关于The Limitations of Deep Learning in Adversarial Settings的理解
2018-03-27 14:22
627 查看
与之前的基于提高原始类别标记的损失函数或者降低目标类别标记的损失函数的方式不同,这篇文章提出直接增加神经网络对目标类别的预测值。换句话说,之前的对抗样本的扰动方向都是损失函数的梯度方向(无论是原始类别标记的损失函数还是目标类别标记的损失函数),该论文生成的对抗样本的扰动方向是目标类别标记的预测值的梯度方向,作者将这个梯度称为前向梯度(forward derivative)。即:
∇F(X)=∂F(X)∂X=[∂Fj(X)∂xi]∇F(X)=∂F(X)∂X=[∂Fj(X)∂xi]
显然前向梯度是由神经网络的目标类别输出值对于每一个像素的偏导数组成的。这启发了我们通过检查每一个像素值对于输出的扰动,从而选择最合适的像素来进行改变。
在本文中,作者提供了一个启发式的选择方式,称为显著映射(saliency map)S(X,t)S(X,t):
S(X,t)[i]=⎧⎩⎨⎪⎪⎪⎪0if ∂Ft(X)∂Xi<0 or ∑j≠t∂Fj(X)∂Xi>0(∂Ft(X)∂Xi)∣∣∣∑j≠t∂Fj(X)∂Xi∣∣∣otherwiseS(X,t)[i]={0if ∂Ft(X)∂Xi<0 or ∑j≠t∂Fj(X)∂Xi>0(∂Ft(X)∂Xi)|∑j≠t∂Fj(X)∂Xi|otherwise
即每一步迭代选择的扰动像素都能够尽可能的增大目标类别的输出值,并且总体对其余的类别标记产生一个负影响(即减少输出值)。
但是实际的实验中发现,找到满足以上条件的像素点是很困难的,因此作者提出寻找一组像素对而不是选择单个像素点:
argmax(p1,p2)(∑i=p1,p2∂Ft(X)∂Xi)×∣∣∣∑i=p1,p2∑j≠t∂Fj(X)∂Xi∣∣∣argmax(p1,p2)(∑i=p1,p2∂Ft(X)∂Xi)×|∑i=p1,p2∑j≠t∂Fj(X)∂Xi|
具体算法如下:

这其实只是一个启发式的想法,不过由于这个组合搜索的会影响计算效率,个人感觉可能用梯度乘以可改变值作为选择目标会好:
argmaxi(∂Ft(X)∂Xi)×θiargmaxi(∂Ft(X)∂Xi)×θi
其中
θi=⎧⎩⎨⎪⎪1−Xiif ∂Ft(X)∂Xi>0Xiotherwiseθi={1−Xiif ∂Ft(X)∂Xi>0Xiotherwise
作者在实验中表明,修改小于14.29%的像素点(即对于MNIST手写识别数据,修改大约112个像素点)是不会影响人类的正确分类的。此外,论文中提出了两个有趣的质量度量方法:
1、 硬度度量:度量深度神经网络中,哪一个类别对(s,t)(s,t)(s为原始类别标记,t为目标类别标记)的扰动成功率最高,将平均失真率εε(即改变的像素点数目/总数目)相对于其成功率ττ归一化:
H(s,t)=∫τε(s,t,τ)dτH(s,t)=∫τε(s,t,τ)dτ
而在实际计算中,选择一组最大失真值ΥkΥk对应的成功率来近似计算积分:
H(s,t)≈∑k=1K−1(τk+1−τk)ε(s,t,τk+1)+ε(s,t,τk)2H(s,t)≈∑k=1K−1(τk+1−τk)ε(s,t,τk+1)+ε(s,t,τk)2
作者在实验中选择的是一组固定的最大失真度集合(K=9K=9)来计算在最大失真度情况下的扰动成功率:Υ∈{0.3,1.3,2.6,5.1,7.7,10.2,12.8,25.5,38.3}%Υ∈{0.3,1.3,2.6,5.1,7.7,10.2,12.8,25.5,38.3}%。
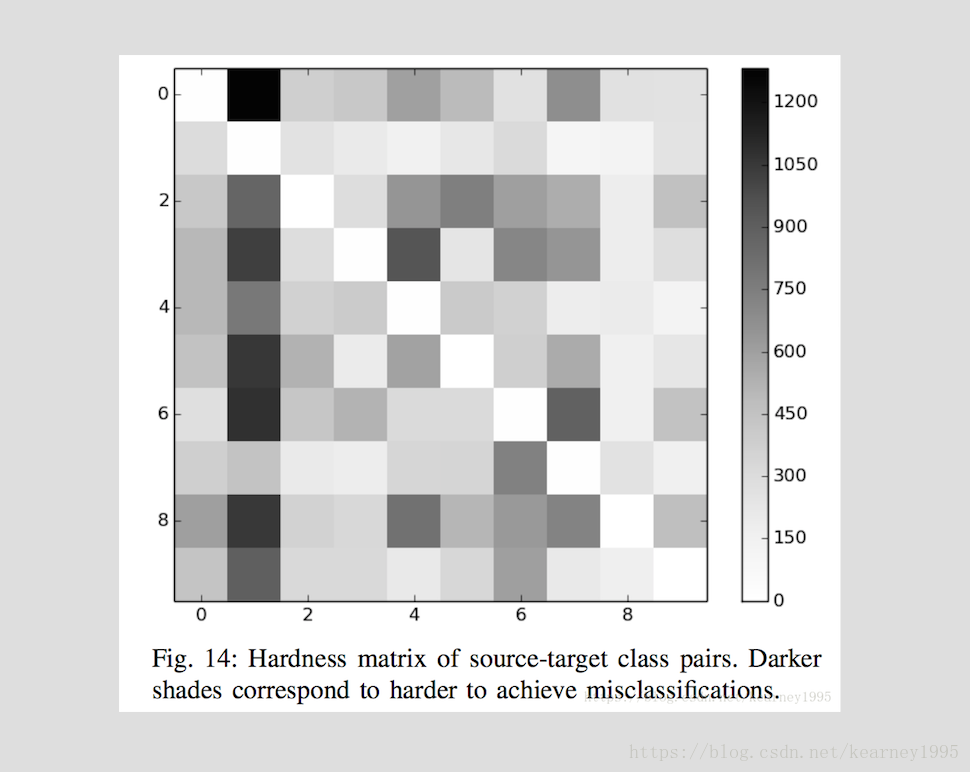
