过拟合与L1,L2正则化
2018-03-04 13:16
435 查看
一、为什么会产生过拟合?我们常见的损失函数如下所示:
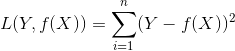
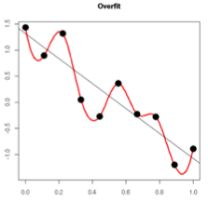
周志华的《机器学习》有一句话,“当样本特征很多,而样本数相对较少时,上式很容易陷入过拟合”。关于这就话,我的理解是,当特征较多时,对应的参数W的维度就会越高,越高的维度就越容易拟合出越高维度,越复杂的图形。而当样本数很少,但是又具有拟合复杂图形的能力时,系统就会精确拟合全部特征点,而陷入过拟合,如下图
二、什么是L1,L2正则化L1范数是指向量中各个元素绝对值之和,也有叫做“稀疏规则算子”(Lasso regularization),通常表示为||w||1。
L2正则化是指权值向量w中各个元素的平方和然后再求平方根(可以看到Ridge回归的L2正则化项有平方符号),通常表示为||w||2。也叫做“岭回归”(Ridge Regression),有人也叫它“权值衰减weight decay”
那添加L1和L2正则化有什么用?下面是L1正则化和L2正则化的作用,这些表述可以在很多文章中找到。L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合
三、为什么可以防止过拟合?在原损失函数的基础上,增加惩罚项,就会产生如下带L1正则化的损失函数:
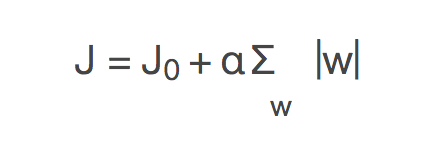
其中J0是原始的损失函数,加号后面的一项是L1正则化项,α是正则化系数。令L=α∑w|w|,则J=J0+L,此时我们的任务变成在L约束下求出J0取最小值的解。
增加惩罚项为什么就能降低过拟合呢,因为当出现过拟合时,拟合曲线会试图经过所有点,这样就会造成曲线很弯曲,很弯曲的曲线也就意味着在局部的变化很大,也就是函数的导数绝对值很大,相应的权重系数也会很大(只有很大的权重系数时,x的微小改变才能造成y的很大改变)。而当系数W很大时,由于L的存在,就会使误差函数J的值变大。当精确拟合全部点使得J0减小的量,不能抵消L增加的量时,系统就会停止更新,也就防止了过拟合。
四、 为什么L1能产生稀疏矩阵?稀疏矩阵指的是很多元素为0,只有少数元素是非零值的矩阵,即得到的线性回归模型的大部分系数都是0。当输入的特征很多时,一个稀疏模型,表示只有少数特征对这个模型有贡献,绝大部分特征是没有贡献的,或者贡献微小(因为它们前面的系数是0或者是很小的值,即使去掉对模型也没有什么影响),此时我们就可以只关注系数是非零值的特征。这就是稀疏模型与特征选择的关系。
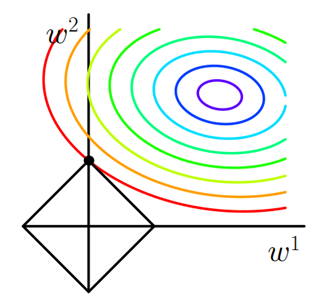
图中等值线是J0的等值线,黑色方形是L函数的图形。图中圆心位置对应就是J0的最小值(此时W相对是一个较大的值),越向外的圈表示J0的值越大(W越小)。而对于惩罚项,W的值越小,L就越小,所以当J0等值线与L图形首次相交的地方就是最优解。上图中J0与L在L的一个顶点处相交,这个顶点就是最优解。
注意到这个顶点的值是(w1,w2)=(0,w)。可以直观想象,因为L函数有很多『突出的角』(二维情况下四个,多维情况下更多),J0与这些角接触的机率会远大于与L其它部位接触的机率,而在这些角上,会有很多权值等于0,这就是为什么L1正则化可以产生稀疏模型,进而可以用于特征选择。
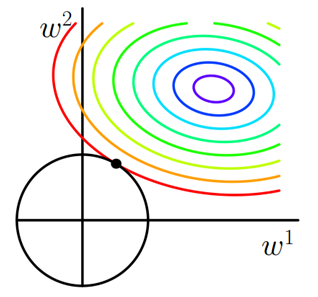
二维平面下L2正则化的函数图形是个圆,与方形相比,被磨去了棱角。因此J0与L相交时使得w1或w2等于零的机率小了许多,这就是为什么L2正则化不具有稀疏性的原因。
拟合过程中通常都倾向于让权值尽可能小,最后构造一个所有参数都比较小的模型。因为一般认为参数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。可以设想一下对于一个线性回归方程,若参数很大,那么只要数据偏移一点点,就会对结果造成很大的影响;但如果参数足够小,数据偏移得多一点也不会对结果造成什么影响,专业一点的说法是『抗扰动能力强』。
系数很大的系统,有个专业的说法叫做ill-condition系统,指的就是输入的微小改变就会造成输出的巨大改变,这样的系统所输出的数据,是我们不能相信的

参考文章:http://blog.csdn.net/jinping_shi/article/details/52433975 http://blog.csdn.net/zouxy09/article/details/24971995
周志华的《机器学习》有一句话,“当样本特征很多,而样本数相对较少时,上式很容易陷入过拟合”。关于这就话,我的理解是,当特征较多时,对应的参数W的维度就会越高,越高的维度就越容易拟合出越高维度,越复杂的图形。而当样本数很少,但是又具有拟合复杂图形的能力时,系统就会精确拟合全部特征点,而陷入过拟合,如下图
