机器学习速成课程MLCC(5)--正则化
2018-03-07 21:59
260 查看
L2正则化预计用时:7 分钟请查看以下泛化曲线,该曲线显示的是训练集和验证集相对于训练迭代次数的损失
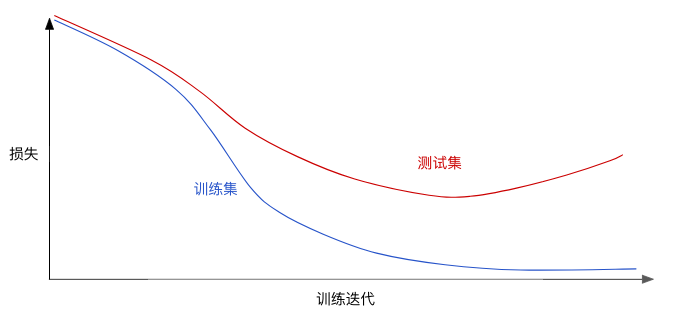
图 1. 训练集和验证集损失。图 1 显示的是某个模型的训练损失逐渐减少,但验证损失最终增加。换言之,该泛化曲线显示该模型与训练集中的数据过拟合。根据奥卡姆剃刀定律,或许我们可以通过降低复杂模型的复杂度来防止过拟合,这种原则称为正则化。也就是说,并非只是以最小化损失(经验风险最小化)为目标:minimize(Loss(Data|Model))而是以最小化损失和复杂度为目标,这称为结构风险最小化:minimize(Loss(Data|Model) + complexity(Model))现在,我们的训练优化算法是一个由两项内容组成的函数:一个是损失项,用于衡量模型与数据的拟合度,另一个是正则化项,用于衡量模型复杂度。机器学习速成课程重点介绍了两种衡量模型复杂度的常见方式(这两种方式有些相关):将模型复杂度作为模型中所有特征的权重的函数。
将模型复杂度作为具有非零权重的特征总数的函数。
如果模型复杂度是权重的函数,则特征权重的绝对值越高,模型就越复杂。我们可以使用 L2 正则化公式来量化复杂度,该公式将正则化项定义为所有特征权重的平方和:L2 regularization term=||w||22=w12+w22+...+wn2在这个公式中,接近于 0 的权重对模型复杂度几乎没有影响,而离群值权重则可能会产生巨大的影响。例如,某个线性模型具有以下权重:{w1=0.2,w2=0.5,w3=5,w4=1,w5=0.25,w6=0.75}L2 正则化项为 26.915:w12+w22+w32+w42+w52+w62=0.22+0.52+52+12+0.252+0.752=0.04+0.25+25+1+0.0625+0.5625=26.915但是 w3(上述加粗内容)的平方值为 25,几乎贡献了全部的复杂度。所有 5 个其他权重的平方和对 L2正则化项的贡献仅为 1.915L1正则化预计用时:5 分钟稀疏矢量通常包含许多维度。创建特征组合会导致包含更多维度。由于使用此类高维度特征矢量,因此模型可能会非常庞大,并且需要大量的 RAM。在高维度稀疏矢量中,最好尽可能使权重正好降至0。正好为 0 的权重基本上会使相应特征从模型中移除。 将特征设为 0 可节省 RAM 空间,且可以减少模型中的噪点。以一个涵盖全球地区(不仅仅只是涵盖加利福尼亚州)的住房数据集为例。如果按分(每度为 60 分)对全球纬度进行分桶,则在一次稀疏编码过程中会产生大约 1 万个维度;如果按分对全球经度进行分桶,则在一次稀疏编码过程中会产生大约 2 万个维度。这两种特征的特征组合会产生大约 2 亿个维度。这 2 亿个维度中的很多维度代表非常有限的居住区域(例如海洋里),很难使用这些数据进行有效泛化。 若为这些不需要的维度支付 RAM 存储费用就太不明智了。 因此,最好是使无意义维度的权重正好降至 0,这样我们就可以避免在推理时支付这些模型系数的存储费用。我们或许可以添加适当选择的正则化项,将这种想法变成在训练期间解决的优化问题。L2 正则化能完成此任务吗?遗憾的是,不能。 L2 正则化可以使权重变小,但是并不能使它们正好为 0.0。另一种方法是尝试创建一个正则化项,减少模型中的非零系数值的计数。只有在模型能够与数据拟合时增加此计数才有意义。 遗憾的是,虽然这种基于计数的方法看起来很有吸引力,但它会将我们的凸优化问题变为非凸优化问题,即NP困难。 (如果您仔细观察,便会发现它与背包问题关联。) 因此,L0 正则化这种想法在实践中并不是一种有效的方法。不过,L1 正则化这种正则化项的作用类似 L0,但它具有凸优化的优势,可有效进行计算。因此,我们可以使用 L1 正则化使模型中很多信息缺乏的系数正好为 0,从而在推理时节省 RAM。
