python数据分析系列教程(3) —— Pandas模块1
2018-03-26 20:50
597 查看
目录一.Pandas简介
二.主要数据结构
1.Series
2.DataFrame
三.Series基本操作
pandas主要提出了两个重要的数据结构:Series和DataFrame,并在此基础上提供了大量快速便捷进行数据处理的函数和方法,通过使用这些数据结构可以弥补一些numpy的不足,能更加适合进行数据处理。
(2)使用pandas可以更高效的实现以下功能:
*具备能按轴自动或显式数据对齐功能的数据结构。
*集成和处理时间序列的功能。
*适合对金融数据处理,可以通过对元数据(轴编号)进行数据运算和约简(比如按轴求和)来实现对结构内数据的计算。
*灵活进行数据清洗和残缺数据处理。
*合并和实现常见数据库中的关系型运算。
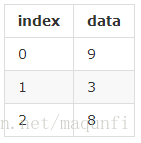
(1)Series是有一组数据和相应标签组成的数据组合,类似于字典,其组合是索引在前面、值在右边,如图的两种形式。

创建Series的代码为:from pandas import Series,DataFrame
import pandas as pd
#简单无标记的Series
obj=Series([4,7,-5,3]) #创建一组数据,未指定标记时,默认是序号有小到大排的
print(obj)
'''
0 4
1 7
2 -5
3 3
dtype: int64
'''
#有标记的Series
obj=Series(data=[4,2,9,-32],index=['b','a','w','r'])#创建一组数据,并指定标记
print(obj)
''' 输出:
b 4
a 2
w 9
r -32
dtype: int64
'''
#使用字典创建Series
sdata={'or':2,'ge':3,'gd':54,'js':65}
obj2=Series(sdata)
print(obj2)
''' 输出:
gd 54
ge 3
js 65
or 2
dtype: int64
'''
(2)DataFrame是表格型的二维的数据结构,其内部每列可以使不同的值类型(数值、字符串、布尔型),列之间类型可以不同,但每一列内部需要类型相同,类似下面的结构,圈定的每一列都是不同的数据类型。
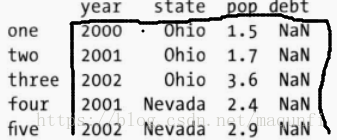
与Series相比,DataFrame既有行索引也有列索引,他可以被看为由Series组成的字典(Series是单标识的),其内部是由一个或多个二维块组成的,如图是通过列和横向索引来确定表格中的一个位置(双标识)。

在创建DataFrame是,可以接受的创建方式为:

