从XKCD网站下载自动所有漫画图片---python实现
2018-01-05 19:45
676 查看
经常跟新的网站通常有一个首页,其中有最新的帖子,以及一个“前一篇”(或上一页)按钮,用来跳转到以前的帖子。然后那个帖子也有一个“前一篇”的按钮,以此内推。这创建了一条线索,从最近的页面,直到该网站的第一个帖子,如果你希望拷贝该网站的内容,在离线的时候阅读,可以手工导航到每个页面并保存。但这是很无聊的工作,这里可以写一个程序来实现这个操作。
XKCD是一个流行的极客漫画网站,它符合这个结构(如图1所示)。首页http://xkcd.com/有一个“Prev”按钮,让用户导航到前面的漫画。手动下载每张漫画需要花费较长时间,因此可以写一个脚本,在几分钟内完成这件事。
图1 XKCD漫画网站首页
下面是程序要做的事情:
(1) 加载主页
(2) 保存该页的漫画图片
(3) 转入前一张漫画的连接
(4) 重复直到第一张漫画
这意味着代码需要做下列事情:
(1) 利用requests模块下载页面
(2) 利用Beautiful Soup找到页面中漫画图像的URL
(3) 利用iter_content()下载漫画图像,并保存到硬盘。
(4) 找到前一张漫画的链接URL,然后重复。
打开一个新的文件编辑器窗口,将它保存为downloadXkcd.py
完整程序如下:
#-*-coding:utf-8-*-
#! python3
# downloadXkcd.py - Downloads every single XKCD cominc.
import requests,os,bs4
url = 'http://xkcd.com' # starting url
os.makedirs('xkcd',exist_ok=True) # store comics in ./xkcd
while not url.endswith('#'):
# Download the page
print('Downloading page %s...'% url)
res = requests.get(url)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text,"html.parser")
# Find the URL of the comic image.
comicElem = soup.select('#comic img')
if comicElem == []:
print('Could not find comic image.')
else:
comicUrl = 'http:' + comicElem[0].get('src')
# Download the image.
print('Downloading image %s...'% (comicUrl))
res = requests.get(comicUrl)
res.raise_for_status()
# Save the image to ./xkcd.
imageFile = open(os.path.join('xkcd',os.path.basename(comicUrl)),'wb')
for chunk in res.iter_content(100000):
imageFile.write(chunk)
imageFile.close()
# Get the Prev button's url.
prevLink = soup.select('a[rel="prev"]')[0]
url = 'http://xkcd.com' + prevLink.get('href')
print('Done.')
第一步:设计程序
打开一个浏览器的开发者工具,例如谷歌chrome浏览器的位于右上角自定义控制按钮(三个竖点处),如图2所示。
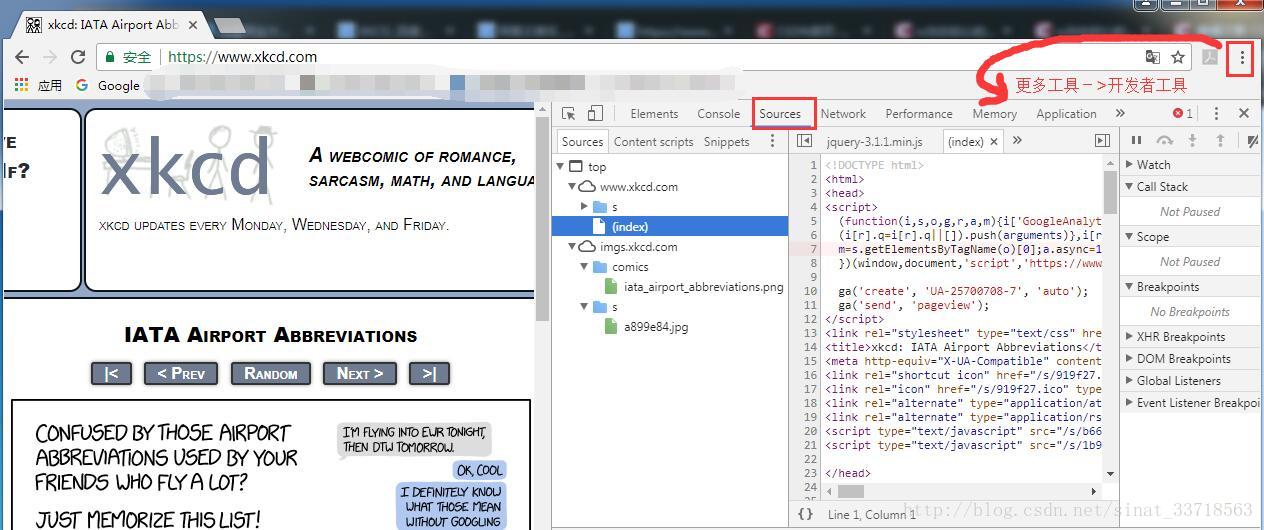
图2 谷歌浏览器开发者工具位置
接着检查该页面上的元素,你会发现下面的内容:
(1) 漫画图像文件的URL,由一个<img>元素的href属性给出
(2) <img>元素在<div id="comic">元素之内
(3) Prev按钮有一个rel HTML属性,值是prev
(4)第一张漫画的Prev按钮链接到http://xkcd.com/# URL,表明没有前一个页面了
你会有一个url变量,开始的值是'http://xkcd.com',然后反复更新(在一个for循环中),变成当前页面的Prev链接的URL。在循环的每一步,米浆下载URL上的漫画。如果URL是以‘#’结束,你就知道结束循环。
将图像文件下载到当前目录的一个名为xkcd的文件夹中。调用os.makedirs()函数。确保这个文件夹存在,并且关键字参数exist_ok=true在该文件夹已经存在时,防止该函数抛出异常。
第二步:下载网页
首先打印url,这样用户就知道程序要下载哪个URL。然后利用requests模块的request.get()函数下载它。像以往一样,马上调用Responce对象的raise_for_status()方法,如果下载发生问题,就抛出异常,并终止程序。否则,利用下载页面的文本创建一个BeautifulSoup对象。
第三步:寻找和下载漫画图像