L1 会降低 |权重|。
因此,L2 和 L1 具有不同的导数:L2 的导数为 2 * 权重。
L1 的导数为 k(一个常数,其值与权重无关)。
您可以将 L2 的导数的作用理解为每次移除权重的 x%。如Zeno所知,对于任意数字,即使按每次减去 x% 的幅度执行数十亿次减法计算,最后得出的值也绝不会正好为 0。(Zeno 不太熟悉浮点精度限制,它可能会使结果正好为 0。)总而言之,L2 通常不会使权重变为 0。您可以将 L1 的导数的作用理解为每次从权重中减去一个常数。不过,由于减去的是绝对值,L1 在 0 处具有不连续性,这会导致与 0 相交的减法结果变为 0。例如,如果减法使权重从 +0.1 变为 -0.2,L1 便会将权重设为 0。就这样,L1 使权重变为 0 了。L1 正则化 - 减少所有权重的绝对值 - 证明对宽度模型非常有效。请注意,该说明适用于一维模型。。
图 1. 训练集和验证集损失。图 1 显示的是某个模型的训练损失逐渐减少,但验证损失最终增加。换言之,该泛化曲线显示该模型与训练集中的数据过拟合。根据奥卡姆剃刀定律,或许我们可以通过降低复杂模型的复杂度来防止过拟合,这种原则称为正则化。也就是说,并非只是以最小化损失(经验风险最小化)为目标:minimize(Loss(Data|Model))而是以最小化损失和复杂度为目标,这称为结构风险最小化:minimize(Loss(Data|Model) + complexity(Model))现在,我们的训练优化算法是一个由两项内容组成的函数:一个是损失项,用于衡量模型与数据的拟合度,另一个是正则化项,用于衡量模型复杂度。机器学习速成课程重点介绍了两种衡量模型复杂度的常见方式(这两种方式有些相关):将模型复杂度作为模型中所有特征的权重的函数。
将模型复杂度作为具有非零权重的特征总数的函数。
如果模型复杂度是权重的函数,则特征权重的绝对值越高,模型就越复杂。我们可以使用 L2 正则化公式来量化复杂度,该公式将正则化项定义为所有特征权重的平方和:L2 regularization term=||w||22=w12+w22+...+wn2在这个公式中,接近于 0 的权重对模型复杂度几乎没有影响,而离群值权重则可能会产生巨大的影响。例如,某个线性模型具有以下权重:{w1=0.2,w2=0.5,w3=5,w4=1,w5=0.25,w6=0.75}L2 正则化项为 26.915:w12+w22+w32+w42+w52+w62=0.22+0.52+52+12+0.252+0.752=0.04+0.25+25+1+0.0625+0.5625=26.915但是 w3(上述加粗内容)的平方值为 25,几乎贡献了全部的复杂度。所有 5 个其他权重的平方和对 L2正则化项的贡献仅为 1.915L1正则化预计用时:5 分钟稀疏矢量通常包含许多维度。创建特征组合会导致包含更多维度。由于使用此类高维度特征矢量,因此模型可能会非常庞大,并且需要大量的 RAM。在高维度稀疏矢量中,最好尽可能使权重正好降至0。正好为 0 的权重基本上会使相应特征从模型中移除。 将特征设为 0 可节省 RAM 空间,且可以减少模型中的噪点。以一个涵盖全球地区(不仅仅只是涵盖加利福尼亚州)的住房数据集为例。如果按分(每度为 60 分)对全球纬度进行分桶,则在一次稀疏编码过程中会产生大约 1 万个维度;如果按分对全球经度进行分桶,则在一次稀疏编码过程中会产生大约 2 万个维度。这两种特征的特征组合会产生大约 2 亿个维度。这 2 亿个维度中的很多维度代表非常有限的居住区域(例如海洋里),很难使用这些数据进行有效泛化。 