节数,表示获取完一个完整的数据包之后,忽略前面的指定的位数个字节,应用解码器拿到的就是不带长度域的数据包;
failFast:如果为true,则表示读取到长度域,TA的值的超过maxFrameLength,就抛出一个 TooLongFrameException,而为false表示只有当真正读取完长度域的值表示的字节之后,才会抛出 TooLongFrameException,默认情况下设置为true,建议不要修改,否则可能会造成内存溢出。
LengthFieldBasedFrameDecoder定义了一个长度的字段来表示消息的长度,因此能够处理可变长度的消息。将消息分为消息头和消息体,消息头固定位置增加一个表示长度的字段,通过长度字段来获取整包的信息。LengthFieldBasedFrameDecoder继承了ByteToMessageDecoder,即转换字节这样的工作是由ByteToMessageDecoder来完成,而LengthFieldBasedFrameDecoder只用安心完成他的解码工作就好。Netty在解耦和方面确实做的不错。
如果不序列化,就不能恢复对象了么?其实不是,持久化对象的实质是一个二进制数组。序列化只是程序上作为标示,表明这个对象在序列化和反序列化还需要做一些什么样的补充。
java序列化的缺点:
1、压缩耗费时间长
2、压缩后数组较大
使用数组+对象流可以知道jdk序列化后的数组大小。
序列化过程的实质是对象变为流的过程。
我们通常以为将Java对象序列化成二进制比序列化成XML或Json更快,其实是错误的,如果你关心性能,建议避免Java序列化。
Java序列化有很多的要求,最主要的一个是包含能够序列化任何东西(或至少任何实现Serializable接口)。这样才能进入其他JVM之中,这很重要,所以有时性能不是主要的要求,标准的格式才最重要。
Ordr代码:
public class Order implements Serializable {
private long id;
private String description;
private BigDecimal totalCost = BigDecimal.valueOf(0);
private List orderLines = new ArrayList();
private Customer customer;
我们经常看到CPU花费很多时间内进行Java序列化,下面我们研究一下,假设一定Order,虽然只有几个字节,但是序列化以后不是几十个字节,而是600多个字节:
序列化输出:
—-sr–model.Order—-h#—–J–idL–customert–Lmodel/Customer;L–descriptiont–Ljava/lang/String;L–orderLinest–Ljava/util/List;L–totalCostt–Ljava/math/BigDecimal;xp——–ppsr–java.util.ArrayListx—–a—-I–sizexp—-w—–sr–model.OrderLine–&-1-S—-I–lineNumberL–costq-~–L–descriptionq-~–L–ordert–Lmodel/Order;xp—-sr–java.math.BigDecimalT–W–(O—I–scaleL–intValt–Ljava/math/BigInteger;xr–java.lang.Number———–xp—-sr–java.math.BigInteger—–;—–I–bitCountI–bitLengthI–firstNonzeroByteNumI–lowestSetBitI–signum[–magnitudet–[Bxq-~———————-ur–[B——T—-xp—-xxpq-~–xq-~–
正如你可能已经注意到,Java序列化写入不仅是完整的类名,也包含整个类的定义,包含所有被引用的类。类定义可以是相当大的,也许构成了性能和效率的问题,当然这是编写一个单一的对象。如果您正在编写了大量相同的类的对象,这时类定义的开销通常不是一个大问题。另一件事情是,如果你的对象有一类的引用(如元数据对象),那么Java序列化将写入整个类的定义,不只是类的名称,因此,使用Java序列化写出元数据(meta-data)是非常昂贵的。
Externalizable
通过实现Externalizable接口,这是可能优化Java序列化的。实现此接口,避免写出整个类定义,只是类名被写入。它需要你实施readExternal和writeExternal方法方法的,所以需要做一些工作,但相比仅仅是实现Serializable更快,更高效。
Externalizable对小数目对象有效的多。但是对大量对象,或者重复对象,则效率低,必须重写readExternal和writeExternal方法来知道那些属性是需要被记录的。
