大数据入门第十六天——流式计算之storm详解(一)入门与集群安装
2018-03-05 13:48
746 查看
一、概述
今天起就正式进入了流式计算。这里先解释一下流式计算的概念离线计算
离线计算:批量获取数据、批量传输数据、周期性批量计算数据、数据展示
代表技术:Sqoop批量导入数据、HDFS批量存储数据、MapReduce批量计算数据、Hive批量计算数据、***任务调度
Job:任务名称 JobTracker:项目经理 TaskTracker:开发组长、产品经理 Child:负责开发的人员 Mapper/Reduce:开发人员中的两种角色,一种是服务器开发、一种是客户端开发 Topology:任务名称 Nimbus:项目经理 Supervisor:开组长、产品经理 Worker:开人员 Spout/Bolt:开人员中的两种角色,一种是服务器开发、一种是客户端开发
名词解释
简单来说:Apache Storm执行除持久性之外的所有操作,而Hadoop在所有方面都很好,但滞后于实时计算。
3.应用场景
Storm用来实时计算源源不断产生的数据,如同流水线生产。
日志分析
从海量日志中分析出特定的数据,并将分析的结果存入外部存储器用来辅佐决策。
管道系统
将一个数据从一个系统传输到另外一个系统,比如将数据库同步到Hadoop
消息转化器
将接受到的消息按照某种格式进行转化,存储到另外一个系统如消息中间件
更多概述与特性,参加上文官网与w3c相关介绍!
二、storm核心组件与编程模型
1.核心组件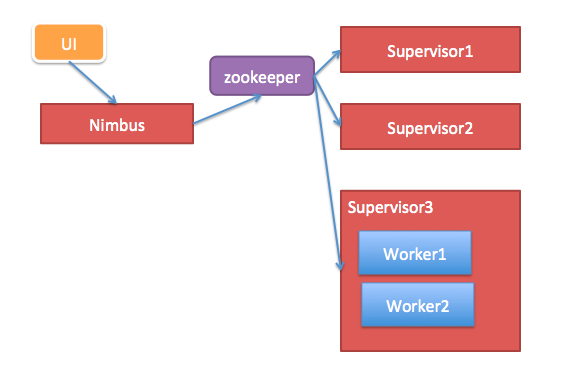
Nimbus:负责资源分配和任务调度。
Supervisor:负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程。---通过配置文件设置当前supervisor上启动多少个worker。
Worker:运行具体处理组件逻辑的进程。Worker运行的任务类型只有两种,一种是Spout任务,一种是Bolt任务。(一worker就是一个JVM。)
Task:worker中每一个spout/bolt的线程称为一个task. 在storm0.8之后,task不再与物理线程对应,不同spout/bolt的task可能会共享一个物理线程,该线程称为executor。
2.编程模型
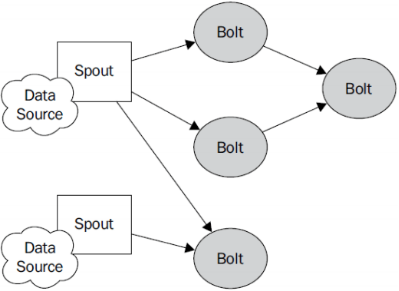
Topology:Storm中运行的一个实时应用程序的名称。(拓扑)
Spout:在一个topology中获取源数据流的组件。
通常情况下spout会从外部数据源中读取数据,然后转换为topology内部的源数据。
Bolt:接受数据然后执行处理的组件,用户可以在其中执行自己想要的操作。
Tuple:一次消息传递的基本单元,理解为一组消息就是一个Tuple。
Stream:表示数据的流向。
DataSource:外部数据源 Spout:接受外部数据源的组件,将外部数据源转化成Storm内部的数据,以Tuple为基本的传输单元下发给Bolt Bolt:接受Spout发送的数据,或上游的bolt的发送的数据。根据业务逻辑进行处理。发送给下一个Bolt或者是存储到某种介质上。介质可以是Redis可以是mysql,或者其他。 Tuple:Storm内部中数据传输的基本单元,里面封装了一个List对象,用来保存数据。 StreamGrouping:数据分组策略 7种:shuffleGrouping(Random函数),Non Grouping(Random函数),FieldGrouping(Hash取模)、Local or ShuffleGrouping 本地或随机,优先本地。

这些概念在官网中的concepts章节有相关介绍:http://storm.apache.org/releases/1.0.6/Concepts.html
并发编程网中文storm翻译教程:http://ifeve.com/getting-started-with-stom-index/
3.一般架构

