Python3 scrapy下载网易云音乐所有(大部分)歌曲
2018-02-13 22:37
387 查看
很早之前就说要写这个的,但是中间我去写其他爬虫了,所以一直拖着没更( ˃᷄˶˶̫˶˂᷅ )
BUT,说好的要写这个爬虫那就一定要写!!
先说怎样找到我们要爬取的数据
我的思路是这样的:
主页→歌单页面→分类的各个歌单界面→分类歌单里的每一个歌单→歌单中的每一首歌(歌名,歌手,歌曲id)→歌曲下载链接
按照上述步骤
我们先到网易云音乐的主页:http://music.163.com/#
这里一定要注意,在编写爬虫代码时,后面的‘#’我们不能要!
所以代码里你要写入的链接是:http://music.163.com
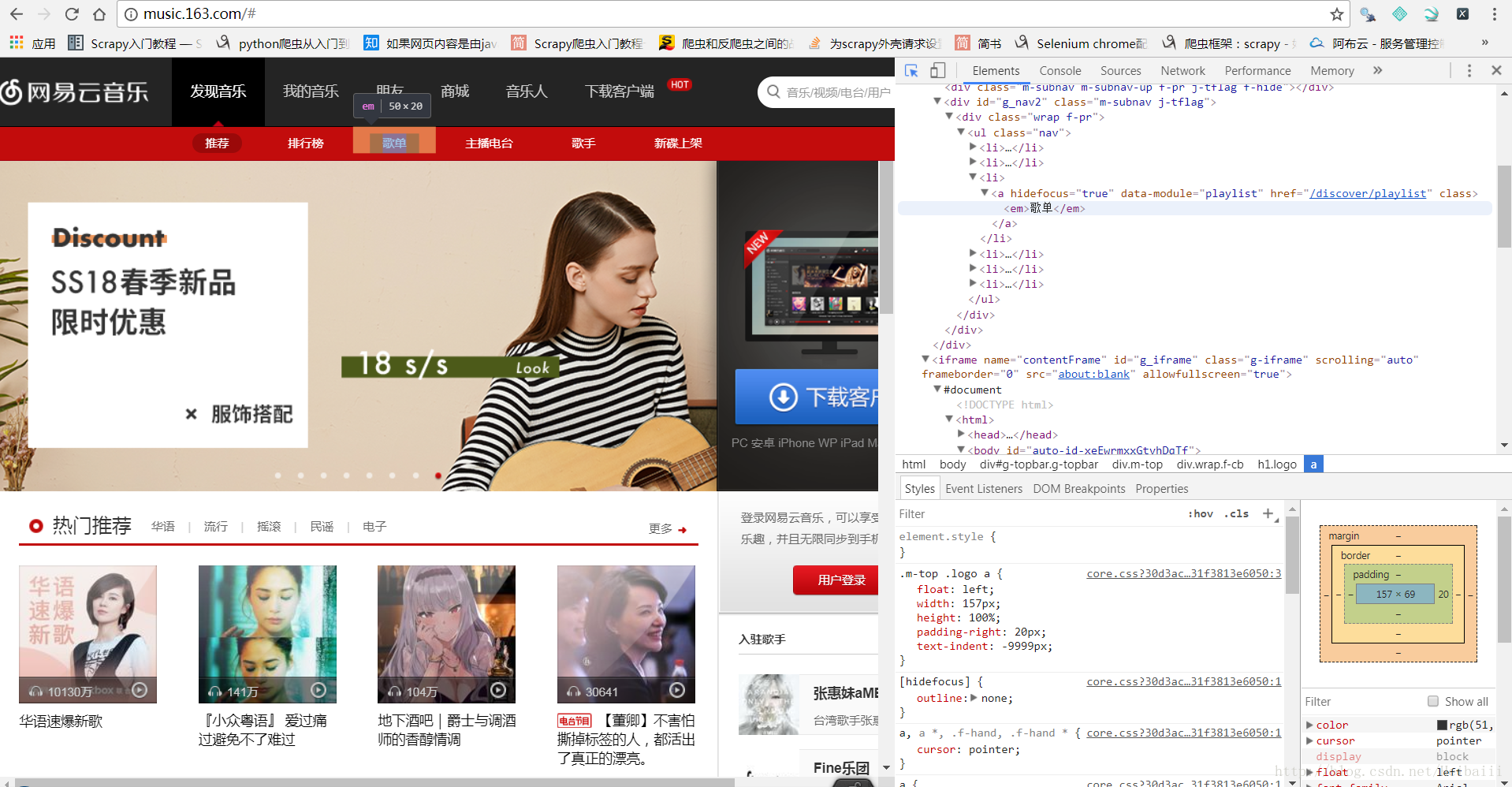
很轻松既可以找到‘歌单’这一分类的地址
接下来是‘歌单’分类的界面:
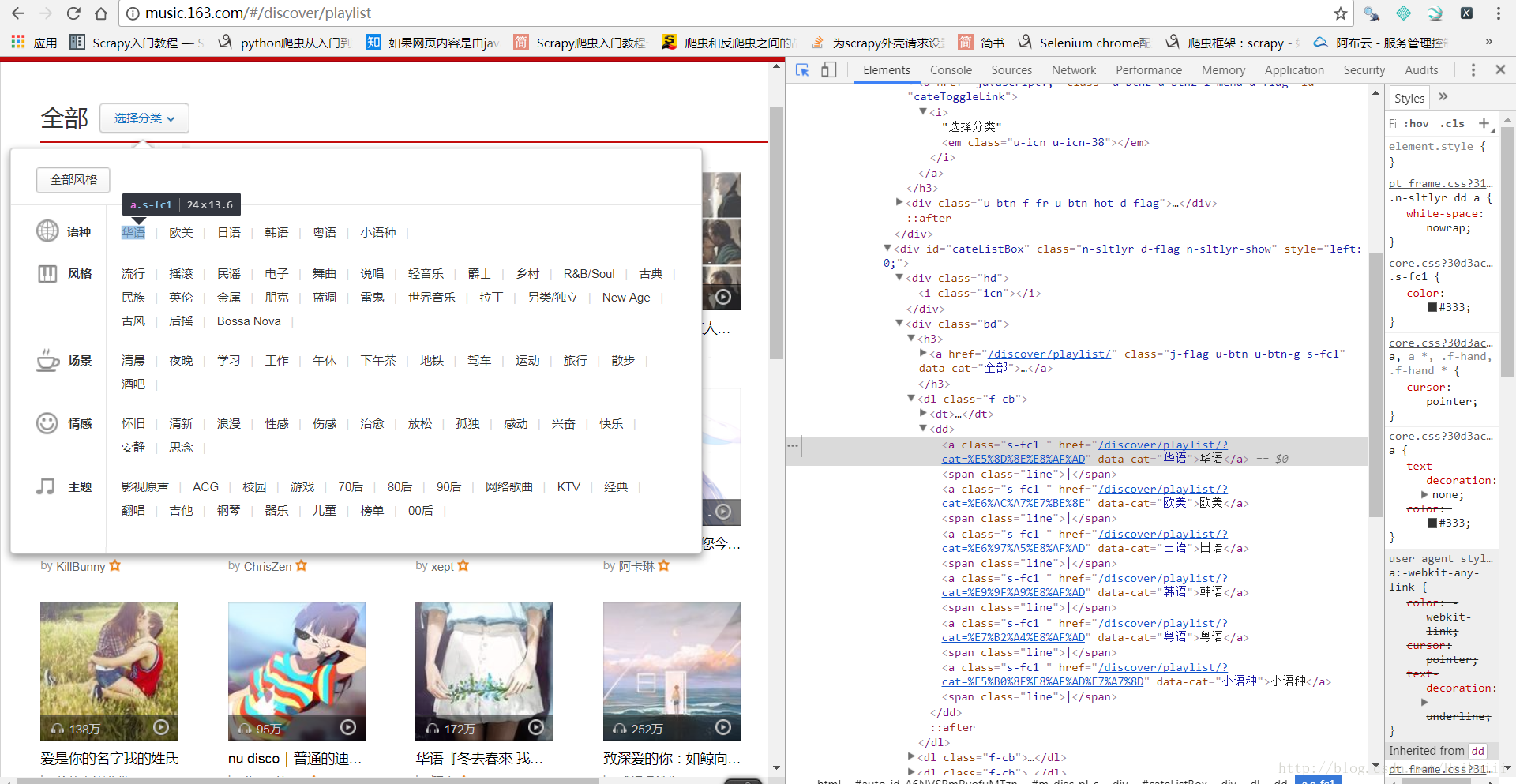