序列化输出:
—-sr–model.Order—*3–^—xpw———psr–java.math.BigDecimalT–W–(O—I–scaleL–intValt–Ljava/math/BigInteger;xr–java.lang.Number———–xp—-sr–java.math.BigInteger—–;—–I–bitCountI–bitLengthI–firstNonzeroByteNumI–lowestSetBitI–signum[–magnitudet–[Bxq-~———————-ur–[B——T—-xp—-xxpsr–java.util.ArrayListx—–a—-I–sizexp—-w—–sr–model.OrderLine-!!|—S—xpw—–pq-~–q-~–xxx
参考:https://blog.csdn.net/caomiao2006/article/details/51588927
序列化成XML或JSON可以允许其他语言访问,可以实现REST服务等。缺点是文本格式的效率比优化的二进制格式低一些。
Kryo
Kryo 是一种快速,高效的序列化的Java框架。 KRYO是新的BSD许可下一个开源项目提供。这是一个很小的项目,只有3名成员,它首先在2009年出品。
工作原理类似于Java序列化KRYO,尊重瞬态字段,但不要求一类是可序列化的。KRYO有一定的局限性,比如需要有一个默认的构造函数的类,在序列化将java.sql.Time java.sql.Date java.sql.Timestamp类会遇到一些问题。
order序列化结果:
——java-util-ArrayLis—–model-OrderLin—-java-math-BigDecima———model-Orde—–
我们需要知道nio的原理,同时也不必乱造轮子。
使用jdk-nio你需要掌握linux-selector原理,就是将所有的channel注册到一个selector上,selector通过轮询检测,判断这些channel是否是可用的,如 可读,可写,已连接等。如果是可用的需要进一步处理,不能用当前线程进行处理,这样会造成线程阻塞,应该使用线程池来处理。
需要熟悉jdk-nio提供的几个关键类:Selector , SocketChannel , ServerSocketChannel , FileChannel ,ByteBuffer ,SelectionKey 。完成一次调用需要用到这些对象。
需要知道网络知识:
tcp粘包,半包
网络闪断
网路阻塞
包体溢出
包体重复发送
需要知道linux底层实现,如selector ,如何正确的关闭channel,如何退出注销selector ,如何避免selector太过于频繁。
需要知道如何让client端获得server端的返回值,然后才返回给前端,需要如何等待或在怎样作熔断机制。
需要知道对象序列化,及序列化算法。
TCP 滑动窗体技术
在tcp学习中,我们知道有个技术叫滑动窗体技术,就是接收端会向发送端发送一条消息,下次可以接受多少长度的内容,以免接收方不能接收过多的数据。滑动窗口(Sliding Window)
TCP/UDP以及其他协议都可以完成数据的传输,从一端传输到另外一端,TCP比较出众的一点就是提供一个可靠的,流控的数据传输,所以实现起来要比其他协议复杂的多,先来看下这两个修饰词的意义:Reliability ,提供TCP的可靠性,TCP的传输要保证数据能够准确到达目的地,如果不能,需要能检测出来并且重新发送数据。
Data Flow Control,提供TCP的流控特性,管理发送数据的速率,不要超过设备的承载能力
为了能够实现以上2点,TCP实现了很多细节的功能来保证数据传输,比如说 滑动窗口适应系统,超时重传机制,累计ACK等。
IP层协议属于不可靠的协议,IP层并不关系数据是否发送到了对端,TCP通过确认机制来保证数据传输的可靠性,在比较早的时候使用的是send–wait–send的模式,其实这种模式叫做stop-wait模式,发送数据方在发送数据之后会启动定时器,但是如果数据或者ACK丢失,那么定时器到期之后,收不到ACK就认为发送出现状况,要进行重传。这样就会降低了通信的效率,如下图所示,这种方式被称为 positive acknowledgment with retransmission (PAR):
可以假设一下,来优化一下PAR效率低的缺点,比如我让发送的每一个包都有一个id,接收端必须对每一个包进行确认,这样设备A一次多发送几个片段,而不必等候ACK,同时接收端也要告知它能够收多少,这样发送端发起来也有个限制,当然还需要保证顺序性,不要乱序,对于乱序的状况,我们可以允许等待一定情况下的乱序,比如说先缓存提前到的数据,然后去等待需要的数据,如果一定时间没来就DROP掉,来保证顺序性!
