javaAPI 连接 HDFS 高可用配置
2018-02-13 15:06
411 查看
1.引入jar包
private FileSystem fs ;
// 实例化
config = new Configuration();
config.set("fs.defaultFS", "hdfs://mycluster");
fs = FileSystem.get(config);3.这样就可以使用 FileSystem 来操作了,如果没有加 fs.defaultFS 的配置的话就会默认读写本地磁盘。。。
hdfs路径就是 core-site.xml 里面配置的<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>因为 hdfs-site.xml 中的配置文件会引用这个 属性,所以,把配置文件加进来 client 就可以找到当前 active 的 namebnode 了,如下:
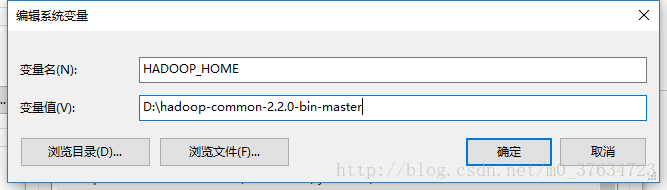
环境变量配置后可能需要重启电脑才有效,具体可以百度 “windows 环境变量 生效”
<properties>
<hdfs.version>2.8.2</hdfs.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hdfs.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hdfs.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hdfs.version}</version>
</dependency>
</dependencies>2.将 hdfs-site.xml 配置文件放到项目resources根目录下或项目根目录下,这样代码中 Configuration 对象在new 了之后会自动读取配置,代码里只需要配置一下hdfs地址即可 private Configuration config ;private FileSystem fs ;
// 实例化
config = new Configuration();
config.set("fs.defaultFS", "hdfs://mycluster");
fs = FileSystem.get(config);3.这样就可以使用 FileSystem 来操作了,如果没有加 fs.defaultFS 的配置的话就会默认读写本地磁盘。。。
hdfs路径就是 core-site.xml 里面配置的<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>因为 hdfs-site.xml 中的配置文件会引用这个 属性,所以,把配置文件加进来 client 就可以找到当前 active 的 namebnode 了,如下:
<property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <!--配置集群中所有的namenode节点的namenodeid--> <property> <name>dfs.ha.namenodes.mycluster</name> <!-- 格式为dfs.ha.namenodes.[nameservices id] --> <value>NN-93,NN-92</value> <!-- namenodeid可以自定义,下方的其他配置与其保持一致即可 --> </property>4. windows系统里需要一个插件,如果没有的话会报错(null/bin/winutils.exe),但是不会影响结果,这里有个链接,下载之后解压,然后配置环境变量 HADOOP_HOME 指向这里即可 https://pan.baidu.com/s/1pMGvBuV
环境变量配置后可能需要重启电脑才有效,具体可以百度 “windows 环境变量 生效”

相关文章推荐
- CDH开启kerberos后,HDFS连接的Java——API参数配置
- 学习日志---本地javaApi连接集群hdfs
- java连接HDFS+Kerberos配置参数示例
- javaweb JDBC 数据库连接mysql 配置代码 (直接可用)
- java汉化教程 和所需软件可用版连接
- java 连接 SQL Server 2000 详细配置(两种方法)
- JDK核心API--Java中配置信息的存取
- Java连接各种数据库的配置方法
- Java中,不用配置数据源,通过JDBC-ODBC与Access数据库建立连接
- Flex环境配置(使用Java连接SQLServer2000)[原]
- java 开发+运行环境配置+连接 sql 2008
- 通过VMWare的Webservice API连接ESX|ESXi主机的JAVA源码
- outlook 2003配置连接exchange server 2010报错——无法完成此操作。 与 Microsoft Exchange Server 的连接不可用。 Outlook 必须联机或连接才可完成该操作
- PHP配置java环境,php-java-bridge连接桥
- Java程序数据库连接,数据源配置,数据库连接池
- Java连接各种数据库的配置方法总结
- JBuilder X里配置本地API部分Java驱动程序
- java中有jar连接数据库 SqlHelper配置
- JAVA连接MYSQL配置
- JavaWeb:Tomcat下配置数据源连接数据库