【数据仓库】——星型模型和雪花模型
2018-02-28 18:26
337 查看
一、概述
在多维分析的商业智能解决方案中,根据事实表和维度表的关系,又可将常见的模型分为星型模型和雪花型模型。在设计逻辑型数据的模型的时候,就应考虑数据是按照星型模型还是雪花型模型进行组织。当所有维表都直接连接到“ 事实表”上时,整个图解就像星星一样,故将该模型称为星型模型,

星型架构是一种非正规化的结构,多维数据集的每一个维度都直接与事实表相连接,不存在渐变维度,所以数据有一定的冗余,
如在地域维度表中,存在国家 A 省 B 的城市 C 以及国家 A 省 B 的城市 D 两条记录,那么国家 A 和省 B 的信息分别存储了两次,即存在冗余。
当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。

雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的 " 层次 " 区域,这些被分解的表都连接到主维度表而不是事实表。如图 2,将地域维表又分解为国家,省份,城市等维表。
它的优点是 : 通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能。雪花型结构去除了数据冗余。
此在冗余可以接受的前提下,实际运用中星型模型使用更多,也更有效率。
二、使用选择
1.数据优化雪花模型使用的是规范化数据,也就是说数据在数据库内部是组织好的,以便消除冗余,因此它能够有效地减少数据量。通过引用完整性,其业务层级和维度都将存储在数据模型之中。

▲图1 雪花模型
相比较而言,星形模型实用的是反规范化数据。在星形模型中,维度直接指的是事实表,业务层级不会通过维度之间的参照完整性来部署。
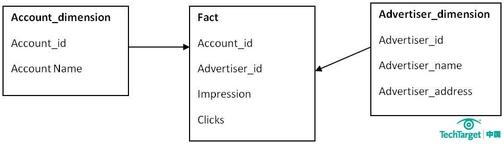
▲图2 星形模型
2.业务模型
主键是一个单独的唯一键(数据属性),为特殊数据所选择。在上面的例子中,Advertiser_ID就将是一个主键。外键(参考属性)仅仅是一个表中的字段,用来匹配其他维度表中的主键。在我们所引用的例子中,Advertiser_ID将是Account_dimension的一个外键。
在雪花模型中,数据模型的业务层级是由一个不同维度表主键-外键的关系来代表的。而在星形模型中,所有必要的维度表在事实表中都只拥有外键。
3.性能
第三个区别在于性能的不同。雪花模型在维度表、事实表之间的连接很多,因此性能方面会比较低。举个例子,如果你想要知道Advertiser 的详细信息,雪花模型就会请求许多信息,比如Advertiser Name、ID以及那些广告主和客户表的地址需要连接起来,然后再与事实表连接。
而星形模型的连接就少的多,在这个模型中,如果你需要上述信息,你只要将Advertiser的维度表和事实表连接即可。
4.ETL
雪花模型加载数据集市,因此ETL操作在设计上更加复杂,而且由于附属模型的限制,不能并行化。
星形模型加载维度表,不需要再维度之间添加附属模型,因此ETL就相对简单,而且可以实现高度的并行化。
总结
通过上面的对比,我们可以发现数据仓库大多数时候是比较适合使用星型模型构建底层数据Hive表,通过大量的冗余来提升查询效率,星型模型对OLAP的分析引擎支持比较友好,这一点在Kylin中比较能体现。而雪花模型在关系型数据库中如MySQL,Oracle中非常常见,尤其像电商的数据库表。在数据仓库中雪花模型的应用场景比较少,但也不是没有,所以在具体设计的时候,可以考虑是不是能结合两者的优点参与设计,以此达到设计的最优化目的。
参考链接:http://blog.csdn.net/u010454030/article/details/74589791

相关文章推荐
- 数据仓库介绍(七) - 星型模型与雪花模型
- 星型模型和雪花模型 (数据仓库模型)
- 数据仓库模型(星型模型和雪花模型 )
- 理解数据仓库中星型模型和雪花模型
- 数据仓库多维数据模型-星型模型 和 雪花模型
- 数据仓库的星形和雪花模型
- 理解数据仓库中星型模型和雪花模型
- 胖子哥的大数据之路(9)- 数据仓库金融行业数据逻辑模型FS-LDM
- 数据仓库专题20-案例篇:电商领域数据主题域模型设计v0.2(改进意见征集中)
- 数据仓库的多维数据模型
- 维度模型数据仓库(十三) —— 退化维度
- 数据仓库-多维数据模型
- 数据仓库的数据模型与数据组织
- 数据模型中 星与雪花
- 如何建立和评估数据仓库逻辑模型
- 维度模型数据仓库(二) —— 维度模型基础
- 数据仓库专题(5)-如何构建主题域模型原则之站在巨人的肩上(一)IBM-FSDM主题域模型划分
- 维度模型数据仓库基础对象概念一览
- XXX数据仓库分析模型设计文档
- 三个例子,让你看懂数据仓库多维数据模型的设计