在TCP/IP协议栈中,滑动窗口的引入可以解决此问题,先来看从概念上数据分为哪些类
Sent and Acknowledged:这些数据表示已经发送成功并已经被确认的数据
28~31中的bytes,这些数据其实的位置是在窗口之外,因为窗口内顺序最低的被确认之后,要移除窗口,实际上是窗口进行合拢,同时打开接收新的带发送的数据
Send But Not Yet Acknowledged:这部分数据称为发送但没有被确认,数据被发送出去,没有收到接收端的ACK,认为并没有完成发送,这个属于窗口内的数据。
Not Sent,Recipient Ready to Receive:这部分是尽快发送的数据,这部分数据已经被加载到缓存中,也就是窗口中了,等待发送,其实这个窗口是完全有接收方告知的,接收方告知还是能够接受这些包,所以发送方需要尽快的发送这些包
Not Sent,Recipient Not Ready to Receive: 这些数据属于未发送,同时接收端也不允许发送的,因为这些数据已经超出了发送端所接收的范围
接收端也是有一个接收窗口的,类似发送端,接收端的数据有3个分类,因为接收端并不需要等待ACK所以它没有类似的接收并确认了的分类,情况如下
Received and ACK Not Send to Process:这部分数据属于接收了数据但是还没有被上层的应用程序接收,也是被缓存在窗口内
Received Not ACK: 已经接收并,但是还没有回复ACK,这些包可能输属于Delay ACK的范畴了
Not Received:有空位,还没有被接收的数据。
对于发送方来讲,窗口内的包括两部分,就是发送窗口(已经发送了,但是没有收到ACK);可用窗口,接收端允许发送但是没有发送的那部分称为可用窗口。
Send Window : 20个bytes 这部分值是有接收方在三次握手的时候进行通告的,同时在接收过程中也不断的通告可以发送的窗口大小,来进行适应
Window Already Sent: 已经发送的数据,但是并没有收到ACK。
滑动窗口原理
TCP并不是每一个报文段都会回复ACK的,可能会对两个报文段发送一个ACK,也可能会对多个报文段发送1个ACK【累计ACK】,比如说发送方有1/2/3 3个报文段,先发送了2,3 两个报文段,但是接收方期望收到1报文段,这个时候2,3报文段就只能放在缓存中等待报文1的空洞被填上,如果报文1,一直不来,报文2/3也将被丢弃,如果报文1来了,那么会发送一个ACK对这3个报文进行一次确认。举一个例子来说明一下滑动窗口的原理:
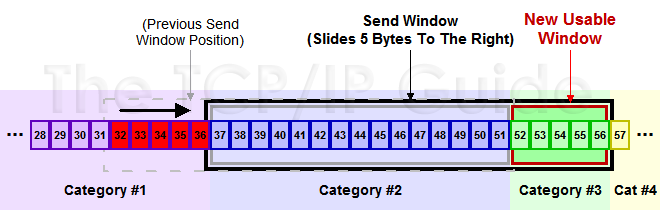
假设32~45 这些数据,是上层Application发送给TCP的,TCP将其分成四个Segment来发往internet
seg1 32~34 seg3 35~36 seg3 37~41 seg4 42~45 这四个片段,依次发送出去,此时假设接收端之接收到了seg1 seg2 seg4
此时接收端的行为是回复一个ACK包说明已经接收到了32~36的数据,并将seg4进行缓存(保证顺序,产生一个保存seg3 的hole)
发送端收到ACK之后,就会将32~36的数据包从发送并没有确认切到发送已经确认,提出窗口,这个时候窗口向右移动
假设接收端通告的Window Size仍然不变,此时窗口右移,产生一些新的空位,这些是接收端允许发送的范畴
对于丢失的seg3,如果超过一定时间,TCP就会重新传送(重传机制),重传成功会seg3 seg4一块被确认,不成功,seg4也将被丢弃
不断重复着上述的过程,随着窗口不断滑动,将真个数据流发送到接收端,实际上接收端的Window Size通告也是会变化的,接收端根据这个值来确定何时及发送多少数据,从对数据流进行流控。原理图如下图所示:
滑动窗口动态调整
主要是根据接收端的接收情况,动态去调整Window Size,然后来控制发送端的数据流量
客户端不断快速发送数据,服务器接收相对较慢,看下实验的结果
a. 包175,发送ACK携带WIN = 384,告知客户端,现在只能接收384个字节
b. 包176,客户端果真只发送了384个字节,Wireshark也比较智能,也宣告TCP Window Full
c. 包177,服务器回复一个ACK,并通告窗口为0,说明接收方已经收到所有数据,并保存到缓冲区,但是这个时候应用程序并没有接收这些数据,导致缓冲区没有更多的空间,故通告窗口为0, 这也就是所谓的零窗口,零窗口期间,发送方停止发送数据
d. 客户端察觉到窗口为0,则不再发送数据给接收方
e. 包178,接收方发送一个窗口通告,告知发送方已经有接收数据的能力了,可以发送数据包了
f. 包179,收到窗口通告之后,就发送缓冲区内的数据了.