2、对抗距离:对抗距离是通过归一化Saliency map得到的:
A(X,t)=1−1M∑i∈0…MIS(X,t)[i]>0A(X,t)=1−1M∑i∈0…MIS(X,t)[i]>0
其中II是示性函数。显然对抗距离越接近1,原始样本就越难更改为目标类别标记。
此外。还有一个值得讨论的地方,就是作者指出,在他们的实验中,对抗样本的每对相邻像素之间的平方差总和总是高于原始样本。因此对于对抗样本的检测方面,也许我们可以通过评估样本的规律性来检测对抗样本。
∇F(X)=∂F(X)∂X=[∂Fj(X)∂xi]∇F(X)=∂F(X)∂X=[∂Fj(X)∂xi]
显然前向梯度是由神经网络的目标类别输出值对于每一个像素的偏导数组成的。这启发了我们通过检查每一个像素值对于输出的扰动,从而选择最合适的像素来进行改变。
在本文中,作者提供了一个启发式的选择方式,称为显著映射(saliency map)S(X,t)S(X,t):
S(X,t)[i]=⎧⎩⎨⎪⎪⎪⎪0if ∂Ft(X)∂Xi<0 or ∑j≠t∂Fj(X)∂Xi>0(∂Ft(X)∂Xi)∣∣∣∑j≠t∂Fj(X)∂Xi∣∣∣otherwiseS(X,t)[i]={0if ∂Ft(X)∂Xi<0 or ∑j≠t∂Fj(X)∂Xi>0(∂Ft(X)∂Xi)|∑j≠t∂Fj(X)∂Xi|otherwise
即每一步迭代选择的扰动像素都能够尽可能的增大目标类别的输出值,并且总体对其余的类别标记产生一个负影响(即减少输出值)。
但是实际的实验中发现,找到满足以上条件的像素点是很困难的,因此作者提出寻找一组像素对而不是选择单个像素点:
argmax(p1,p2)(∑i=p1,p2∂Ft(X)∂Xi)×∣∣∣∑i=p1,p2∑j≠t∂Fj(X)∂Xi∣∣∣argmax(p1,p2)(∑i=p1,p2∂Ft(X)∂Xi)×|∑i=p1,p2∑j≠t∂Fj(X)∂Xi|
具体算法如下:
这其实只是一个启发式的想法,不过由于这个组合搜索的会影响计算效率,个人感觉可能用梯度乘以可改变值作为选择目标会好:
argmaxi(∂Ft(X)∂Xi)×θiargmaxi(∂Ft(X)∂Xi)×θi
其中
θi=⎧⎩⎨⎪⎪1−Xiif ∂Ft(X)∂Xi>0Xiotherwiseθi={1−Xiif ∂Ft(X)∂Xi>0Xiotherwise
作者在实验中表明,修改小于14.29%的像素点(即对于MNIST手写识别数据,修改大约112个像素点)是不会影响人类的正确分类的。此外,论文中提出了两个有趣的质量度量方法:
1、 硬度度量:度量深度神经网络中,哪一个类别对(s,t)(s,t)(s为原始类别标记,t为目标类别标记)的扰动成功率最高,将平均失真率εε(即改变的像素点数目/总数目)相对于其成功率ττ归一化:
H(s,t)=∫τε(s,t,τ)dτH(s,t)=∫τε(s,t,τ)dτ
而在实际计算中,选择一组最大失真值ΥkΥk对应的成功率来近似计算积分:
H(s,t)≈∑k=1K−1(τk+1−τk)ε(s,t,τk+1)+ε(s,t,τk)2H(s,t)≈∑k=1K−1(τk+1−τk)ε(s,t,τk+1)+ε(s,t,τk)2
作者在实验中选择的是一组固定的最大失真度集合(K=9K=9)来计算在最大失真度情况下的扰动成功率:Υ∈{0.3,1.3,2.6,5.1,7.7,10.2,12.8,25.5,38.3}%Υ∈{0.3,1.3,2.6,5.1,7.7,10.2,12.8,25.5,38.3}%。
2、对抗距离:对抗距离是通过归一化Saliency map得到的:
A(X,t)=1−1M∑i∈0…MIS(X,t)[i]>0A(X,t)=1−1M∑i∈0…MIS(X,t)[i]>0
其中II是示性函数。显然对抗距离越接近1,原始样本就越难更改为目标类别标记。
