寒假训练2018.1.30训练日志------二路归并排序再探究
2018-01-30 22:33
183 查看
在上次对排序问题进行总结之后,总感觉对有些知识掌握的非常混乱,刚开始学,理解的较浅显应该也是正常的,希望自己能逐渐的把这些知识系统化,理解的更深入。在上次总结的最后,有一个瑞士轮问题,在昨天的练习中,此题应该是花费了最长时间的一个题。因此下面对其在做一下探究。
2*N 名编号为 1~2N 的选手共进行R 轮比赛。每轮比赛开始前,以及所有比赛结束后,都会按照总分从高到低对选手进行一次排名。选手的总分为第一轮开始前的初始分数加上已参加过的所有比赛的得分和。总分相同的,约定编号较小的选手排名靠前。
每轮比赛的对阵安排与该轮比赛开始前的排名有关:第1 名和第2 名、第 3 名和第 4名、……、第2K – 1 名和第 2K名、…… 、第2N – 1 名和第2N名,各进行一场比赛。每场比赛胜者得1 分,负者得 0 分。也就是说除了首轮以外,其它轮比赛的安排均不能事先确定,而是要取决于选手在之前比赛中的表现。
现给定每个选手的初始分数及其实力值,试计算在R 轮比赛过后,排名第 Q 的选手编号是多少。我们假设选手的实力值两两不同,且每场比赛中实力值较高的总能获胜。
输入格式:
输入文件名为swiss.in 。
输入的第一行是三个正整数N、R 、Q,每两个数之间用一个空格隔开,表示有 2*N 名选手、R 轮比赛,以及我们关心的名次 Q。
第二行是2*N 个非负整数s1, s2, …, s2N,每两个数之间用一个空格隔开,其中 si 表示编号为i 的选手的初始分数。 第三行是2*N 个正整数w1 , w2 , …, w2N,每两个数之间用一个空格隔开,其中 wi 表示编号为i 的选手的实力值。
输出格式:
输出文件名为swiss.out。
输出只有一行,包含一个整数,即R 轮比赛结束后,排名第 Q 的选手的编号。
输入样例#1: 复制
输出样例#1: 复制
【样例解释】
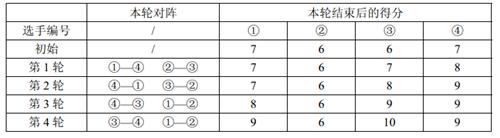
【数据范围】
对于30% 的数据,1 ≤ N ≤ 100;
对于50% 的数据,1 ≤ N ≤ 10,000 ;
对于100%的数据,1 ≤ N ≤ 100,000,1 ≤ R ≤ 50,1 ≤ Q ≤ 2N,0 ≤ s1, s2, …, s2N≤10^8,1 ≤w1, w2 , …, w2N≤ 10^8。
概述:该题描述即给定参赛人员的 初始分数及实力值,在一次排序之后让相邻的两组比赛(第1和第2,3和4,5和6。。。。。。),本次比赛结束后再次大排队,同时重复上述过程,在后经过R轮比赛后输出第Q名选手的编号。
思路:
对于本题,因为有多个与参赛人员相关的变量,所以很容易想到用结构体实现一个容器。
刚开始考虑用快排,即根据题目描述,在每次两两比较之后用sort进行大排队,但此时时间复杂度o(r*nlogn+r*n),很明显当n和r足够大时会超时。
第一次提交代码:
#1AC0ms/2023KB
#2TLE
#3WA
#4AC0ms/2070KB
#5WA
#6AC184ms/2265KB
#7AC488ms/2589KB
#8TLE
#9TLE
#10TLE
之后考虑使用归并排序,但由于开始对归并排序认识不足,认为归并排序无非就是一个模板,只要写出来就可以和STL中的sort一样尽情使用了,所以导致第二次也是各种错误。
第二次提交代码:
#include<bits/stdc++.h>
using namespace std;
struct node
{
int strength,f_score,index;
}a[200001];
node r[200001];
void msort(int x,int y)//归并排序的模板,在实现的时候也是好不容易才感觉符合题目要求,只不过。。。
{
if(x==y)return ;
int mid=(x+y)/2;
int p=x,q=mid+1,i=x;
msort(x,mid);
msort(mid+1,y);
while(p<=mid||q<=y)
{
if(q>y||(p<=mid&&a[p].f_score>=a[q].f_score))
{
if(a[p].f_score==a[q].f_score)
{
if(a[p].index>a[q].index)r[i++]=a[q++];
else r[i++]=a[p++];
}
else r[i++]=a[p++];
}
else r[i++]=a[q++];
}
for(i=x;i<=y;++i)a[i]=r[i];
}
bool complare(node x,node y)
{
if(x.f_score==y.f_score)return x.index<y.index;