总结一点,就是接收端可以根据自己的状况通告窗口大小,从而控制发送端的接收,进行流量控制。
TCP为什么会发生粘包问题呢?
其实就是滑动窗体的大小决定的,如果可用窗体较大,那就可以装下多个tcp请求cd21
的信息(粘包);如果可用窗体较小,就有可能发生对一个tcp的请求信息进行拆包。
由于tcp不能理解应用层(http/..)的业务数据,所以tcp无法保证数据不被拆包或粘包。这只能由业务层对其解决。
常见的解决方法:
1、业务数据定长,不足用空格填充,缺点是业务数据比设定的数据更长。
2、特定字符分割,如回车健。
3、对业务数据长度进行统计,放在消息体的前4位byte中;这是通用做法。
这些都是通过应用层的处理方法,有没有在传输控制层的解决方法呢?解决方法就是模拟应用层发送和接收消息,来解决tcp的粘包问题。
模拟粘包
让client循环向server发送消息,业务数据因小于可用包体,发生粘包。LineBasedFrameDecoder如何解决粘包?
其实就是运用了前面所说的第二种方法,对特定字符(\r\n,\n)进行拆分处理;但不能处理拆包问题,因为最后一行没有出现(\r\n,\n)就到达可用包体尾部。
如果最后一行没有出现(\r\n,\n),LineBasedFrameDecoder会抛出异常。
LineBasedFrameDecoder 一般和StringDecoder配合使用,LineBasedFrameDecoder负责对拆分,StringDecoder把一行数据转换为字符串,方便后面使用,也可不用StringDecoder,使用ByteBuf对象。
自定义分隔符
在netty包io.netty.handler.codec中,定义了许多**Decoder,其中DelimiterBasedFrameDecoder就是提供自定义分割符的Decoder,使用如下:public void initChannel(SocketChannel ch) throws Exception {
ByteBuf delimiter = Unpooled.copiedBuffer("$_" .getBytes());
ch.pipeline()
.addLast( new DelimiterBasedFrameDecoder(1024,delimiter));
//1024 如果达到1024byte还没有找到风格符,抛出异常。
ch.pipeline().addLast(new StringDecoder());
ch.pipeline().addLast(new EchoServerHandler());
}为什么不需要处理拆包或半包问题?
拆包或半包是由于滑动窗体的长度不够装下完整的业务数据,但是在下一次接收的时候会保证之后的业务数据,直到所有的业务数据被接收完成,所以无需作特别的处理。FixedLengthFrameDecoder定长解码
如下使用:channel.pipeline().addLast(new FixedLengthFrameDecoder(10));
缺点是如果业务数据比定长还长,解码会有问题。
LengthFieldBasedFrameDecoder
大多数的协议(私有或者公有),协议头中会携带长度字段,用于标识消息体或者整包消息的长度,例如SMPP、HTTP协议等。由于基于长度解码需求的通用性,Netty提供了LengthFieldBasedFrameDecoder,自动屏蔽TCP底层的拆包和粘 包问题,只需要传入正确的参数,即可轻松解决“读半包“问题。public LengthFieldBasedFrameDecoder
(ByteOrder byteOrder, int maxFrameLength, int lengthFieldOffset,
int lengthFieldLength, int lengthAdjustment, int initialBytesToStrip,
boolean failFast) {
...
