Python数据挖掘07--KNN算法理论与实现
2018-03-03 22:23
926 查看
一、KNN算法
KNN算法是一种解决分类问题的算法之一。一般实现KNN算法有两种思路:
1、通过KNN算法自行写Python代码源生实现
2、依据一些集成模块直接调用实现
二、KNN算法理论思路
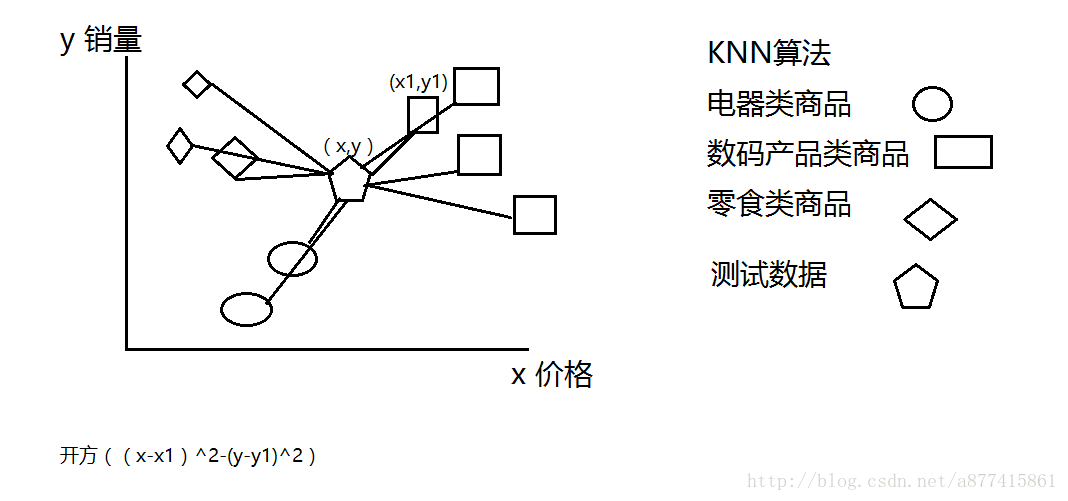
1、计算新个体到各旧数据之间的距离
2、统计出距离最短的前K个商品
3、统计距离最短的前K个商品中哪一个类别最多
4、将新商品归为类别最多的这一个类别
三、代码实现
1、源生代码实现KNN算法from numpy import *
import operator
"""
参数对应
k 所取的实例个数 2
testdata 测试数据 一维数组 [0, 1, 2, 3]
traindata 历史数据 二维数组 [[0, 0, 2, 1], [1, 2, 5, 4],[1, 2, 3, 4]]
labels 所对应训练数据的特征 一维数组 [6, 7, 8]
"""
def knn(k , testdata, traindata, labels):
# 训练数据个数
# shape取的事训练数据的第一维,即其行数,也就是训练数据的个数
traindatasize = traindata.shape[0] # 2
# 将测试数据转成和历史数据一样的个数 然后和训练数据相减
# tile()的意思是给一维的测试数据转为与训练数据一样的行和列的格式
dif = tile(testdata, (traindatasize, 1)) - traindata # [[ 0 1 0 2] [-1 -1 -3 -1] [-1 -1 -1 -1]]
sqdif = dif ** 2 # [[0 1 0 4] [1 1 9 1] [1 1 1 1]]
# axis=1 ----> 横向相加的意思
sumsqdif = sqdif.sum(axis=1) # [ 5 12 4]
# 此时sumsqdif以成为一维数组
distance = sumsqdif ** 0.5 # [2.23606798 3.46410162 2. ]
# sortdistance为测试数据各个训练数据的距离按近到远排序之后的结果
sortdistance = distance.argsort() # [2 0 1]
count = {}
for i in range(0, k):
vote = labels[sortdistance[i]] # 8 6
# vote测试数据最近的K个训练数据的类别
count[vote] = count.get(vote, 0) + 1
sortcount = sorted(count.items(), key=operator.itemgetter(1), reverse=True) # [(8, 1), (6, 1)]
return sortcount[0][0]
# 测试数据
k = 2
testdata = array([0, 1, 2, 3])
traindata = array([[0, 0, 2, 1], [1, 2, 5, 4],[1, 2, 3, 4]])
labels = array([6, 7, 8])
print(knn(k , testdata, traindata, labels))源生代码中可能存在的一些疑问
(1)tile用法