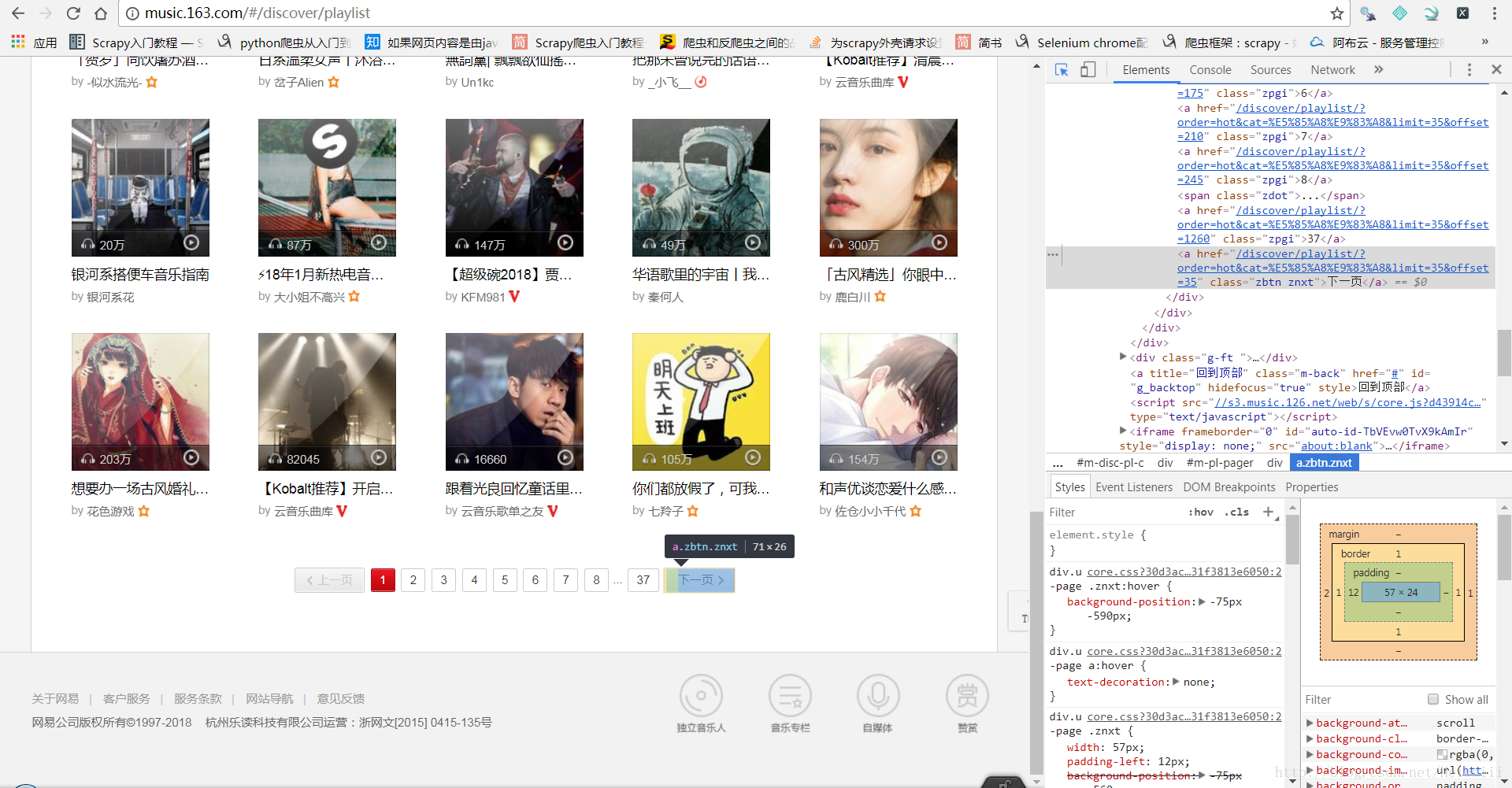
这里也可以很轻松的找到所有类别的歌单地址与下一页的地址
接着我们进入某一歌单的页面:
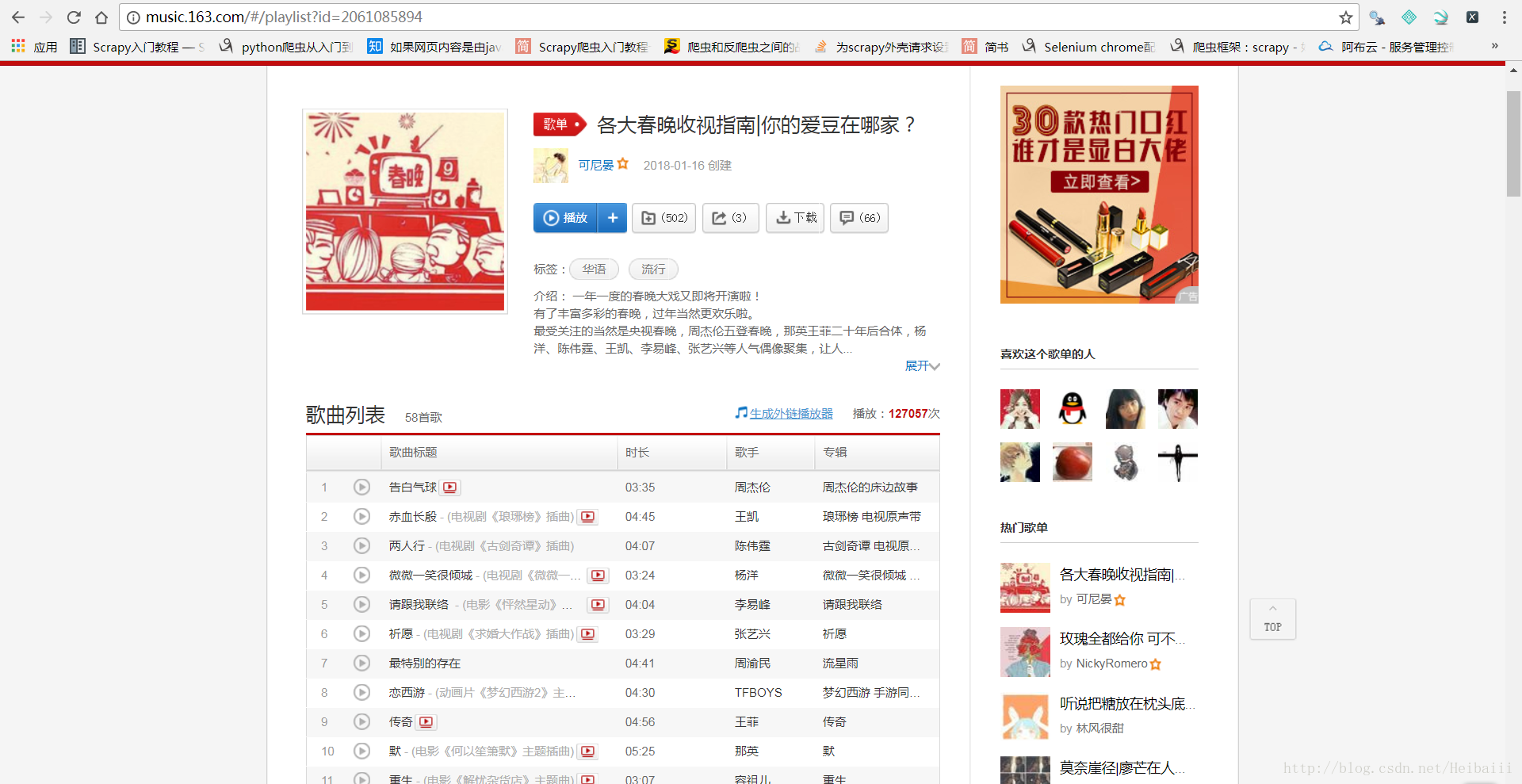
到这里你会发现,根据Elements编写的xpath路径根本找不到每一首歌的链接,因为Elments里的代码其实并不是真实源码,而是经过浏览器渲染后的代码,我们要找的源码在这里:
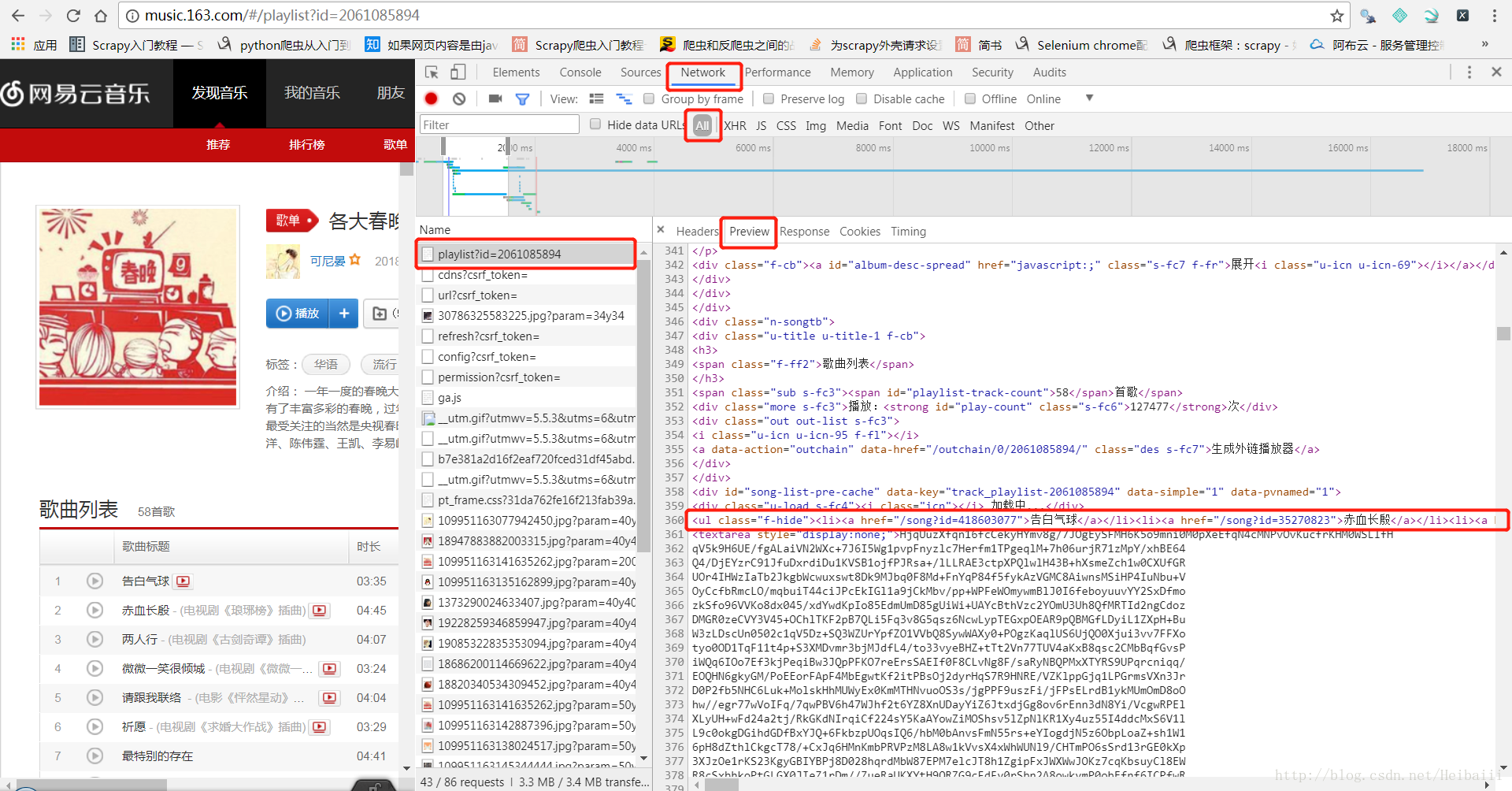
这里的才是真实源码,所以我们需要根据这个来进行xpath路径编写
找到歌曲地址后,我们进入歌曲界面获取歌名、歌手、所属专辑:
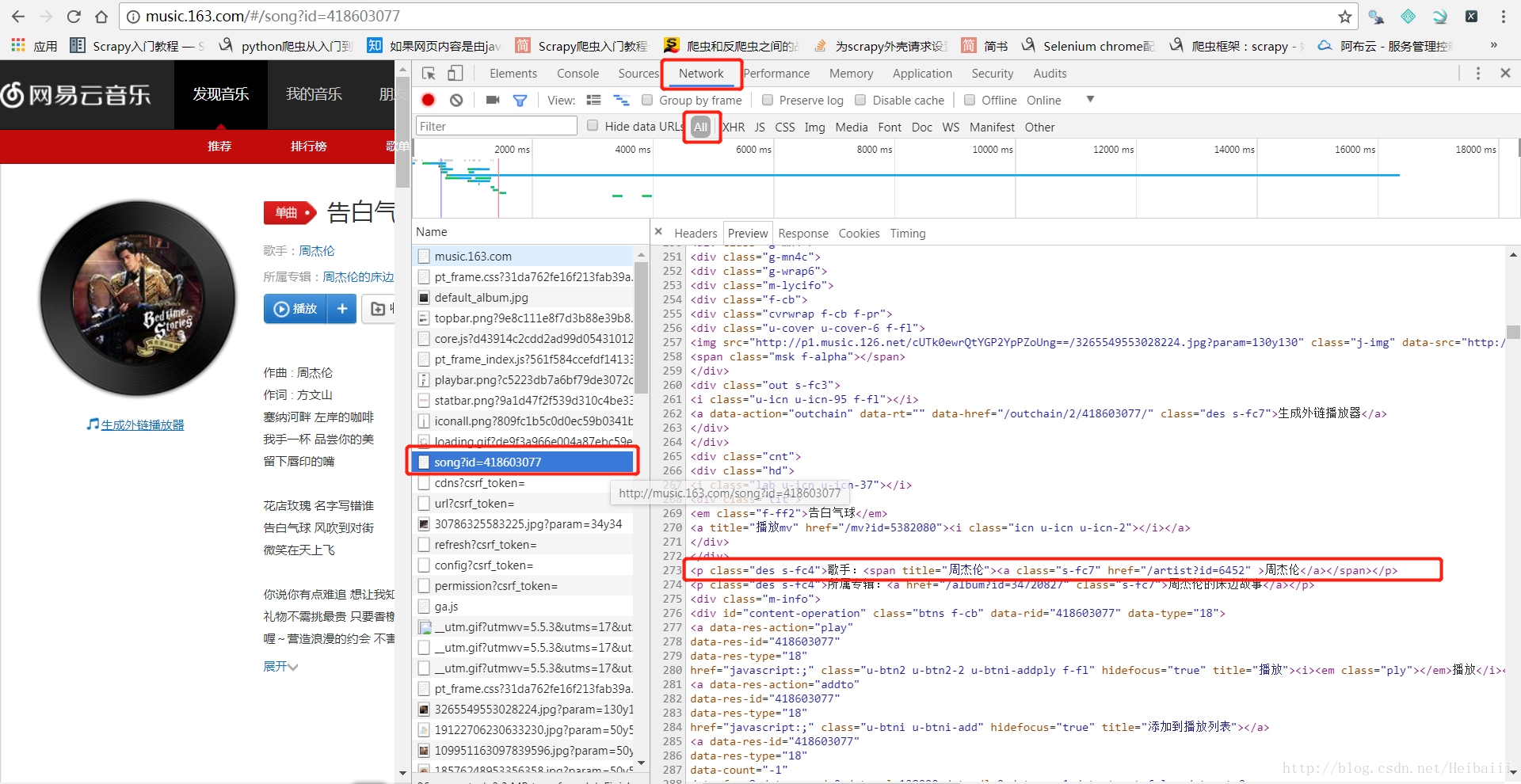
接下来就是编写代码了,写好以后是,执行时是这样的:
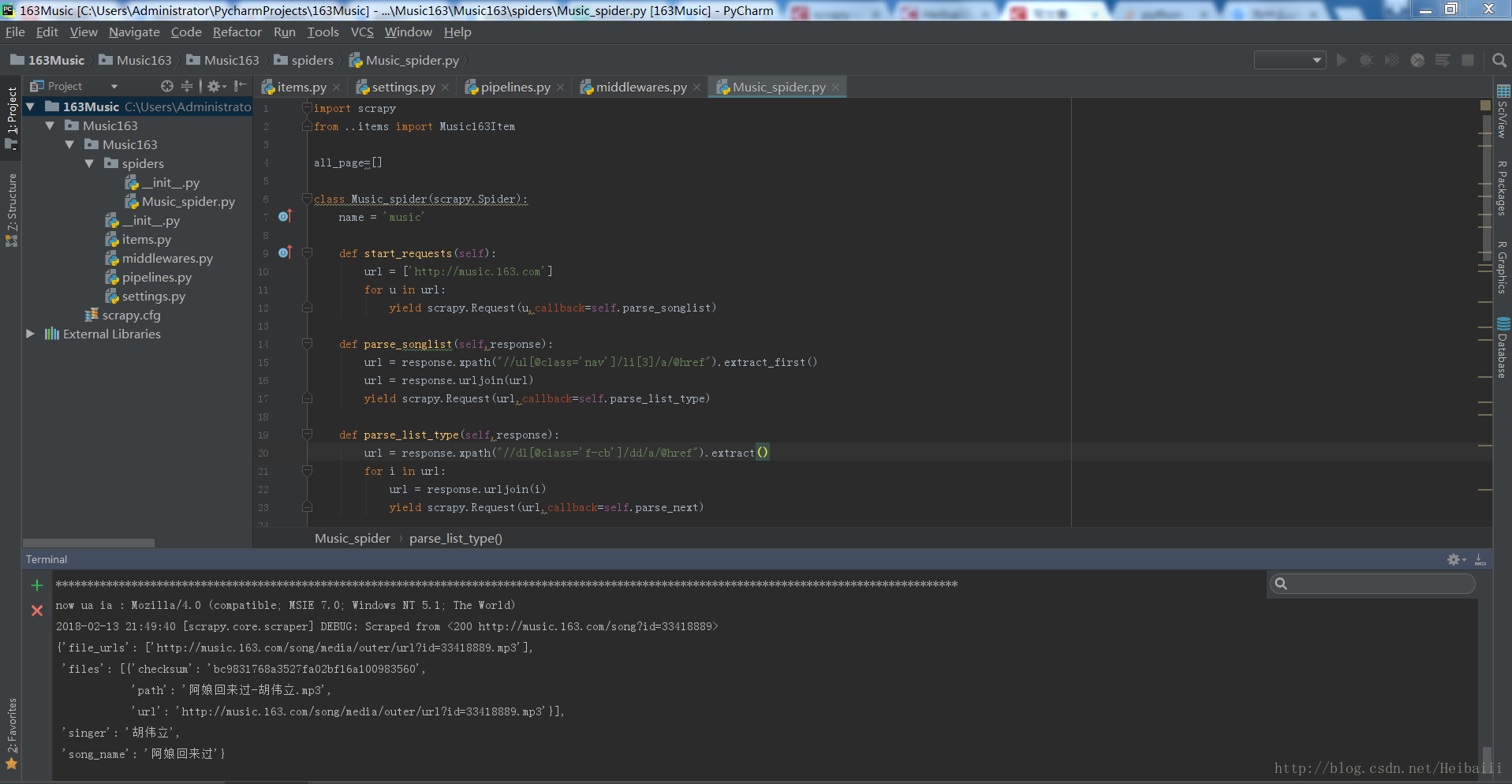
下载的部分歌曲:
