论文Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization
2018-02-27 22:56
274 查看
摘要:
Gatys等人最近引入了一种神经算法,以另一幅图像的样式呈现内容图像,实现所谓的样式转换。但是,工作需要缓慢的迭代优化过程,这限制了其实际应用。后来有人提出了一种基于前馈神经网络的快速逼近方法,以加快神经网络的传输速度。不幸的是,速度的提高需要付出代价:网络通常绑定到一组固定的样式,无法适应任意的新样式。在本文中,我们提出了一种简单而有效的方法,它首次实现了任意样式的实时传输。我们方法的核心是一个新颖的自适应实例规范化(AdaIN)层,它将内容特征的均值和方差与样式特征的均值和方差对齐。我们的方法实现了与现有最快方法相媲美的速度,而不受对预定义样式集的限制。此外,我们的方法允许用户进行灵活的控制,如内容折中,样式插值,颜色和空间控制等,所有这些都使用单一的前馈神经网络。
该论文在CIN的基础上做了一个改进,提出了AdaIN(自适应IN层)。顾名思义,就是自己根据风格图像调整缩放和平移参数,不在需要像CIN一样保存风格特征的均值和方差,而是在将风格图像经过卷积网络后计算出均值和方差。
BN(Batch Normalization)归一化一批样例以一个单一风格为中心,但是每个样本仍然可能有自己的风格。
对一批样例进行计算每通道的均值和方差。
BNlayers在训练和测试时采用的是不同的数据集,训练时是采用小批数据。

IN(Instance Normalization)
每个样例以及每个通道都独立计算均值、方差。
IN layers在训练以及测试时使用相同的数据统计。
归一化每个样例到一个单一的风格。

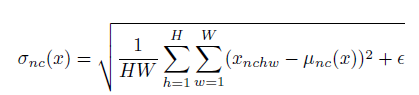
总的来说batch norm是对一个batch里所有的图片的所有像素求均值和标准差。而instance norm是对单个图片的所有像素求均值和标准差。
CIN(Conditional Instance Normalization)
条件实例归一化,A learned representation for artistic style论文中主要提到的方法。网络可以通过使用相同的卷积参数来生成完全不同风格的图像,而只需要对归一化的结果进行一个平移和缩放,平移和缩放就是β_s和γ_s(s代表风格),每一个风格就是要学习这两个参数。训练多个风格就需要多组数据,如有c个feature maps和需要训练N个风格,那么总共就有2*N*C个参数需要训练。
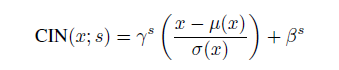
[align=left][/align][align=left]AdaIN(Adaptive Instance Normalization)[/align][align=left]
[/align]

[align=left] 自适应实例归一化,就是把content image的feature分布拉到style image的feature分布,这样就在特征空间完成了风格变换。而由于stlye image可以任意输入,可以实现任意风格变换。这篇论文中采用的是预训练好的vgg网络relu4_1的feature空间结果作为输入的。[/align][align=left]AdaIN和CIN 很大的区别是参数不需要进行训练。[/align]
网络结构

网络结构主要分为两个部分:生成网络即style transfer network和计算损耗网络。生成网络是一个前向网络,后期用来进行风格转换网络。计算损耗网络是用来训练时进行约束的。风格转换生成网络由Encoder-AdaIN-Decoder这3部分组成。
Encoder 部分是采用预训练好的VGG网络,只使用到了Relu4_1,将风格和内容图的图像都从图像空间转到特征空间。
AdaIN层是对内容图进行归一化,这里是通过对齐内容图的每通道的feature map的均值和方差来匹配风格图每通道feature map的均值和方差。

这里的x是content image, y是style image,将归一化后的内容图的输入进行缩放和平移。
AdaIN和Fast Patch-based Style Transfer of Arbitrary Style这篇论文中提出的style swap层作用类似,都是把风格信息加入到content中。style swap 比较费时以及费内存,需要每个块和对应的所有块作比较。这两个算法的这部分都是不需要训练的。
Decoder部分是一个将feature 空间转成图像空间的网络,这部分网络一般是采用和encoder对称的网络结构,整个网络中需要训练的就是这部分网络的权重参数信息,初始可以随机一些初始化参数,通过梯度下降可以不断进行更新参数以使整个损耗函数比较小、网络逐渐收敛。池化层一般是替换成采用最近邻上采样的方式来防止棋盘效应,在encoder和decoder部分的padding一般都是采用反射填充避免边界artifacts。decoder中没有使用归一化层,因为IN/BN这些实例归一化和批归一化都是针对单个风格的。
损耗函数 损耗函数主要由两部分组成:内容损耗以及风格损耗。和最早Gatys提出的方法一致,也是采用预训练好的vgg网络的特征maps进行计算损耗。

内容损耗:转换后图像在vgg网络中Relu4_1的特征和adaIN输出feature maps的欧式距离。这里论文没有具体说明转换后图像在vgg网络中具体哪层的输出特征进行相减,但是我觉得应该肯定是Relu4_1的,和传统取的层不一致,主要是因为输出的adaIN的结果relu4_1,只能同层进行比较,才有可比性。
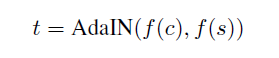