若为这些不需要的维度支付 RAM 存储费用就太不明智了。 因此,最好是使无意义维度的权重正好降至 0,这样我们就可以避免在推理时支付这些模型系数的存储费用。我们或许可以添加适当选择的正则化项,将这种想法变成在训练期间解决的优化问题。L2 正则化能完成此任务吗?遗憾的是,不能。 L2 正则化可以使权重变小,但是并不能使它们正好为 0.0。另一种方法是尝试创建一个正则化项,减少模型中的非零系数值的计数。只有在模型能够与数据拟合时增加此计数才有意义。 遗憾的是,虽然这种基于计数的方法看起来很有吸引力,但它会将我们的凸优化问题变为非凸优化问题,即NP困难。 (如果您仔细观察,便会发现它与背包问题关联。) 因此,L0 正则化这种想法在实践中并不是一种有效的方法。不过,L1 正则化这种正则化项的作用类似 L0,但它具有凸优化的优势,可有效进行计算。因此,我们可以使用 L1 正则化使模型中很多信息缺乏的系数正好为 0,从而在推理时节省 RAM。
L1 和 L2 正则化。
L2 和 L1 采用不同的方式降低权重:L2 会降低权重2。L1 会降低 |权重|。
因此,L2 和 L1 具有不同的导数:L2 的导数为 2 * 权重。
L1 的导数为 k(一个常数,其值与权重无关)。
您可以将 L2 的导数的作用理解为每次移除权重的 x%。如Zeno所知,对于任意数字,即使按每次减去 x% 的幅度执行数十亿次减法计算,最后得出的值也绝不会正好为 0。(Zeno 不太熟悉浮点精度限制,它可能会使结果正好为 0。)总而言之,L2 通常不会使权重变为 0。您可以将 L1 的导数的作用理解为每次从权重中减去一个常数。不过,由于减去的是绝对值,L1 在 0 处具有不连续性,这会导致与 0 相交的减法结果变为 0。例如,如果减法使权重从 +0.1 变为 -0.2,L1 便会将权重设为 0。就这样,L1 使权重变为 0 了。L1 正则化 - 减少所有权重的绝对值 - 证明对宽度模型非常有效。请注意,该说明适用于一维模型。。

相关文章推荐
- 机器学习速成课程MLCC(1)--机器学习主要术语
- 机器学习速成课程MLCC(2)--深入了解机器学习 (Descending into ML)
- 机器学习速成课程MLCC(4)--使用TensorFlow的基本步骤
- 机器学习速成课程MLCC(10)--训练神经网络(编程练习)
- Google---机器学习速成课程(十一)- 稀疏性正则化 (Regularization for Sparsity)
- Google---机器学习速成课程(3.1)-TF/Pandas
- 机器学习速成课程笔记9:降低损失 (Reducing Loss)-Playground 练习
- (斯坦福机器学习课程笔记)正则化和机器学习应用的建议
- 机器学习速成课程笔记4:降低损失 (Reducing Loss)
- 机器学习速成课程笔记10:使用TF的基本步骤
- Google---机器学习速成课程(3.3)-合成特征和离群值
- Google---机器学习速成课程(五)-测试集/训练集/验证集Training Test and Validation Sets
- Coursera 机器学习(by Andrew Ng)课程学习笔记 Week 3——逻辑回归、过拟合与正则化
- Google---机器学习速成课程(四)-泛化Generalization
- 机器学习速成课程笔记5:降低损失 (Reducing Loss)-梯度下降法
- 机器学习速成课程笔记6:降低损失 (Reducing Loss)-学习速率
- 学习了!谷歌今日上线基于TensorFlow的机器学习速成课程(中文版)
- 机器学习速成课程学习讲义1
- 全程中文:谷歌上线机器学习速成课程
- 机器学习速成课程MLCC(6)--测试集与训练集