实战Python爬取拉勾网职位数据
2018-03-07 13:58
621 查看
文章来源:http://www.51testing.com/html/21/n-3724921.html今天写的这篇文章是关于python爬虫简单的一个使用,选取的爬取对象是著名的招聘网站——拉钩网,由于和大家的职业息息相关,所以爬取拉钩的数据进行分析,对于职业规划和求职时的信息提供有很大的帮助。

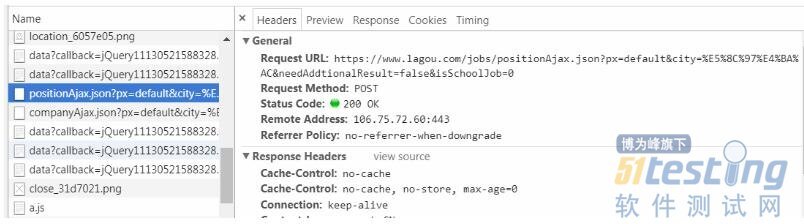
不要气馁,我们接着往下找,可以看到一个“positionAjax”开头的请求,没错就它“https://www.lagou.com/jobs/positionAjax.jsonpx=default&city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false&isSchoolJob=0”,还是看图说话吧
找到请求地址之后,我们就开始写代码了。先是导入requests和pymysql,然后requests的post方法访问上面找到的url,但是直接访问这个地址是会被拦截的,因为我们缺少所要传输的数据,和设置请求头,会被认为是非自然人请求的,加入请求头和数据,
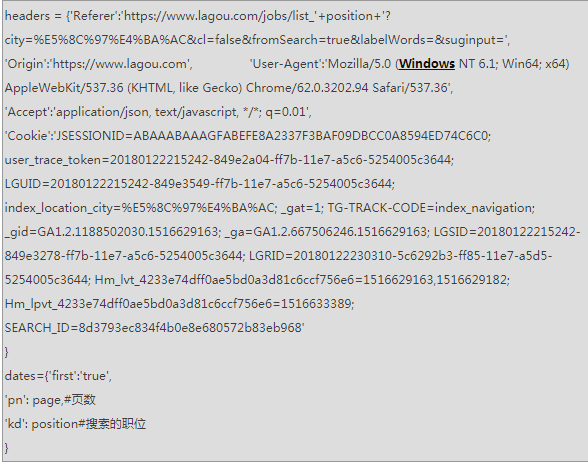
加入请求头之后就可以请求了,控制台输出数据,可以看出是一个json数据,使用json方法处理之后,一步步找到我们想要的数据,可以看出全在“result”里面,那么我们就只拿到他就行了,result=resp.json()['content']['positionResult']['result']这个时候可以看到数据非常多,有30个左右,不过不用担心,都是英文单词,基本上可以才出意思。接下来我们就要怕这些数据存储到数据库中,以备日后分析使用。连接mysql我使用的是pymysql,先建好数据库和数据表,然后在代码中加入配置信息
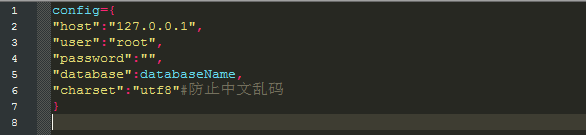
加载配置文件,连接数据库
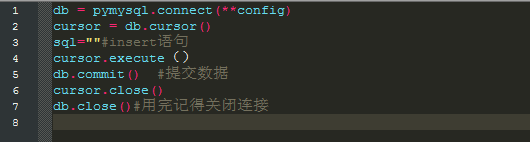
大功告成,这个时候拉钩的职位信息已经静静地躺在了你的数据库中,静待你的宠幸,拿到这些数据,你就可以进行一些分析了,比如平均工资水平、职位技能要求等。因为篇幅有限,有些代码并没有粘贴出来,比如sql语句(这个sql写的挺长的),但是别担心,楼主已经把这个程序放入到github上面了,大家可以自行下载,github地址:https://github.com/wudb1993/pythonDemo,手打不易谢谢啦,欢迎大神拍砖。
文章来源:http://www.51testing.com/html/21/n-3724921.html今天写的这篇文章是关于python爬虫简单的一个使用,选取的爬取对象是著名的招聘网站——拉钩网,由于和大家的职业息息相关,所以爬取拉钩的数据进行分析,对于职业规划和求职时的信息提供有很大的帮助。
不要气馁,我们接着往下找,可以看到一个“positionAjax”开头的请求,没错就它“https://www.lagou.com/jobs/positionAjax.jsonpx=default&city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false&isSchoolJob=0”,还是看图说话吧
找到请求地址之后,我们就开始写代码了。先是导入requests和pymysql,然后requests的post方法访问上面找到的url,但是直接访问这个地址是会被拦截的,因为我们缺少所要传输的数据,和设置请求头,会被认为是非自然人请求的,加入请求头和数据,
加入请求头之后就可以请求了,控制台输出数据,可以看出是一个json数据,使用json方法处理之后,一步步找到我们想要的数据,可以看出全在“result”里面,那么我们就只拿到他就行了,result=resp.json()['content']['positionResult']['result']这个时候可以看到数据非常多,有30个左右,不过不用担心,都是英文单词,基本上可以才出意思。接下来我们就要怕这些数据存储到数据库中,以备日后分析使用。连接mysql我使用的是pymysql,先建好数据库和数据表,然后在代码中加入配置信息