from numpy import * 1、我们创建一个a,如图下图,使用tile来创建b,注意看b的数据结构: >>> a=[0,1,2] >>> b=tile(a,2) >>> b array([0, 1, 2, 0, 1, 2]) 2、假如我们输入一个元组(1,2),我们会得到一样的结果,与上面相同的b >>> b=tile(a,(1,2)) >>> b array([[0, 1, 2, 0, 1, 2]]) 3、当然,我们想要a变为一个二维数组,就要换一种重复的方式了。 >>> b=tile(a,(2,1)) >>> b array([[0, 1, 2], [0, 1, 2]])
(2)sum中axis=1的用法
现在对于数据的处理更多的还是numpy。
没有axis参数表示全部相加
axis=0表示按列相加
axis=1表示按照行的方向相加
>>> import numpy as np >>> a=np.sum([[0,1,2],[2,1,3]]) >>> a 9 >>> a.shape () >>> a=np.sum([[0,1,2],[2,1,3]],axis=0) >>> a array([2, 2, 5]) >>> a.shape (3,) >>> a=np.sum([[0,1,2],[2,1,3]],axis=1) >>> a array([3, 6]) >>> a.shape (2,)
(3)、如果出现广播错误
如果两个数组的shape不同的话,会进行如下的广播(broadcasting)处理:
1、让所有输入数组都向其中shape最长的数组看齐,shape中不足的部分都通过在前面加1补齐
2、输出数组的shape是输入数组shape的各个轴上的最大值
3、如果输入数组的某个轴和输出数组的对应轴的长度相同或者其长度为1时,这个数组能够用来计算,否则出错
4、当输入数组的某个轴的长度为1时,沿着此轴运算时都用此轴上的第一组值
2、模块代码实现
from sklearn.neighbors import KNeighborsClassifier model=KNeighborsClassifier() # x为训练数据,y为对应特征 model.fit(x,y) # x2为测试数据 y2=model.predict(x2)

相关文章推荐
- 数据挖掘(Python)——利用sklearn进行数据挖掘,实现算法:svm、knn、C5.0、NaiveBayes
- python数据挖掘实践第一章 KNN算法,以及算法的实现
- 数据挖掘 --- Python实现KNN算法项目-约会推荐算法
- 数据挖掘 --- Python实现KNN算法项目 - 水果分类
- 机器学习与数据挖掘系列算法之--knn的python实现
- 数据挖掘10大算法(6)-K最近邻(KNN)算法的实现(java和python版)
- 机器学习与数据挖掘-K最近邻(KNN)算法的实现(java和python版)
- 数据挖掘(二)——Knn算法的java实现
- 数据挖掘-基于贝叶斯算法及KNN算法的newsgroup18828文档分类器的JAVA实现(下)
- 数据挖掘算法---KNN(附python代码)
- 数据挖掘-基于贝叶斯算法及KNN算法的newsgroup18828文本分类器的JAVA实现(上)
- 数据挖掘:K最近邻(KNN)算法的java实现
- 数据挖掘-基于贝叶斯算法及KNN算法的newsgroup18828文本分类器的JAVA实现(下)
- 数据挖掘之Apriori算法的Python实现
- 数据挖掘:K最近邻(KNN)算法的java实现
- 数据挖掘:K最近邻(KNN)算法的java实现
- 数据挖掘-基于贝叶斯算法及KNN算法的newsgroup18828文本分类器的JAVA实现(上)
- 数据挖掘-基于贝叶斯算法及KNN算法的newsgroup18828文本分类器的JAVA实现(上)
- 数据挖掘之Apriori算法详解和Python实现代码分享
- 数据挖掘-基于贝叶斯算法及KNN算法的newsgroup18828文档分类器的JAVA实现(上)