else return x.f_score>y.f_score;
}
int main()
{
int N,R,Q;
cin>>N>>R>>Q;
for(int i=1;i<=2*N;++i)cin>>a[i].f_score,a[i].index=i;
for(int i=1;i<=2*N;++i)cin>>a[i].strength;
sort(a+1,a+1+N*2,complare);
for(int i=1;i<=R;++i)
{
for(int j=1;j<=2*N;j+=2)
{
if(a[j].strength>a[j+1].strength)a[j].f_score+=1;
else
a[j+1].f_score+=1;
}
msort(1,N*2);//时间复杂度相比较第一次提交并没有改变QAQ,还是o(r*(n+nlogn))。
}
cout<<a[Q].index;
return 0;
}
#1AC0ms/1976KB
#2TLE
#3AC8ms/4464KB
#4WA
#5WA
#6AC148ms/2523KB
#7AC408ms/3203KB
#8WA
#9TLE
#10TLE
明显可以看出这样其实和之前的快排并没有多大区别,反而代码更复杂了,空间复杂度更高了。
最后,在看了大佬们的题解之后,我才明白这题考察的确实是归并排序,但却不是直接去用模板,可能是考察一种归并或是分治的思想吧。在所有队伍两两相互比赛的时候,其实就已经形成了2个有序数列,这已经实现了归并排序中划分与排序两个步骤,因此我们只需要对排序后的两个有序数列进行合并操作就可以了。此处可使用一个合并函数merge来实现。
merge(first1,last1,first2,last2,result,compare);
firs1t为第一个容器的首迭代器,last1为第一个容器的末迭代器
first2为第二个容器的首迭代器,last2为容器的末迭代器,
result为存放结果的容器,comapre为比较函数(可略写,默认为合并为一个升序序列)。
所以最后AC的代码:
#include<bits/stdc++.h>
using namespace std;
struct node
{
int strength,f_score,index;
}a[200001];
node b[100001],c[100001];
bool complare(node x,node y)
{
if(x.f_score==y.f_score)return x.index<y.index;
else return x.f_score>y.f_score;
}
int main()
{
int N,R,Q;
cin>>N>>R>>Q;
for(int i=1;i<=2*N;++i)cin>>a[i].f_score,a[i].index=i;
for(int i=1;i<=2*N;++i)cin>>a[i].strength;
sort(a+1,a+1+N*2,complare);
for(int i=1;i<=R;++i)
{
int p=1,q=1;
for(int j=1;j<=2*N;j+=2)
{
if(a[j].strength>a[j+1].strength)
{
a[j].f_score+=1;
b[p++]=a[j];
c[q++]=a[j+1];
} // 时间复杂度:o(r*(n+n))
else
{
a[j+1].f_score+=1;
c[q++]=a[j];
b[p++]=a[j+1];
}
}
merge(b+1,b+p,c+1,c+q,a+1,complare);
}
cout<<a[Q].index;
return 0;
}
#1AC0ms/1996KB
#2AC336ms/6652KB
#3AC0ms/1988KB
#4AC0ms/2039KB
#5AC8ms/2417KB
#6AC32ms/2488KB
#7AC84ms/3289KB
#8AC160ms/4359KB
#9AC244ms/6718KB
#10AC312ms/6585KB
总结:
从本次分析可以看出,对于一般题目,我们尝使用的是快排或sort,但对于有些题目来说,用快排时间复杂度确实很高,就目前小白的知识水平来说这时我们可以考虑归并,但一定要题目中有符合归并思想的描述,就比如本题的两两比较,之后我们要利用题目描述完成归并排序,而不是把它当作一个模板,生搬硬套。否则,用快排和归并的平均时间复杂度都是o(nlogn),并没有什么区别,反而会损失更多的辅助空间。
最后,看了一下午,对于merge函数的理解感觉还不是很到位,明天一定要搞懂它,其次,要开始贪心的学习了。加油!!!
