Deep Learning Face Attributes in the Wild
2015-01-09 11:43
627 查看

文章要解决的问题
Predicting face attributes from web images
方法的主要想法
It cascades two CNNs (LNet and ANet) forface localization and attribute prediction respectively.
贡献(吹牛逼)
(1) It shows how LNet and ANet can be improved by different pre-trainingstrategies.
(2) It reveals that although filters of LNet are fine-tuned by attributelabels, their response maps over the entire image have strong indication offace’s location.
(3)It also demonstrates that the high-level hidden neurons of ANetautomatically discover semantic concepts after pretraining, and such concepts aresignificantly enriched
after fine-tuning.
pre-train andfine-tuned
LNet and ANet are first pretrained differently and then jointly trainedwith attribute labels.
LNet is pre-trained by classifying massive general object categories.Thus, its pre-trained features have good generalization capability on handlingvarious background clutters.
LNet is then fine-tuned by predicting attributes.
ANet is pre-trained by classifying massive face identities, to obtaindiscriminative face representation. Then it is fine-tuned by the attributeprediction task.
Pre-train的原因和人脸定位的理论:
A filter (or a group of filters) functions as a detector of an attribute. Whena subset of neurons are activated, they indicate the existence of face images,which have a particular
attribute configuration. The neurons at differentlayers can form many activation patterns, implying that the whole set of face imagescan be divided into many subsets based on attribute configurations, and eachactivation pattern corresponds to one subset (e.g.
‘pointy nose’, ‘rosy cheek’, and‘smiling’). Therefore, it is not surprising that filters learned by attribute predictionlead to effective representations for face localization. By simply averagingand thresholding response maps, good face localization is achieved.
With this strategy, each face attribute is well explained by a sparselinear combination of these sematic concepts. By analyzing the coefficients ofsuch combinations, attributes
show clear grouping patterns, which could be wellinterpreted semantically.
Structure Of Framework
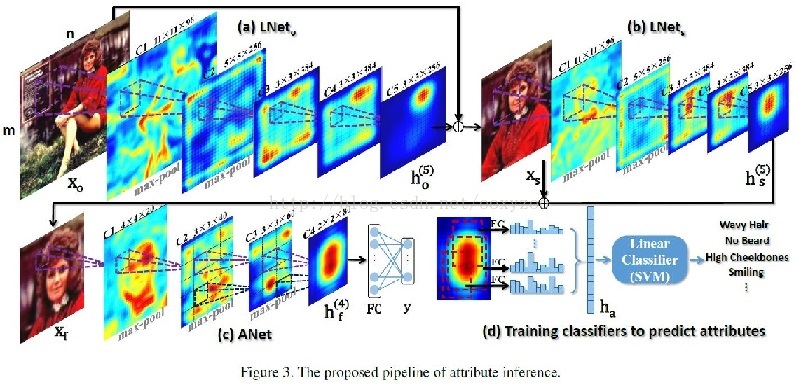

再加上最后的SVM分类器,一共四个过程
1 LNeto定位头部和肩部

2 LNets定位脸(更准确的定位)

3 ANet表达和预测人脸特性
这个只有一个FC,所以只有一个Attribute(这妈蛋的就是接着好玩,坑爹)。训练网络时有用,预测时没用。

4 SVM人脸特征分类
这个分类出来的是Attributes的线性组合(因为有多组FC)

Framework内部说明(此处运用了参数局部共享和全局共享的混合策略)


本人不懂局部共享,以下是文献,请参考之
参数局部分享文章:

开始慢慢一点点往后面看详细介绍
3.1.Coarse-to-fine Face Localization
设计了一个公式搞出人脸部分,但是作者说这个有待以后搞得更准确


3.2.Feature Extraction
未阅读
4.Learning
Algorithms
介绍预训练和微调
LNet+先用大量的普遍的目标分类预训练(ILSVRC),两个LNet再用打了标签图(Xo,Xs)微调
Theconvolutional
structures (C1 to C5) of LNet+ is designed in the same way asLNeto and LNets. We add two fully-connected hidden layers on top of C5 in orderto improve the non-linearity for classification.
All
the filters ofLNeto andLNets
areinitialized by LNet+ after pre-training.
LNeto
adopts the full image xoas
input
LNets
uses the the image of head-shoulder
xsas input
we
add twofully-connected layers to both LNeto
and LNets, where the weight matrices are initialized randomly.
ANet先用大量的人脸验证预训练,再用打了标签的人脸图(Xf)微调
ANet
employs theestimated face region xf
as input
文章后面再大概的随意看了看,重要概念在下面罗列
1
SVM人脸属性线性组合分类理论基础
The pre-training ofANet essentially discovers semantic concepts related to identity.
The attributespresented in each test image is explained by a sparse linear combination ofthese concepts.
(例子)For instance, thefirst image is described by “a lady with big bang, brown hair, pale skin,narrow eyes, and high cheekbone”, which completely matches
the human perception.
FC搞局部的理论基础
Different
attributescapture information from different regions of face. We show that ANet automaticallylearn to discover these regions.

相关文章推荐
- Deep Learning Face Attributes in the Wild
- Deep Learning Face Attributes in the Wild
- 泛读:CVPR2014:Discriminative Deep Metric Learning for Face Verification in theWild
- Discriminative Deep Metric Learning for Face Verification in the Wild(文献泛读)
- Learning Face Hallucination in the Wild--阅读笔记
- 17.2.22 Pose-Aware Face Recognition in the Wild 小感
- The development and prosperous of deep learning theory applying in computer vision(Image part)
- [深度学习论文笔记][Weight Initialization] Exact solutions to the nonlinear dynamics of learning in deep lin
- The major advancements in Deep Learning in 2016
- Pose-Aware Face Recognition in the Wild--填坑1
- The Activation Function in Deep Learning 浅谈深度学习中的激活函数
- Rolling in the Deep (Learning)
- DeepFace: Closing the Gap to Human-Level Performance in Face Verification
- (转) The major advancements in Deep Learning in 2016
- High-Fidelity Pose and Expression Normalization for Face Recognition in the Wild
- 论文提要“DeepFace: Closing the Gap to Human-Level Performance in Face Verification”
- FaceBook 论文:DeepFace: Closing the Gap to Human-Level Performance in Face Verification 笔记
- DeepFace: Closing the Gap to Human-Level Performance in Face Verification
- 26 THINGS I LEARNED IN THE DEEP LEARNING SUMMER SCHOOL
- Yoshua Bengio等大神传授:26条深度学习经验26 Things I Learned in the Deep Learning Summer School