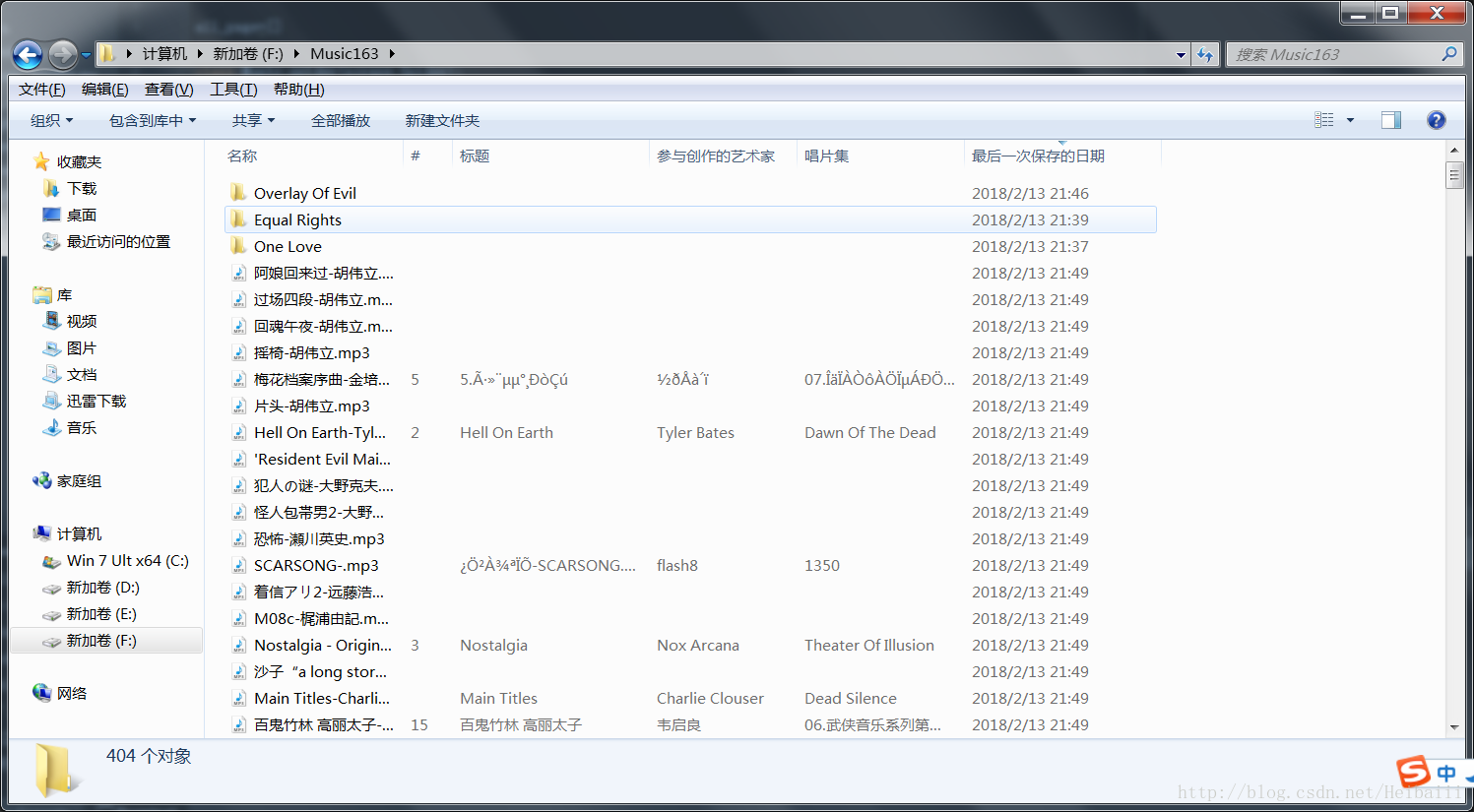
可能会下到一些空文件夹,具体是为什么我没去找原因,大家有兴趣可以研究一下
关于下载地址,把歌曲id填入这里就好了:
http://music.163.com/song/media/outer/url?id=这里填歌曲id.mp3
问我哪里来的…百度来的…
歌曲id哪里来?抓取到的歌曲链接的最后那串数字就是id了,用split()切一下就拿出来了嘛~
扩展:
shell模式下测试xpath路径时也是如此,比如某一歌单链接为:http://music.163.com/#/playlist?id=924680166
我们应该改成:http://music.163.com/playlist?id=924680166
因为加入#,我们发出的http请求会忽略#后面的内容。
最后扔上部分代码:
这次的文章就到这里了,下次见(可能懒得写,所以会要很久以后?大概吧..不过github会经常更新)
完整代码请移步github:https://github.com/KertinH/Music163
BUT,说好的要写这个爬虫那就一定要写!!
先说怎样找到我们要爬取的数据
我的思路是这样的:
主页→歌单页面→分类的各个歌单界面→分类歌单里的每一个歌单→歌单中的每一首歌(歌名,歌手,歌曲id)→歌曲下载链接
按照上述步骤
我们先到网易云音乐的主页:http://music.163.com/#
这里一定要注意,在编写爬虫代码时,后面的‘#’我们不能要!
