Week6_1Advice for Applying Machine Learning
2018-02-25 10:47
411 查看
Week6_1Advice for Applying Machine Learning
Week6_1Advice for Applying Machine Learning第 1 题
第 2 题
第 3 题
第 4 题
第 5 题
第 1 题
You train a learning algorithm, and find that it has unacceptably high error on the test set. You plot the learning curve, and obtain the figure below. Is the algorithm suffering from high bias, high variance, or neither?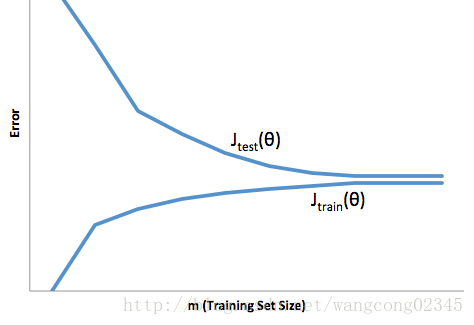
* High bias
* High variance
* Neither
* 答案: 1 high bias *
* 看刚开始的这一段,high bias(欠拟合)时,Jtrain(θ)Jtrain(θ)会很大,. 正确 **
* 看刚开始的这一段,high variance(过拟合)时,Jtrain(θ)Jtrain(θ)会比较小.从这个地方就可以区分是 high bias 还是 high variance **
第 2 题
Suppose you have implemented regularized logistic regression to classify what object is in an image (i.e., to do objectrecognition). However, when you test your hypothesis on a new set of images, you find that it makes unacceptably large
errors with its predictions on the new images. However, your hypothesis performs well (has low error) on the
training set. Which of the following are promising steps to take? Check all that apply.
Try adding polynomial features.
Get more training examples.
Try using a smaller set of features.
Use fewer training examples.
* 答案: 2 3 high variance *
* 用正则化的logistic 回归算法去做图像识别, 训练样本拟合的很好,但是在真正测试时却发现误差很大 *
* 过拟合, 可以增加样本或者减小特征数量 *
* 过拟合, 补充选项中没有的 λλ,这儿的λλ太小导致对θθ惩罚的不够,可以增大λλ *
第 3 题
Suppose you have implemented regularized logistic regressionto predict what items customers will purchase on a web
shopping site. However, when you test your hypothesis on a new
set of customers, you find that it makes unacceptably large
errors in its predictions. Furthermore, the hypothesis
performs poorly on the training set. Which of the
following might be promising steps to take? Check all that
apply.
Try to obtain and use additional features.
Try adding polynomial features.
Try using a smaller set of features.
Try increasing the regularization parameter λλ.
* 答案: 1 2 high bias *
* 用正则化的logistic 回归算法去预测顾客在购物网站上要买什么东西, 真正去预测时发现误差很大, 同时训练样本本身就拟合的不好 *
* 欠拟合, 增加特征数量 *
第 4 题
Which of the following statements are true? Check all that apply.Suppose you are training a regularized linear regression model. The recommended way to choose what value of regularization parameter λλ to use is to choose the value of λλ which gives the lowest cross validation error.
Suppose you are training a regularized linear regression model. The recommended way to choose what value of regularization parameter λλ to use is to choose the value of λλ which gives the lowest test set error.
Suppose you are training a regularized linear regression model.The recommended way to choose what value of regularization parameter λλ to use is to choose the value of λλ which gives the lowest training set error.
The performance of a learning algorithm on the training set will typically be better than its performance on the test set.
* 答案: 1 4 *
* 选项2: sigmoid是最后一步, 同时是先 Theta1*x, 再sigmoid(z) **
第 5 题
第 5 个问题Which of the following statements are true? Check all that apply.
When debugging learning algorithms, it is useful to plot a learning curve to understand if there is a high bias or high variance problem.
If a learning algorithm is suffering from high variance, adding more training examples is likely to improve the test error.
We always prefer models with high variance (over those with high bias) as they will able to better fit the training set.
If a learning algorithm is suffering from high bias, only adding more training examples may not improve the test error significantly.
* 答案: 1 2 4 *
** 当交换Θ(1)Θ(1)中的两行时,实际上就是交换了a(2)2a2(2) 与 a(2)3a3(2),
原先是 a(2)1∗0.3a1(2)∗0.3+a(2)2∗(−1.2)a2(2)∗(−1.2) 现在变为$a_2^{(2)}(-1.2)+a_1^{(2)}*0.3$$ 没什么区别 *

相关文章推荐
- Week6:Advice for Applying Machine Learning课后习题解答
- Coursera Machine Learning Week 6 - Advice for Applying Machine Learning
- Machine Learning - X. Advice for Applying Machine Learning机器学习算法的诊断和改进 (Week 6)
- Machine Learning week 6 quiz: Advice for Applying Machine Learning
- Coursera机器学习-第六周-Advice for Applying Machine Learning
- Stanford ML - Lecture 6 - Advice for applying machine learning
- advice for applying machine learning:Deciding what to do next
- Stanford Machine Learning: (4). Advice for applying Machine Learning
- 【Coursera】Machine learning - week6 : Advice for Applying Machine Learning
- 斯坦福机器学习视频笔记 Week6 关于机器学习的建议 Advice for Applying Machine Learning
- Coursera ML笔记 -----week6 Advice for Applying Machine Learning
- 应用机器学习的建议(Advice for applying machine learning)
- 【Stanford机器学习笔记】8-Advice for Applying Machine Learning
- Coursera公开课笔记: 斯坦福大学机器学习第十课“应用机器学习的建议(Advice for applying machine learning)”
- Machine Learning - 第6周(Advice for Applying Machine Learning、Machine Learning System Design)
- NG机器学习week6 Advice for Applying Machine Learning
- Advice for Applying Machine Learning(Andrew ng ML)
- Week6:Advice for Applying Machine Learning课后习题解答
- 机器学习(4)-应用机器学习的建议_Advice for Applying Machine Learning
- 测试【Machine Learning week6】Advice for Applying Machine Learning