}byteOrder:表示字节流表示的数据是大端还是小端,用于长度域的读取;默认是“BIG_ENDIAN” ,//LITTLE_ENDIAN
maxFrameLength:表示的是包的最大长度,超出包的最大长度netty将会做一些特殊处理;
lengthFieldOffset:指的是长度域的偏移量,表示跳过指定长度个字节之后的才是业务数据长度域;如果有header的话需要做考虑。
lengthFieldLength:用来记录该帧数据长度的字段本身的长度;
如
.addLast(new LengthFieldBasedFrameDecoder(65536, 0, 4, 0, 0))
lengthAdjustment:该字段加长度字段等于数据帧的长度,包体长度调整的大小,长度域的数值表示的长度加上这个修正值表示的就是带header的包;
initialBytesToStrip:从数据帧中跳过的字节数,表示获取完一个完整的数据包之后,忽略前面的指定的位数个字节,应用解码器拿到的就是不带长度域的数据包;
failFast:如果为true,则表示读取到长度域,TA的值的超过maxFrameLength,就抛出一个 TooLongFrameException,而为false表示只有当真正读取完长度域的值表示的字节之后,才会抛出 TooLongFrameException,默认情况下设置为true,建议不要修改,否则可能会造成内存溢出。
LengthFieldBasedFrameDecoder定义了一个长度的字段来表示消息的长度,因此能够处理可变长度的消息。将消息分为消息头和消息体,消息头固定位置增加一个表示长度的字段,通过长度字段来获取整包的信息。LengthFieldBasedFrameDecoder继承了ByteToMessageDecoder,即转换字节这样的工作是由ByteToMessageDecoder来完成,而LengthFieldBasedFrameDecoder只用安心完成他的解码工作就好。Netty在解耦和方面确实做的不错。
对象为什么要序列化?
从java中的对象深复制中,得到了启示,将一个持久化对象转换为一个内存对象。如果不序列化,就不能恢复对象了么?其实不是,持久化对象的实质是一个二进制数组。序列化只是程序上作为标示,表明这个对象在序列化和反序列化还需要做一些什么样的补充。
java序列化的缺点:
1、压缩耗费时间长
2、压缩后数组较大
使用数组+对象流可以知道jdk序列化后的数组大小。
序列化过程的实质是对象变为流的过程。
我们通常以为将Java对象序列化成二进制比序列化成XML或Json更快,其实是错误的,如果你关心性能,建议避免Java序列化。
Java序列化有很多的要求,最主要的一个是包含能够序列化任何东西(或至少任何实现Serializable接口)。这样才能进入其他JVM之中,这很重要,所以有时性能不是主要的要求,标准的格式才最重要。
Ordr代码:
public class Order implements Serializable {
private long id;
private String description;
private BigDecimal totalCost = BigDecimal.valueOf(0);
private List orderLines = new ArrayList();
private Customer customer;
我们经常看到CPU花费很多时间内进行Java序列化,下面我们研究一下,假设一定Order,虽然只有几个字节,但是序列化以后不是几十个字节,而是600多个字节:
序列化输出:
—-sr–model.Order—-h#—–J–idL–customert–Lmodel/Customer;L–descriptiont–Ljava/lang/String;L–orderLinest–Ljava/util/List;L–totalCostt–Ljava/math/BigDecimal;xp——–ppsr–java.util.ArrayListx—–a—-I–sizexp—-w—–sr–model.OrderLine–&-1-S—-I–lineNumberL–costq-~–L–descriptionq-~–L–ordert–Lmodel/Order;xp—-sr–java.math.BigDecimalT–W–(O—I–scaleL–intValt–Ljava/math/BigInteger;xr–java.lang.Number———–xp—-sr–java.math.BigInteger—–;—–I–bitCountI–bitLengthI–firstNonzeroByteNumI–lowestSetBitI–signum[–magnitudet–[Bxq-~———————-ur–[B——T—-xp—-xxpq-~–xq-~–
