[置顶] 【python 百度文字识别】通用文字识别(高精度版)
2018-03-09 17:20
621 查看
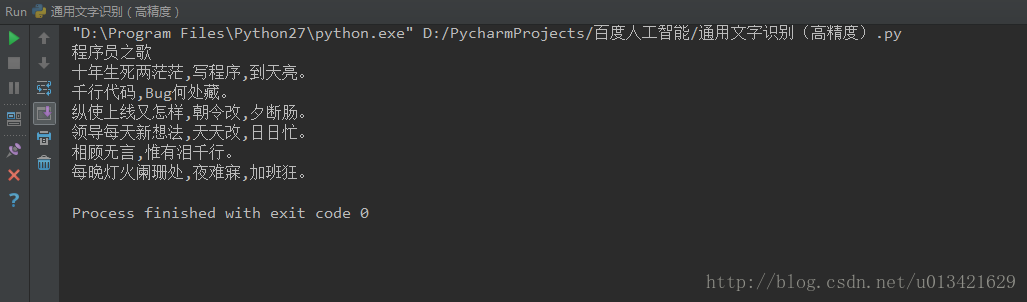
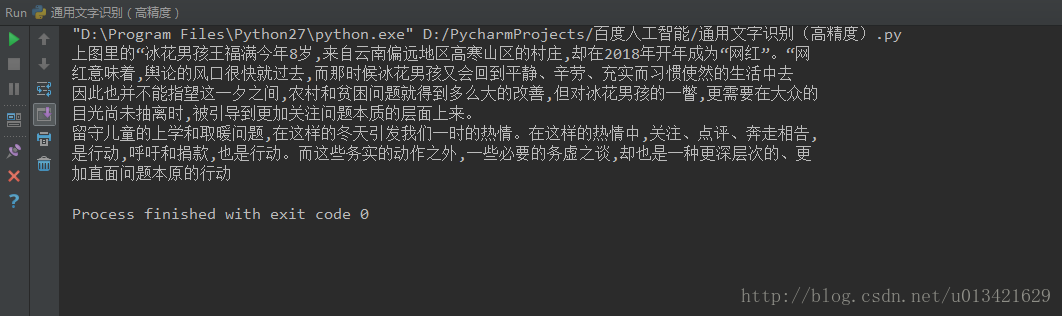
效果展示:
效果非常好~~~~


创建应用
首先你需要登录百度AI,选择文字识别,创建一个应用,会生成 应用名称、AppID、API Key、Secret Key 这些东西,下面我们代码是需要用到API_Key 和 Secret_Key 生成access_token。
python代码:
效果非常好~~~~
创建应用
首先你需要登录百度AI,选择文字识别,创建一个应用,会生成 应用名称、AppID、API Key、Secret Key 这些东西,下面我们代码是需要用到API_Key 和 Secret_Key 生成access_token。
python代码:
# encoding: utf-8
import time
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
time1 = time.time()
import urllib, urllib2, base64
import json
import re
def get_token(API_Key,Secret_Key):
# 获取access_token
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id='+API_Key+'&client_secret='+Secret_Key
request = urllib2.Request(host)
request.add_header('Content-Type', 'application/json; charset=UTF-8')
response = urllib2.urlopen(request)
content = response.read()
content_json=json.loads(content)
access_token=content_json['access_token']
return access_token
def recognition_word_high(filepath,filename,access_token):
url='https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic?access_token=' + access_token
# 二进制方式打开图文件
f = open(filepath + filename, 'rb') # 二进制方式打开图文件
# 参数image:图像base64编码
img = base64.b64encode(f.read())
params = {"image": img}
params = urllib.urlencode(params)
request = urllib2.Request(url, params)
request.add_header('Content-Type', 'application/x-www-form-urlencoded')
response = urllib2.urlopen(request)
content = response.read()
if (content):
# print(content)
world=re.findall('"words": "(.*?)"}',str(content),re.S)
for each in world:
print each
if __name__ == '__main__':
API_Key = "****************************"
Secret_Key = "*****************************"
filepath = "E:/ID/"
filename="59.jpg"
access_token=get_token(API_Key,Secret_Key)
recognition_word_high=recognition_word_high(filepath,filename,access_token)

相关文章推荐
- 基于百度AI的文字识别-Python
- 【Python3-API】通用文字识别示例代码
- Python 3调用百度OCR API实现剪贴板文字识别
- python 3调用百度OCR API实现剪贴板文字识别
- Python基于百度AI的文字识别的示例
- python实战===百度文字识别sdk
- [置顶] Android平台上实现身份证识别(通过阿里云Api-印刷文字识别_身份证识别)
- [置顶] 【python 图像识别】python 身份证号码识别
- Python图像处理之识别图像中的文字(实例讲解)
- 调用百度AI实现人脸识别-Python
- Linux python PyQt5调用百度API实现图片文字转换
- 在win10(64位)系统下实现python的文字识别功能
- Python 通过 百度 rest 进行 语音翻译成中文文字。
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
- Python 利用pytesser模块识别图像文字
- 百度AI实现图片转文字-python
- 图像识别API Python 指定文件夹图片内容转化为文字
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(1)
- [置顶] 百度ai—细粒度图像识别
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)