[align=left] [/align]

[align=left]其中t为经过adain层后的target feature maps,T(c, s)为生成的风格化图片。[/align][align=center]
[/align] 风格损耗:没有采用Gram矩阵这种方式,即使会产生相似的结果。因为在AdaIN层只传递了风格特征的均值和方差,所以风格损耗只做了这些数据的匹配。同样也采用了relu1_1,relu2_1,relu3_1,relu4_1四层的feature maps。即风格损耗只是基于IN统计的损耗。

[align=left]结果分析:[/align][align=left]
[/align]质量上:

论文中作者将自己的方法与之前的三种方法(1. A. Gatys, . Image style transfer using convolutional neural networks 2. D. Ulyanov,Improved texture etworks: Maximizing quality and diversity in feed-forward tylization and texture synthesis convolutional neural networks 3. T. Q. Chen and M. Schmidt. Fast patch-based style transfer of arbitrary style.)作对比: 对于第1、2、3行和gatys和ulyanov的相比效果相当,对于第5行,稍稍落后,但是本论文算法支持任意风格,比较灵活。 总体效果与Fast Patch-based Style Transfer of Arbitrary Style相比,该方法更好。最后一行,fast patch转换失败了。
速度上: 整个生成网络的时间花费基本是content encoding、style encoding、decoding各占三分之一时间。

[align=left]控制风格的程度:[/align]
修改a参数即可。

控制颜色和区域:

[align=left]github:https://github.com/xunhuang1995/AdaIN-style[/align]
整体内容参考了这两个网址,综合了一下,方便自己日后在看: http://blog.csdn.net/qq_14975217/article/details/78638972 http://blog.csdn.net/wyl1987527/article/details/70245214?locationNum=16&fps=1
Gatys等人最近引入了一种神经算法,以另一幅图像的样式呈现内容图像,实现所谓的样式转换。但是,工作需要缓慢的迭代优化过程,这限制了其实际应用。后来有人提出了一种基于前馈神经网络的快速逼近方法,以加快神经网络的传输速度。不幸的是,速度的提高需要付出代价:网络通常绑定到一组固定的样式,无法适应任意的新样式。在本文中,我们提出了一种简单而有效的方法,它首次实现了任意样式的实时传输。我们方法的核心是一个新颖的自适应实例规范化(AdaIN)层,它将内容特征的均值和方差与样式特征的均值和方差对齐。我们的方法实现了与现有最快方法相媲美的速度,而不受对预定义样式集的限制。此外,我们的方法允许用户进行灵活的控制,如内容折中,样式插值,颜色和空间控制等,所有这些都使用单一的前馈神经网络。
该论文在CIN的基础上做了一个改进,提出了AdaIN(自适应IN层)。顾名思义,就是自己根据风格图像调整缩放和平移参数,不在需要像CIN一样保存风格特征的均值和方差,而是在将风格图像经过卷积网络后计算出均值和方差。
BN(Batch Normalization)归一化一批样例以一个单一风格为中心,但是每个样本仍然可能有自己的风格。
对一批样例进行计算每通道的均值和方差。
BNlayers在训练和测试时采用的是不同的数据集,训练时是采用小批数据。
IN(Instance Normalization)
每个样例以及每个通道都独立计算均值、方差。
IN layers在训练以及测试时使用相同的数据统计。
归一化每个样例到一个单一的风格。
总的来说batch norm是对一个batch里所有的图片的所有像素求均值和标准差。而instance norm是对单个图片的所有像素求均值和标准差。
CIN(Conditional Instance Normalization)
条件实例归一化,A learned representation for artistic style论文中主要提到的方法。网络可以通过使用相同的卷积参数来生成完全不同风格的图像,而只需要对归一化的结果进行一个平移和缩放,平移和缩放就是β_s和γ_s(s代表风格),每一个风格就是要学习这两个参数。训练多个风格就需要多组数据,如有c个feature maps和需要训练N个风格,那么总共就有2*N*C个参数需要训练。
[align=left][/align][align=left]AdaIN(Adaptive Instance Normalization)[/align][align=left]
[/align]
[align=left] 自适应实例归一化,就是把content image的feature分布拉到style image的feature分布,这样就在特征空间完成了风格变换。而由于stlye image可以任意输入,可以实现任意风格变换。这篇论文中采用的是预训练好的vgg网络relu4_1的feature空间结果作为输入的。[/align][align=left]AdaIN和CIN 很大的区别是参数不需要进行训练。[/align]
网络结构
网络结构主要分为两个部分:生成网络即style transfer network和计算损耗网络。生成网络是一个前向网络,后期用来进行风格转换网络。计算损耗网络是用来训练时进行约束的。风格转换生成网络由Encoder-AdaIN-Decoder这3部分组成。
Encoder 部分是采用预训练好的VGG网络,只使用到了Relu4_1,将风格和内容图的图像都从图像空间转到特征空间。
AdaIN层是对内容图进行归一化,这里是通过对齐内容图的每通道的feature map的均值和方差来匹配风格图每通道feature map的均值和方差。
这里的x是content image, y是style image,将归一化后的内容图的输入进行缩放和平移。
AdaIN和Fast Patch-based Style Transfer of Arbitrary Style这篇论文中提出的style swap层作用类似,都是把风格信息加入到content中。style swap 比较费时以及费内存,需要每个块和对应的所有块作比较。这两个算法的这部分都是不需要训练的。
Decoder部分是一个将feature 空间转成图像空间的网络,这部分网络一般是采用和encoder对称的网络结构,整个网络中需要训练的就是这部分网络的权重参数信息,初始可以随机一些初始化参数,通过梯度下降可以不断进行更新参数以使整个损耗函数比较小、网络逐渐收敛。池化层一般是替换成采用最近邻上采样的方式来防止棋盘效应,在encoder和decoder部分的padding一般都是采用反射填充避免边界artifacts。decoder中没有使用归一化层,因为IN/BN这些实例归一化和批归一化都是针对单个风格的。
损耗函数 损耗函数主要由两部分组成:内容损耗以及风格损耗。和最早Gatys提出的方法一致,也是采用预训练好的vgg网络的特征maps进行计算损耗。
内容损耗:转换后图像在vgg网络中Relu4_1的特征和adaIN输出feature maps的欧式距离。这里论文没有具体说明转换后图像在vgg网络中具体哪层的输出特征进行相减,但是我觉得应该肯定是Relu4_1的,和传统取的层不一致,主要是因为输出的adaIN的结果relu4_1,只能同层进行比较,才有可比性。
[align=left] [/align]
[align=left]其中t为经过adain层后的target feature maps,T(c, s)为生成的风格化图片。[/align][align=center]
[/align] 风格损耗:没有采用Gram矩阵这种方式,即使会产生相似的结果。因为在AdaIN层只传递了风格特征的均值和方差,所以风格损耗只做了这些数据的匹配。同样也采用了relu1_1,relu2_1,relu3_1,relu4_1四层的feature maps。即风格损耗只是基于IN统计的损耗。
[align=left]结果分析:[/align][align=left]
[/align]质量上:
论文中作者将自己的方法与之前的三种方法(1. A. Gatys, . Image style transfer using convolutional neural networks 2. D. Ulyanov,Improved texture etworks: Maximizing quality and diversity in feed-forward tylization and texture synthesis convolutional neural networks 3. T. Q. Chen and M. Schmidt. Fast patch-based style transfer of arbitrary style.)作对比: 对于第1、2、3行和gatys和ulyanov的相比效果相当,对于第5行,稍稍落后,但是本论文算法支持任意风格,比较灵活。 总体效果与Fast Patch-based Style Transfer of Arbitrary Style相比,该方法更好。最后一行,fast patch转换失败了。
速度上: 整个生成网络的时间花费基本是content encoding、style encoding、decoding各占三分之一时间。
[align=left]控制风格的程度:[/align]
修改a参数即可。
控制颜色和区域:
[align=left]github:https://github.com/xunhuang1995/AdaIN-style[/align]
整体内容参考了这两个网址,综合了一下,方便自己日后在看: http://blog.csdn.net/qq_14975217/article/details/78638972 http://blog.csdn.net/wyl1987527/article/details/70245214?locationNum=16&fps=1

