Spark 1.6.1分布式集群环境搭建
2018-02-02 16:51
267 查看
一、软件准备
scala-2.11.8.tgzspark-1.6.1-bin-hadoop2.6.tgz
二、Scala 安装
1、master 机器
(1)下载 scala-2.11.8.tgz, 解压到 /opt 目录下,即: /opt/scala-2.11.8。(2)修改 scala-2.11.8 目录所属用户和用户组。
(4) 验证 Scala 安装

2、Slave机器
slave01 和 slave02 参照 master 机器安装步骤进行安装。
三、Spark 安装
1、master 机器
(1) 下载 spark-1.6.1-bin-hadoop2.6.tgz,解压到 /opt 目录下。(2) 修改 spark-1.6.1-bin-hadoop2.6 目录所属用户和用户组。
(4) Spark 配置
进入 Spark 安装目录下的 conf 目录, 拷贝 spark-env.sh.template 到 spark-env.sh。
SCALA_HOME 指定 Scala 安装目录;
SPARK_MASTER_IP 指定 Spark 集群 Master 节点的 IP 地址;
SPARK_WORKER_MEMORY 指定的是 Worker 节点能够分配给 Executors 的最大内存大小;
HADOOP_CONF_DIR 指定 Hadoop 集群配置文件目录。
将 slaves.template 拷贝到 slaves, 编辑其内容为:
2、slave机器
slave01 和 slave02 参照 master 机器安装步骤进行安装。
四、启动 Spark 集群
1、启动 Hadoop 集群
Hadoop 集群的启动可以参见之前的一篇文章 Hadoop 2.6.4分布式集群环境搭建,这里不再赘述。启动之后,可以分别在 master、slave01、slave02 上使用 jps命令查看进程信息。



2、启动 Spark 集群
(1) 启动 Master 节点运行 start-master.sh,结果如下:

可以看到 master 上多了一个新进程 Master。
(2) 启动所有 Worker 节点
运行 start-slaves.sh, 运行结果如下:

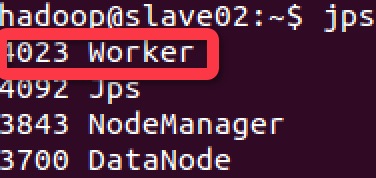
在 master、slave01 和 slave02 上使用 jps 命令,可以发现都启动了一个 Worker 进程


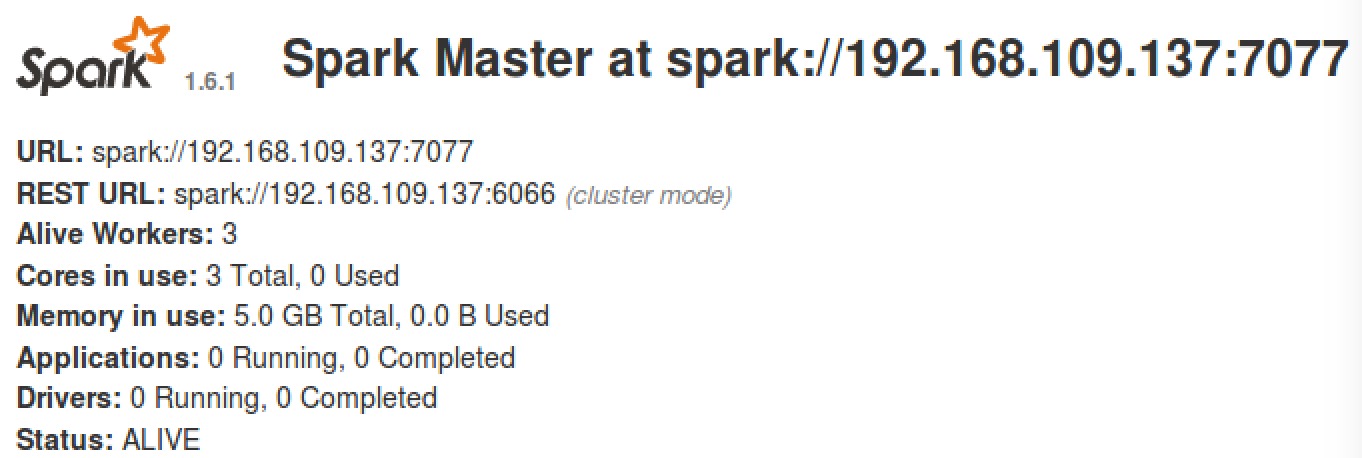
(3) 浏览器查看 Spark 集群信息。
访问:http://master:8080, 如下图:

(4) 使用 spark-shell
运行 spark-shell,可以进入 Spark 的 shell 控制台,如下:

(5) 浏览器访问 SparkUI
访问 http://master:4040, 如下图:

可以从 SparkUI 上查看一些 如环境变量、Job、Executor等信息。
至此,整个 Spark 分布式集群的搭建就到这里结束。
五、停止 Spark 集群
1、停止 Master 节点运行 stop-master.sh 来停止 Master 节点。

使用 jps 命令查看当前 java 进程
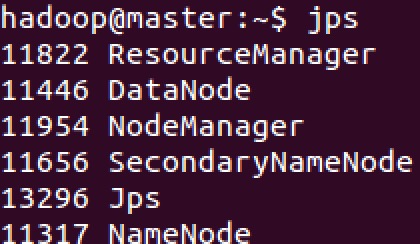
可以发现 Master 进程已经停止。
2、停止 Worker 节点
运行 stop-slaves.sh 可以停止所有的 Worker 节点

使用 jps 命令查看 master、slave01、slave02 上的进程信息:
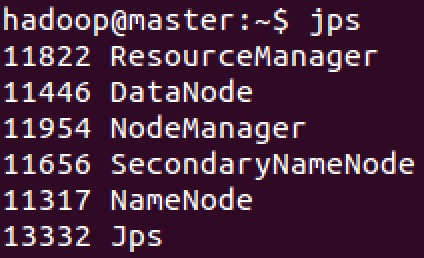
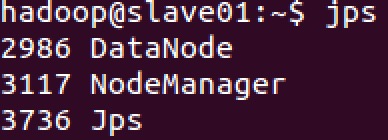
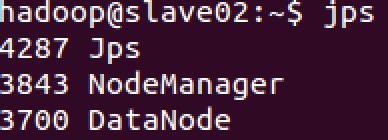
可以看到, Worker 进程均已停止,最后再停止 Hadoop 集群。

相关文章推荐
- Spark 1.6.1分布式集群环境搭建
- Spark 1.6.1分布式集群环境搭建
- spark2.2.0集群环境搭建
- 搭建spark集群环境,较为全面
- Dream------spark--spark集群的环境搭建
- Linux下搭建spark集群开发环境
- DayDayUP_大数据学习课程[2]_spark1.4.1集群环境的搭建
- spark-1.2.0 集群环境搭建
- spark筑基篇-00-Spark集群环境搭建
- Spark集群环境的搭建
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十三)Structured Streaming遇到问题:Set(TopicName-0) are gone. Some data may have been missed
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十七):kafka manager安装
- Centos7 下 spark1.6.1_hadoop2.6 分布式集群环境搭建
- [置顶] hadoop、zookeeper、hbase、spark集群环境搭建
- Spark集群环境搭建
- 6,数据挖掘环境搭建-Spark集群搭建
- CDH5.2+CM5.2+impala2+Spark1.1 集群搭建基础环境准备
- Spark集群环境的搭建
- Spark学习之(一) HDFS 集群环境搭建