其中flume用来获取数据。
Kafka用来临时保存数据。
Strom用来计算数据。
Redis是个内存数据库,用来保存数据。
三、storm集群的安装
1.下载windows或者linux中使用wget命令下载皆可
2.解压
[hadoop@mini1 ~]$ tar -zxvf apache-storm-1.0.6.tar.gz -C apps/
解压后如果有需要,可以参考这里创建软连接
cd apps/ ln -s apache-storm-1.0.6 storm
3.配置环境变量
sudo vim /etc/profile
export STORM_HOME=/home/hadoop/apps/apache-storm-1.0.6 export PATH=$PATH:$STORM_HOME/bin
source /etc/profile
4.配置storm
[hadoop@mini1 conf]$ mv storm.yaml storm.yaml.bak [hadoop@mini1 conf]$ vim storm.yam
通过mv或者cp命令备份出厂配置,这是一个比较推荐的好习惯
#指定storm使用的zk集群 storm.zookeeper.servers: - "mini1" - "mini2" - "mini3" #指定storm集群中的nimbus节点所在的服务器 nimbus.host: "mini1" #指定nimbus启动JVM最大可用内存大小 nimbus.childopts: "-Xmx1024m" #指定supervisor启动JVM最大可用内存大小 supervisor.childopts: "-Xmx1024m" #指定supervisor节点上,每个worker启动JVM最大可用内存大小 worker.childopts: "-Xmx768m" #指定ui启动JVM最大可用内存大小,ui服务一般与nimbus同在一个节点上。 ui.childopts: "-Xmx768m" #指定supervisor节点上,启动worker时对应的端口号,每个端口对应槽,每个槽位对应一个worker supervisor.slots.ports: - 6700 - 6701 - 6702 - 6703
5.分发安装包
[hadoop@mini1 apps]$ scp -r apache-storm-1.0.6/ mini2:/home/hadoop/apps/
[hadoop@mini1 apps]$ scp -r apache-storm-1.0.6/ mini3:/home/hadoop/apps/
// 这里使用的是相对路径,分发时请注意所在目录
另外两台机器也分别配置一下环境变量,以及如果有需要可以建立软连接(推荐)
6.启动
在master(这里是mini1上)上启动
nohup storm nimbus & nohup storm ui &
supervisor上启动:
nohup storm supervisor &
停止storm进程只有一种方式,就是kill
这里发现storm会有自动停止的问题,目前百度到的方法参考如下:http://roadrunners.iteye.com/blog/2229894
启动的东西还是挺多的,从hadoop到这里,应该搞一个统一的启动脚本!
输出的信息设置:
[root@log1 ~]# nohup storm ui >/dev/null 2>&1 & [root@log1 ~]# nohup storm nimbus >/dev/null 2>&1 &
默认情况下,nohup执行的日志在当前目录下的nohup.out中,除非重定向
此处重定向到了/dev/null,即空白设备,即丢弃了。
访问nimbus的主机即可:(如果有时候刚开始加载不了,注意稍等一会儿)
http://mini1:8080

相关文章推荐
- 大数据入门第十六天——流式计算之storm详解(三)集群相关进阶
- 大数据入门第十六天——流式计算之storm详解(二)常用命令与wc实例
- 大数据入门第十七天——storm上游数据源 之kafka详解(一)入门与集群安装
- 大数据入门第五天——离线计算之hadoop(上)概述与集群安装
- 大数据处理之流式计算 storm安装
- Storm入门教程(三):安装部署步骤详解
- 详解 Linux系统集群的安装与并行计算
- 一共81个,开源大数据处理工具汇总:查询引擎、流式计算、迭代计算、离线计算、键值存储、表格存储、文件存储、资源管理、日志收集系统、消息系统、分布式服务、集群管理、基础设施、搜索引擎、数据挖掘=监控
- 【Storm入门指南】附录B 安装Storm集群
- 给Clouderamanager集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
- 大数据入门第八天——MapReduce详解(三)MR的shuffer、combiner与Yarn集群分析
- Storm集群安装详解
- storm实时流式计算框架集群搭建过程
- storm实时流式计算框架集群搭建过程
- 【流式计算】Twitter Storm: 搭建storm集群
- CentOS下Storm 1.0.0集群安装详解
- CentOS下Storm 1.0.0集群安装详解
- Storm集群安装详解
- [译]【Storm入门指南】附录B 安装Storm集群
- Storm入门(二)集群环境安装