创建DataFrame代码:#创建方法一, 直接使用字典的方式创建DataFrame,直接创建,会自动添加索引来有序排序
data={"A":[1,2,3,4],"B":[5,6,7,8],"C":[1,1,1,1]}
frame=pd.DataFrame(data)
print(df1)
''' 输出
A B C
0 1 5 1
1 2 6 1
2 3 7 1
3
98ee
4 8 1
'''
#创建方式二,指定双索引的创建方式
frame1=pd.DataFrame(data,columns=['A','B','C'],index=['one','get','buy','you']) #指定column和index,但是标识要跟数据尺寸匹配
print(frame1)
'''输出
A B C
one 1 5 1
get 2 6 1
buy 3 7 1
you 4 8 1
'''
二.主要数据结构
1.Series
2.DataFrame
三.Series基本操作
一.pandas简介
(1)pandas是基于numpy的一种为了解决数据分析任务而创建的模块,使用pandas可以让数据分析工作更便捷,他与numpy的区别是:numpy是数值计算的扩展包,pandas是专门用来数据处理的。pandas主要提出了两个重要的数据结构:Series和DataFrame,并在此基础上提供了大量快速便捷进行数据处理的函数和方法,通过使用这些数据结构可以弥补一些numpy的不足,能更加适合进行数据处理。
(2)使用pandas可以更高效的实现以下功能:
*具备能按轴自动或显式数据对齐功能的数据结构。
*集成和处理时间序列的功能。
*适合对金融数据处理,可以通过对元数据(轴编号)进行数据运算和约简(比如按轴求和)来实现对结构内数据的计算。
*灵活进行数据清洗和残缺数据处理。
*合并和实现常见数据库中的关系型运算。
二.主要数据结构
pandas中主要提出了两个数据结构:Series和DataFrame,这两种数据结构与numpy中array最大的区别是可以像字典那样指定标记,所以更加适合存储和处理表格类型(特征和特征值)的数据。(1)Series是有一组数据和相应标签组成的数据组合,类似于字典,其组合是索引在前面、值在右边,如图的两种形式。
创建Series的代码为:from pandas import Series,DataFrame
import pandas as pd
#简单无标记的Series
obj=Series([4,7,-5,3]) #创建一组数据,未指定标记时,默认是序号有小到大排的
print(obj)
'''
0 4
1 7
2 -5
3 3
dtype: int64
'''
#有标记的Series
obj=Series(data=[4,2,9,-32],index=['b','a','w','r'])#创建一组数据,并指定标记
print(obj)
''' 输出:
b 4
a 2
w 9
r -32
dtype: int64
'''
#使用字典创建Series
sdata={'or':2,'ge':3,'gd':54,'js':65}
obj2=Series(sdata)
print(obj2)
''' 输出:
gd 54
ge 3
js 65
or 2
dtype: int64
'''
(2)DataFrame是表格型的二维的数据结构,其内部每列可以使不同的值类型(数值、字符串、布尔型),列之间类型可以不同,但每一列内部需要类型相同,类似下面的结构,圈定的每一列都是不同的数据类型。
与Series相比,DataFrame既有行索引也有列索引,他可以被看为由Series组成的字典(Series是单标识的),其内部是由一个或多个二维块组成的,如图是通过列和横向索引来确定表格中的一个位置(双标识)。
在创建DataFrame是,可以接受的创建方式为:
创建DataFrame代码:#创建方法一, 直接使用字典的方式创建DataFrame,直接创建,会自动添加索引来有序排序
data={"A":[1,2,3,4],"B":[5,6,7,8],"C":[1,1,1,1]}
frame=pd.DataFrame(data)
print(df1)
''' 输出
A B C
0 1 5 1
1 2 6 1
2 3 7 1
3
98ee
4 8 1
'''
#创建方式二,指定双索引的创建方式
frame1=pd.DataFrame(data,columns=['A','B','C'],index=['one','get','buy','you']) #指定column和index,但是标识要跟数据尺寸匹配
print(frame1)
'''输出
A B C
one 1 5 1
get 2 6 1
buy 3 7 1
you 4 8 1
'''
三.Series基本操作
创建Series的代码为:
相关文章推荐
- Python数据分析模块 | pandas做数据分析(二):常用预处理操作
- Python数据分析模块 | pandas做数据分析(三):统计相关函数
- python pandas做数据分析视图分析matplotlib,seaborn模块使用
- Python数据分析库Pandas教程——简介
- Python数据分析模块 | pandas做数据分析(一):基本数据对象
- python数据存储系列教程——python(pandas)读写csv文件
- python数据分析系列教程——NumPy全解
- 【量化小讲堂-Python&Pandas系列01】如何快速上手使用Python进行金融数据分析
- 【Python】Python的数据分析(二)——pandas安装及使用
- 快速学习 Python 数据分析包 之 pandas
- Python 数据分析:pandas 操作基础篇
- Python 数据分析(一) 本实验将学习 pandas 基础,数据加载、存储与文件格式,数据规整化,绘图和可视化的知识
- 【Python】Python的数据分析(二)——pandas安装及使用
- Python 循序渐进教程系列 之基础02 基础数据类型
- Python 数据分析包:pandas 基础
- Python 数据分析-pandas 基础
- 超强教程:教你用Python语言分析引力波数据
- Python运用于数据分析的简单教程
- 在Python中使用zlib模块进行数据压缩的教程
- 利用python进行数据分析之pandas库的应用(一)