相关文章推荐
- Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization论文理解
- Real-time tracking of multiple objects using adaptive correlation filters with complex constraints
- RNN with Adaptive Computation Time
- 309. Best Time to Buy and Sell Stock with Cooldown
- not defined in file libstdc++.so.6 withlink time reference
- Java出现No enclosing instance of type E is accessible. Must qualify the allocation with an enclosing--转
- No enclosing instance of type FactoryModel is accessible. Must qualify the allocation with an enclos
- Java出现No enclosing instance of type E is accessible. Must qualify the allocation with an enclosing
- Java出现No enclosing instance of type E is accessible. Must qualify the allocation with an enclosing
- Java出现No enclosing instance of type E is accessible. Must qualify the allocation with an enclosing[转]
- Java出现No enclosing instance of type E is accessible. Must qualify the allocation with an enclosing
- [UIDeviceRGBColor copyWithZone:]: unrecognized selector sent to instance
- No enclosing instance of type E is accessible. Must qualify the allocation with an enclosing instance of type E(e.g. x.new A() where x is an
- 时间窗和同时取送货的车辆路径问题(Vehicle Routing Problem with Simultaneous Piekup and Delivery and Time Windows,VRP
- 论文阅读《DeNet: Scalable Real-time Object Detection with Directed Sparse Sampling》
- No enclosing instance of type Demo is accessible. Must qualify the allocation with an enclosing instance of type Demo (e.g. x.new A() where x is an instance of Demo).
- 【Java-bug】No enclosing instance of type Test is accessible. Must qualify the allocation with an encl
- 使用内部类时提示No enclosing instance of type E is accessible. Must qualify the allocation with an enclosing
- Java出现No enclosing instance of type E is accessible. Must qualify the allocation with an enclosing
- leetcode_309 Best Time to Buy and Sell Stock with Cooldown