所以代码里你要写入的链接是:http://music.163.com
很轻松既可以找到‘歌单’这一分类的地址
接下来是‘歌单’分类的界面:
这里也可以很轻松的找到所有类别的歌单地址与下一页的地址
接着我们进入某一歌单的页面:
到这里你会发现,根据Elements编写的xpath路径根本找不到每一首歌的链接,因为Elments里的代码其实并不是真实源码,而是经过浏览器渲染后的代码,我们要找的源码在这里:
这里的才是真实源码,所以我们需要根据这个来进行xpath路径编写
找到歌曲地址后,我们进入歌曲界面获取歌名、歌手、所属专辑:
接下来就是编写代码了,写好以后是,执行时是这样的:
下载的部分歌曲:
可能会下到一些空文件夹,具体是为什么我没去找原因,大家有兴趣可以研究一下
关于下载地址,把歌曲id填入这里就好了:
http://music.163.com/song/media/outer/url?id=这里填歌曲id.mp3
问我哪里来的…百度来的…
歌曲id哪里来?抓取到的歌曲链接的最后那串数字就是id了,用split()切一下就拿出来了嘛~
扩展:
shell模式下测试xpath路径时也是如此,比如某一歌单链接为:http://music.163.com/#/playlist?id=924680166
我们应该改成:http://music.163.com/playlist?id=924680166
因为加入#,我们发出的http请求会忽略#后面的内容。
最后扔上部分代码:
'''Music_spider.py'''
import scrapy
from ..items import Music163Item
all_page=[]
class Music_spider(scrapy.Spider):
name = 'music'
def start_requests(self):
url = ['http://music.163.com']
for u in url:
yield scrapy.Request(u,callback=self.parse_songlist)
def parse_songlist(self,response):
url = response.xpath("//ul[@class='nav']/li[3]/a/@href").extract_first()
url = response.urljoin(url)
yield scrapy.Request(url,callback=self.parse_list_type)
def parse_list_type(self,response):
url = response.xpath("//dl[@class='f-cb']/dd/a/@href").extract()
for i in url:
url = response.urljoin(i)
yield scrapy.Request(url,callback=self.parse_next)
def parse_next(self,response):
next = response.xpath("//div[@class='u-page']/a[contains(text(),'下一页')]/@href").extract()
if 'javascript' not in next[0]:
url = response.urljoin(next[0])
global all_page
all_page.append(url)
yield scrapy.Request(url,callback=self.parse_next)
else:
for i in all_page:
all_page = all_page[1:]
yield scrapy.Request(i,callback=self.parse_list,dont_filter=True)
def parse_list(self,response):
url = response.xpath("//ul[@class='m-cvrlst f-cb']/li/div/a/@href").extract()
for i in url:
url = response.urljoin(i)
yield scrapy.Request(url, callback=self.parse_list_song)
def parse_list_song(self,response):
url = response.xpath("//ul[@class='f-hide']/li/a/@href").extract()
for i in url:
url = response.urljoin(i)
yield scrapy.Request(url,callback=self.parse_song)
def parse_song(self,response):
i = Music163Item()
src = []
song_id = response.url.split('=')[1]
song_name = response.xpath("//em[@class='f-ff2']/text()").extract_first()
album = response.xpath("//p[@class='des s-fc4']/a[@class='s-fc7']/text()").extract_first()
singer = '&'.join(response.xpath("//p[@class='des s-fc4']/span/a/text()").extract())
song_src = 'http://music.163.com/song/media/outer/url?id={}.mp3'.format(song_id)
src.append(song_src)
i['file_urls'] = src
i['song_name'] = song_name
i['singer'] = singer
yield i这次的文章就到这里了,下次见(可能懒得写,所以会要很久以后?大概吧..不过github会经常更新)
完整代码请移步github:https://github.com/KertinH/Music163

相关文章推荐
- Python3 scrapy下载网易云音乐所有(大部分)歌曲
- python+scrapy+selenium爬取并下载麦子学院所有视频教程
- scrapy框架爬取网易云音乐billboard榜所有排行歌曲、链接、评论存入数据库中
- Python爬虫小实践:下载妹子图www.mzitu.com网站上所有的妹子图片,并按相册名字建立文件夹分好文件名
- 从XKCD网站下载自动所有漫画图片---python实现
- Python 利用scrapy爬虫通过短短50行代码下载整站短视频
- 使用Python实现下载网易云音乐的高清MV
- Python爬虫从入门到放弃(十八)之 Scrapy爬取所有知乎用户信息(上)
- 【python】爬虫2——下载亦舒博客首页所有文章
- Scrapy:Python实现scrapy框架爬虫两个网址下载网页内容信息——Jason niu
- python网络爬虫之使用scrapy下载文件
- 使用Python下载歌词并嵌入歌曲文件中的实现代码
- python 下载微信公众号文章,含图片,分词,搜索所有分词
- Python 网络爬虫 004 (编程) 如何编写一个网络爬虫,来下载(或叫:爬取)一个站点里的所有网页
- python3 批量下载网页所有图片
- Python + wGet 合璧,一键下载网页上所有的PDF
- 003_004 Python 获取列表中所有歌曲播放时间总和
- Python爬虫框架Scrapy 学习笔记 10.3 -------【实战】 抓取天猫某网店所有宝贝详情
- python使用网易云音乐 api下载mv
- Python使用scrapy采集数据过程中放回下载过大页面的方法