二、什么是L1,L2正则化L1范数是指向量中各个元素绝对值之和,也有叫做“稀疏规则算子”(Lasso regularization),通常表示为||w||1。
L2正则化是指权值向量w中各个元素的平方和然后再求平方根(可以看到Ridge回归的L2正则化项有平方符号),通常表示为||w||2。也叫做“岭回归”(Ridge Regression),有人也叫它“权值衰减weight decay”
那添加L1和L2正则化有什么用?下面是L1正则化和L2正则化的作用,这些表述可以在很多文章中找到。L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合
三、为什么可以防止过拟合?在原损失函数的基础上,增加惩罚项,就会产生如下带L1正则化的损失函数:
其中J0是原始的损失函数,加号后面的一项是L1正则化项,α是正则化系数。令L=α∑w|w|,则J=J0+L,此时我们的任务变成在L约束下求出J0取最小值的解。
增加惩罚项为什么就能降低过拟合呢,因为当出现过拟合时,拟合曲线会试图经过所有点,这样就会造成曲线很弯曲,很弯曲的曲线也就意味着在局部的变化很大,也就是函数的导数绝对值很大,相应的权重系数也会很大(只有很大的权重系数时,x的微小改变才能造成y的很大改变)。而当系数W很大时,由于L的存在,就会使误差函数J的值变大。当精确拟合全部点使得J0减小的量,不能抵消L增加的量时,系统就会停止更新,也就防止了过拟合。
四、 为什么L1能产生稀疏矩阵?稀疏矩阵指的是很多元素为0,只有少数元素是非零值的矩阵,即得到的线性回归模型的大部分系数都是0。当输入的特征很多时,一个稀疏模型,表示只有少数特征对这个模型有贡献,绝大部分特征是没有贡献的,或者贡献微小(因为它们前面的系数是0或者是很小的值,即使去掉对模型也没有什么影响),此时我们就可以只关注系数是非零值的特征。这就是稀疏模型与特征选择的关系。
图中等值线是J0的等值线,黑色方形是L函数的图形。图中圆心位置对应就是J0的最小值(此时W相对是一个较大的值),越向外的圈表示J0的值越大(W越小)。而对于惩罚项,W的值越小,L就越小,所以当J0等值线与L图形首次相交的地方就是最优解。上图中J0与L在L的一个顶点处相交,这个顶点就是最优解。
注意到这个顶点的值是(w1,w2)=(0,w)。可以直观想象,因为L函数有很多『突出的角』(二维情况下四个,多维情况下更多),J0与这些角接触的机率会远大于与L其它部位接触的机率,而在这些角上,会有很多权值等于0,这就是为什么L1正则化可以产生稀疏模型,进而可以用于特征选择。
二维平面下L2正则化的函数图形是个圆,与方形相比,被磨去了棱角。因此J0与L相交时使得w1或w2等于零的机率小了许多,这就是为什么L2正则化不具有稀疏性的原因。
拟合过程中通常都倾向于让权值尽可能小,最后构造一个所有参数都比较小的模型。因为一般认为参数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。可以设想一下对于一个线性回归方程,若参数很大,那么只要数据偏移一点点,就会对结果造成很大的影响;但如果参数足够小,数据偏移得多一点也不会对结果造成什么影响,专业一点的说法是『抗扰动能力强』。
系数很大的系统,有个专业的说法叫做ill-condition系统,指的就是输入的微小改变就会造成输出的巨大改变,这样的系统所输出的数据,是我们不能相信的
参考文章:http://blog.csdn.net/jinping_shi/article/details/52433975 http://blog.csdn.net/zouxy09/article/details/24971995

相关文章推荐
- 模型泛化能力——过拟合与欠拟合,L1/L2正则化(复习16)
- 正则化方法/防止过拟合提高泛化能力的方法:L1和L2 regularization、数据集扩增、dropout
- 对过拟合的处理:正则化方法:L1和L2 regularization、数据集扩增、dropout
- 过拟合以及正则化(L0,L1,L2范数)
- L0,L1,L2范数,正则化,过拟合
- 正则化方法:L1和L2 regularization、数据集扩增、dropout
- L1,L2正则化
- 【深度学习理论】正则化方法:L1、L2、数据扩增、Dropout
- L1 L2正则化
- 避免过拟合的手段:L1&L2 regularization/Data Augmentation/Dropout/Early Stoping
- L1和L2正则化部分比较
- L1和L2正则化
- [置顶] 机器学习损失函数、L1-L2正则化的前世今生
- 正则化方法:L1和L2 regularization、数据集扩增、dropout
- 初学者如何学习机器学习中的L1和L2正则化
- 过拟合是什么?如何解决过拟合?l1、l2怎么解决过拟合
- L1 L2正则化及贝叶斯解释
- 笔记︱范数正则化L0、L1、L2-岭回归&Lasso回归(稀疏与特征工程)
- L1和L2正则化
- L1,L2正则化理解-奥卡姆剃刀(Occam's razor)原理