用开发者工具检查XKCD主页后,你就知道漫画图像的<img>元素是在一个<div>元素中,它带有的id属性设置为comic。所以选择器‘#comic img’将从BeautifulSoup对象中选出正确的<img>元素。
有一些页面XKCD页面有特殊内容,不是一个简单的图像文件。这没问题,跳过他们就好了。如果选择器没有找到任何元素,那么soup.select('#comic img')将返回一个空的列表。出现这种情况时,程序将打印一条错误消息,不下载图像,继续执行。
否则,选择器将返回一个列表,包含一个<img>列表。可以从这个<img>元素中取得src属性,将它传递给requests.get(),下载这个漫画的图像文件。
第四步:保存图像,找到前一张漫画
这时候,漫画的图像文件保存在变量res中,你需要将图像数据写入硬盘的文件。
你需要为本地图像文件准备一个文件名,传递给open()。comicUrl的值类似http://imgs.xkcd.com/comics/ heartbleed_explanation.png'。你可能注意到,他看起来很像文件路径。实际上,调用os.path.basename()时传入comicUrl,它只返回URL的最后部分:'heartbleed_explanation.png'。你可以用它作为文件名,将图像保存到硬盘。用os.path.join()连接这个名称和xkcd文件夹的名称,这样程序就会在Windows下使用倒斜杠(\),在OS
X和linux下使用斜杠(\)。既然你最后得到了文件名,就可以调用open( ),用'wb'模式打开一个新文件。
保存利用Requests下载的文件时,你需要循环处理iter_content()方法的返回值。for循环中的代码将一段图像数据写入文件(每次最多10万字节),然后关闭该文件。图像现在保存到硬盘中。
然后,选择器'a[rel="prev"]识别出rel属性设置为prev的<a>元素',利用这个<a>元素的href属性,取得前一张漫画的URL,将它保存在url中。然后利用while循环针对这个漫画,再次开始整个下载过程。
参考书目:
《Python编程快速上手—让繁琐工作自动化》
XKCD是一个流行的极客漫画网站,它符合这个结构(如图1所示)。首页http://xkcd.com/有一个“Prev”按钮,让用户导航到前面的漫画。手动下载每张漫画需要花费较长时间,因此可以写一个脚本,在几分钟内完成这件事。
图1 XKCD漫画网站首页
下面是程序要做的事情:
(1) 加载主页
(2) 保存该页的漫画图片
(3) 转入前一张漫画的连接
(4) 重复直到第一张漫画
这意味着代码需要做下列事情:
(1) 利用requests模块下载页面
(2) 利用Beautiful Soup找到页面中漫画图像的URL
(3) 利用iter_content()下载漫画图像,并保存到硬盘。
(4) 找到前一张漫画的链接URL,然后重复。
打开一个新的文件编辑器窗口,将它保存为downloadXkcd.py
完整程序如下:
#-*-coding:utf-8-*-
#! python3
# downloadXkcd.py - Downloads every single XKCD cominc.
import requests,os,bs4
url = 'http://xkcd.com' # starting url
os.makedirs('xkcd',exist_ok=True) # store comics in ./xkcd
while not url.endswith('#'):
# Download the page
print('Downloading page %s...'% url)
res = requests.get(url)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text,"html.parser")
# Find the URL of the comic image.
comicElem = soup.select('#comic img')
if comicElem == []:
print('Could not find comic image.')
else:
comicUrl = 'http:' + comicElem[0].get('src')
# Download the image.
print('Downloading image %s...'% (comicUrl))
res = requests.get(comicUrl)
res.raise_for_status()
# Save the image to ./xkcd.
imageFile = open(os.path.join('xkcd',os.path.basename(comicUrl)),'wb')
for chunk in res.iter_content(100000):
imageFile.write(chunk)
imageFile.close()
# Get the Prev button's url.
prevLink = soup.select('a[rel="prev"]')[0]
url = 'http://xkcd.com' + prevLink.get('href')
print('Done.')