正如你可能已经注意到,Java序列化写入不仅是完整的类名,也包含整个类的定义,包含所有被引用的类。类定义可以是相当大的,也许构成了性能和效率的问题,当然这是编写一个单一的对象。如果您正在编写了大量相同的类的对象,这时类定义的开销通常不是一个大问题。另一件事情是,如果你的对象有一类的引用(如元数据对象),那么Java序列化将写入整个类的定义,不只是类的名称,因此,使用Java序列化写出元数据(meta-data)是非常昂贵的。
Externalizable
通过实现Externalizable接口,这是可能优化Java序列化的。实现此接口,避免写出整个类定义,只是类名被写入。它需要你实施readExternal和writeExternal方法方法的,所以需要做一些工作,但相比仅仅是实现Serializable更快,更高效。
Externalizable对小数目对象有效的多。但是对大量对象,或者重复对象,则效率低,必须重写readExternal和writeExternal方法来知道那些属性是需要被记录的。
序列化输出:
—-sr–model.Order—*3–^—xpw———psr–java.math.BigDecimalT–W–(O—I–scaleL–intValt–Ljava/math/BigInteger;xr–java.lang.Number———–xp—-sr–java.math.BigInteger—–;—–I–bitCountI–bitLengthI–firstNonzeroByteNumI–lowestSetBitI–signum[–magnitudet–[Bxq-~———————-ur–[B——T—-xp—-xxpsr–java.util.ArrayListx—–a—-I–sizexp—-w—–sr–model.OrderLine-!!|—S—xpw—–pq-~–q-~–xxx
参考:https://blog.csdn.net/caomiao2006/article/details/51588927
序列化成XML或JSON可以允许其他语言访问,可以实现REST服务等。缺点是文本格式的效率比优化的二进制格式低一些。
Kryo
Kryo 是一种快速,高效的序列化的Java框架。 KRYO是新的BSD许可下一个开源项目提供。这是一个很小的项目,只有3名成员,它首先在2009年出品。
工作原理类似于Java序列化KRYO,尊重瞬态字段,但不要求一类是可序列化的。KRYO有一定的局限性,比如需要有一个默认的构造函数的类,在序列化将java.sql.Time java.sql.Date java.sql.Timestamp类会遇到一些问题。
order序列化结果:
——java-util-ArrayLis—–model-OrderLin—-java-math-BigDecima———model-Orde—–

相关文章推荐
- 基于jdk的网络编程和使用Netty的比较
- JAVA Socket编程学习8--为什么使用Netty
- 为什么使用apache-httpclient而不是jdk-urlconnection
- 为什么建议php字符串使用单引号而不是双引号
- org.apache.commons.collectionsJDK中不是已经有了Java集合框架了吗,为什么还要使用Apache的集合呢?
- 为什么建议使用link方式来加载css,而不是使用@import方式
- 为什么JDK源码中,无限循环大多使用for(;;)而不是while(true)?
- 我为什么选择 iBatis 而不是 Hibernate(对于正在选型的人的建议)
- 为什么使用JDBC数据库编程
- 根据网友建议,决定使用以前为初学者设计的一个编程目标和学习的顺序来书写JavaEE教程
- 为什么是C语言编程,而不是Java编程
- 使用NIO的server编程框架
- 为什么Microsoft code sample倾向使用ZeroMemory而不是{0}?
- .NET框架:为什么我们要尽量使用框架内建的功能,而不是重新发明
- 相当经典的 Vbs脚本编程简明教程之一—为什么要使用Vbs
- 在Java中使用NIO进行网络编程
- 为什么在判断中使用 "值 == 变量" 而不是 "变量 == 值"
- 面向对象设计三大原则(封装变化点,对接口进行编程,多使用组合而不是继承)
- 为什么要使用接口编程
- 我为什么选择 iBatis 而不是 Hibernate(对于正在选型的人的建议)