加载配置文件,连接数据库
大功告成,这个时候拉钩的职位信息已经静静地躺在了你的数据库中,静待你的宠幸,拿到这些数据,你就可以进行一些分析了,比如平均工资水平、职位技能要求等。因为篇幅有限,有些代码并没有粘贴出来,比如sql语句(这个sql写的挺长的),但是别担心,楼主已经把这个程序放入到github上面了,大家可以自行下载,github地址:https://github.com/wudb1993/pythonDemo,手打不易谢谢啦,欢迎大神拍砖。
完成的效果
爬取数据只是第一步,怎样使用和分析数据也是一大重点,当然这不是本次博客的目的,由于本次只是一个上手的爬虫程序,所以我们的最终目的只是爬取到拉钩网的职位信息,然后保存到Mysql数据库中。最后中的效果示意图如下:准备工作
首先需要安装python,这个网上已经有很多的教程了,这里就默认已经安装python,博主使用的是python3.6,然后安装了requests、pymysql(连接数据库使用)和Mysql数据库。分析拉勾网
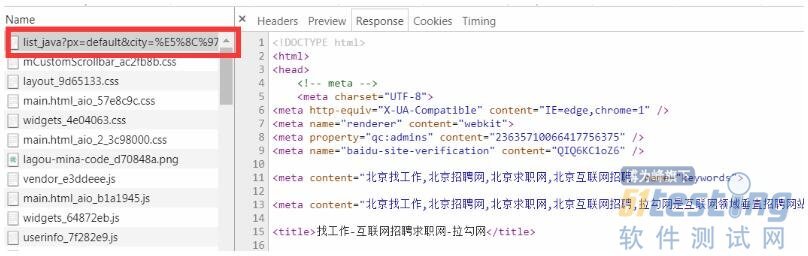
首先我们打开拉勾网,打开控制台,搜索java关键词搜索职位,选取北京地区,然后查看network一栏中的数据分析,查看第一个,是不是感觉它很像我们要拿到的请求地址,事实上不是的,这个打开之后是一个html,如果我们访问这个接口,拉钩会返回给我们一个结果,提示我们操作太频繁,也就是被拦截了。不过从这个页面可以看到,拉钩的网页用到了模板,这种加载数据的方式更加快速(大幅度提升),建议大家可以尝试使用一下(个人拙见)不要气馁,我们接着往下找,可以看到一个“positionAjax”开头的请求,没错就它“https://www.lagou.com/jobs/positionAjax.jsonpx=default&city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false&isSchoolJob=0”,还是看图说话吧
找到请求地址之后,我们就开始写代码了。先是导入requests和pymysql,然后requests的post方法访问上面找到的url,但是直接访问这个地址是会被拦截的,因为我们缺少所要传输的数据,和设置请求头,会被认为是非自然人请求的,加入请求头和数据,
加入请求头之后就可以请求了,控制台输出数据,可以看出是一个json数据,使用json方法处理之后,一步步找到我们想要的数据,可以看出全在“result”里面,那么我们就只拿到他就行了,result=resp.json()['content']['positionResult']['result']这个时候可以看到数据非常多,有30个左右,不过不用担心,都是英文单词,基本上可以才出意思。接下来我们就要怕这些数据存储到数据库中,以备日后分析使用。连接mysql我使用的是pymysql,先建好数据库和数据表,然后在代码中加入配置信息
加载配置文件,连接数据库
大功告成,这个时候拉钩的职位信息已经静静地躺在了你的数据库中,静待你的宠幸,拿到这些数据,你就可以进行一些分析了,比如平均工资水平、职位技能要求等。因为篇幅有限,有些代码并没有粘贴出来,比如sql语句(这个sql写的挺长的),但是别担心,楼主已经把这个程序放入到github上面了,大家可以自行下载,github地址:https://github.com/wudb1993/pythonDemo,手打不易谢谢啦,欢迎大神拍砖。
文章来源:http://www.51testing.com/html/21/n-3724921.html今天写的这篇文章是关于python爬虫简单的一个使用,选取的爬取对象是著名的招聘网站——拉钩网,由于和大家的职业息息相关,所以爬取拉钩的数据进行分析,对于职业规划和求职时的信息提供有很大的帮助。
完成的效果
爬取数据只是第一步,怎样使用和分析数据也是一大重点,当然这不是本次博客的目的,由于本次只是一个上手的爬虫程序,所以我们的最终目的只是爬取到拉钩网的职位信息,然后保存到Mysql数据库中。最后中的效果示意图如下:准备工作