此外。还有一个值得讨论的地方,就是作者指出,在他们的实验中,对抗样本的每对相邻像素之间的平方差总和总是高于原始样本。因此对于对抗样本的检测方面,也许我们可以通过评估样本的规律性来检测对抗样本。

相关文章推荐
- 《The Frontiers of Memory and Attention in Deep Learning》 图文结合详解深度学习Memory & Attention
- [深度学习论文笔记][Weight Initialization] Exact solutions to the nonlinear dynamics of learning in deep lin
- The development and prosperous of deep learning theory applying in computer vision(Image part)
- 论文阅读笔记:Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey
- The Future of Real-Time SLAM and Deep Learning vs SLAM
- 论文笔记 Ensemble of Deep Convolutional Neural Networks for Learning to Detect Retinal Vessels in Fundus
- 关于Location of the Android SDK has not been setup in the preferences的解决方法
- The Future of Real-Time SLAM and "Deep Learning vs SLAM"
- 关于error:Cannot assign to 'self' outside of a method in the init family
- Rupture of deep faults in the 2008 Wenchuan earthquake and uplift of the Longmen Shan
- deep-learning-with-python --the author of keres
- 浅谈深度学习中的激活函数 - The Activation Function in Deep Learning
- Homepage Machine Learning Algorithm 浅谈深度学习中的激活函数 - The Activation Function in Deep Learning
- 关于error:Cannot assign to 'self' outside of a method in the init family
- How to resolve errors opening currentsettings.vssettings in the final release of VS 2008
- Deep Learning Face Attributes in the Wild
- 泛读:CVPR2014:Discriminative Deep Metric Learning for Face Verification in theWild
- Rolling in the Deep (Learning)
- 2015年深度学习淘金热 The Deep Learning Gold Rush of 2015
- Yoshua Bengio等大神传授:26条深度学习经验26 Things I Learned in the Deep Learning Summer School