第一步:设计程序
打开一个浏览器的开发者工具,例如谷歌chrome浏览器的位于右上角自定义控制按钮(三个竖点处),如图2所示。
图2 谷歌浏览器开发者工具位置
接着检查该页面上的元素,你会发现下面的内容:
(1) 漫画图像文件的URL,由一个<img>元素的href属性给出
(2) <img>元素在<div id="comic">元素之内
(3) Prev按钮有一个rel HTML属性,值是prev
(4)第一张漫画的Prev按钮链接到http://xkcd.com/# URL,表明没有前一个页面了
你会有一个url变量,开始的值是'http://xkcd.com',然后反复更新(在一个for循环中),变成当前页面的Prev链接的URL。在循环的每一步,米浆下载URL上的漫画。如果URL是以‘#’结束,你就知道结束循环。
将图像文件下载到当前目录的一个名为xkcd的文件夹中。调用os.makedirs()函数。确保这个文件夹存在,并且关键字参数exist_ok=true在该文件夹已经存在时,防止该函数抛出异常。
第二步:下载网页
首先打印url,这样用户就知道程序要下载哪个URL。然后利用requests模块的request.get()函数下载它。像以往一样,马上调用Responce对象的raise_for_status()方法,如果下载发生问题,就抛出异常,并终止程序。否则,利用下载页面的文本创建一个BeautifulSoup对象。
第三步:寻找和下载漫画图像
用开发者工具检查XKCD主页后,你就知道漫画图像的<img>元素是在一个<div>元素中,它带有的id属性设置为comic。所以选择器‘#comic img’将从BeautifulSoup对象中选出正确的<img>元素。
有一些页面XKCD页面有特殊内容,不是一个简单的图像文件。这没问题,跳过他们就好了。如果选择器没有找到任何元素,那么soup.select('#comic img')将返回一个空的列表。出现这种情况时,程序将打印一条错误消息,不下载图像,继续执行。
否则,选择器将返回一个列表,包含一个<img>列表。可以从这个<img>元素中取得src属性,将它传递给requests.get(),下载这个漫画的图像文件。
第四步:保存图像,找到前一张漫画
这时候,漫画的图像文件保存在变量res中,你需要将图像数据写入硬盘的文件。
你需要为本地图像文件准备一个文件名,传递给open()。comicUrl的值类似http://imgs.xkcd.com/comics/ heartbleed_explanation.png'。你可能注意到,他看起来很像文件路径。实际上,调用os.path.basename()时传入comicUrl,它只返回URL的最后部分:'heartbleed_explanation.png'。你可以用它作为文件名,将图像保存到硬盘。用os.path.join()连接这个名称和xkcd文件夹的名称,这样程序就会在Windows下使用倒斜杠(\),在OS
X和linux下使用斜杠(\)。既然你最后得到了文件名,就可以调用open( ),用'wb'模式打开一个新文件。
保存利用Requests下载的文件时,你需要循环处理iter_content()方法的返回值。for循环中的代码将一段图像数据写入文件(每次最多10万字节),然后关闭该文件。图像现在保存到硬盘中。
然后,选择器'a[rel="prev"]识别出rel属性设置为prev的<a>元素',利用这个<a>元素的href属性,取得前一张漫画的URL,将它保存在url中。然后利用while循环针对这个漫画,再次开始整个下载过程。
参考书目:
《Python编程快速上手—让繁琐工作自动化》

相关文章推荐
- python实现从网站XKCD下载全部漫画
- 用python下载xxxx网站封面作品的所有图片
- python简易爬虫来实现自动图片下载
- python实现下载指定网址所有图片的方法
- python爬取有声小说网站实现自动下载实例
- python实现下载指定网址所有图片的方法
- python自学笔记(8)--Python简单爬虫从网站上下载图片和用第三方库request实现百度翻译
- Python爬虫小实践:下载妹子图www.mzitu.com网站上所有的妹子图片,并按相册名字建立文件夹分好文件名
- Python+selenium实现图片网站搜索后下载搜索结果的全部照片
- CodeIgniter实现从网站抓取图片并自动下载到文件夹里的方法
- CodeIgniter实现从网站抓取图片并自动下载到文件夹里的方法
- HTML5画渐变背景图片并自动下载实现步骤
- python在多玩图片上下载妹子图的实现代码
- Python 爬某个网站下载图片
- python实现网站的自动登录
- python实现虎扑网站图片爬虫
- python实现网站的js文件下载
- python自动下载人人所有好友的相册
- python实现爬虫下载漫画示例
- 一个小型的网站,比如个人网站,可以使用最简单的html静态页面就实现了,配合一些图片达到美化效果,所有的页面均存放在一个目录下,这样的网站对系统架构、性能的要求都很简单,随着互联网业务的不断丰富,网站