首先需要安装python,这个网上已经有很多的教程了,这里就默认已经安装python,博主使用的是python3.6,然后安装了requests、pymysql(连接数据库使用)和Mysql数据库。分析拉勾网
首先我们打开拉勾网,打开控制台,搜索java关键词搜索职位,选取北京地区,然后查看network一栏中的数据分析,查看第一个,是不是感觉它很像我们要拿到的请求地址,事实上不是的,这个打开之后是一个html,如果我们访问这个接口,拉钩会返回给我们一个结果,提示我们操作太频繁,也就是被拦截了。不过从这个页面可以看到,拉钩的网页用到了模板,这种加载数据的方式更加快速(大幅度提升),建议大家可以尝试使用一下(个人拙见)不要气馁,我们接着往下找,可以看到一个“positionAjax”开头的请求,没错就它“https://www.lagou.com/jobs/positionAjax.jsonpx=default&city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false&isSchoolJob=0”,还是看图说话吧
找到请求地址之后,我们就开始写代码了。先是导入requests和pymysql,然后requests的post方法访问上面找到的url,但是直接访问这个地址是会被拦截的,因为我们缺少所要传输的数据,和设置请求头,会被认为是非自然人请求的,加入请求头和数据,
加入请求头之后就可以请求了,控制台输出数据,可以看出是一个json数据,使用json方法处理之后,一步步找到我们想要的数据,可以看出全在“result”里面,那么我们就只拿到他就行了,result=resp.json()['content']['positionResult']['result']这个时候可以看到数据非常多,有30个左右,不过不用担心,都是英文单词,基本上可以才出意思。接下来我们就要怕这些数据存储到数据库中,以备日后分析使用。连接mysql我使用的是pymysql,先建好数据库和数据表,然后在代码中加入配置信息
加载配置文件,连接数据库
大功告成,这个时候拉钩的职位信息已经静静地躺在了你的数据库中,静待你的宠幸,拿到这些数据,你就可以进行一些分析了,比如平均工资水平、职位技能要求等。因为篇幅有限,有些代码并没有粘贴出来,比如sql语句(这个sql写的挺长的),但是别担心,楼主已经把这个程序放入到github上面了,大家可以自行下载,github地址:https://github.com/wudb1993/pythonDemo,手打不易谢谢啦,欢迎大神拍砖。

相关文章推荐
- #python学习笔记#使用python爬取拉勾网职位信息(二):爬取数据
- python爬取拉勾网职位数据
- python爬取拉勾网任意职位数据
- 拉勾网爬取全国python职位并数据分析薪资,工作经验,学历等信息
- python爬取拉勾网职位数据的方法
- python爬虫实战(九)--------拉勾网全站职位(CrawlSpider)
- python数据挖掘入门与实战——学习笔记(第3、4章)
- python爬虫,获取拉勾网职位信息,修改网上旧版不能用的问题
- Python开发实战教程(8)-向网页提交获取数据
- 利用Python爬虫爬取淘宝商品做数据挖掘分析实战篇,超详细教程
- Python数据挖掘与机器学习_通信信用风险评估实战(4)——模型训练与调优
- python实战三:通过任务计划定期获取jira数据并保存到csv
- 下载大数据实战课程第二季基于Python机器学习、项目案例实战
- Python微博地点签到大数据实战(二)POI与坐标
- Pyhton爬虫实战 - 抓取BOSS直聘职位描述 和 数据清洗
- Python数据挖掘与机器学习_通信信用风险评估实战(1)——读数据
- 【Python实战】Pandas:让你像写SQL一样做数据分析(一)
- 大数据实战课程第一季Python基础和网络爬虫数据分析
- Python爬虫框架Scrapy实战之抓取户外数据
- python爬取拉勾网招聘信息并利用pandas做简单数据分析