题目描述
2*N 名编号为 1~2N 的选手共进行R 轮比赛。每轮比赛开始前,以及所有比赛结束后,都会按照总分从高到低对选手进行一次排名。选手的总分为第一轮开始前的初始分数加上已参加过的所有比赛的得分和。总分相同的,约定编号较小的选手排名靠前。每轮比赛的对阵安排与该轮比赛开始前的排名有关:第1 名和第2 名、第 3 名和第 4名、……、第2K – 1 名和第 2K名、…… 、第2N – 1 名和第2N名,各进行一场比赛。每场比赛胜者得1 分,负者得 0 分。也就是说除了首轮以外,其它轮比赛的安排均不能事先确定,而是要取决于选手在之前比赛中的表现。
现给定每个选手的初始分数及其实力值,试计算在R 轮比赛过后,排名第 Q 的选手编号是多少。我们假设选手的实力值两两不同,且每场比赛中实力值较高的总能获胜。
输入输出格式
输入格式:输入文件名为swiss.in 。
输入的第一行是三个正整数N、R 、Q,每两个数之间用一个空格隔开,表示有 2*N 名选手、R 轮比赛,以及我们关心的名次 Q。
第二行是2*N 个非负整数s1, s2, …, s2N,每两个数之间用一个空格隔开,其中 si 表示编号为i 的选手的初始分数。 第三行是2*N 个正整数w1 , w2 , …, w2N,每两个数之间用一个空格隔开,其中 wi 表示编号为i 的选手的实力值。
输出格式:
输出文件名为swiss.out。
输出只有一行,包含一个整数,即R 轮比赛结束后,排名第 Q 的选手的编号。
输入输出样例
输入样例#1: 复制2 4 2 7 6 6 7 10 5 20 15
输出样例#1: 复制
1
说明
【样例解释】【数据范围】
对于30% 的数据,1 ≤ N ≤ 100;
对于50% 的数据,1 ≤ N ≤ 10,000 ;
对于100%的数据,1 ≤ N ≤ 100,000,1 ≤ R ≤ 50,1 ≤ Q ≤ 2N,0 ≤ s1, s2, …, s2N≤10^8,1 ≤w1, w2 , …, w2N≤ 10^8。
概述:该题描述即给定参赛人员的 初始分数及实力值,在一次排序之后让相邻的两组比赛(第1和第2,3和4,5和6。。。。。。),本次比赛结束后再次大排队,同时重复上述过程,在后经过R轮比赛后输出第Q名选手的编号。
思路:
对于本题,因为有多个与参赛人员相关的变量,所以很容易想到用结构体实现一个容器。
刚开始考虑用快排,即根据题目描述,在每次两两比较之后用sort进行大排队,但此时时间复杂度o(r*nlogn+r*n),很明显当n和r足够大时会超时。
第一次提交代码:
#include<bits/stdc++.h>
using namespace std;
struct node
{
int strength,f_score,index;
}a[200001];
bool complare(node x,node y)
{
if(x.f_score==y.f_score)return x.index<y.index;
else return x.f_score>y.f_score;
}
int main()
{
int N,R,Q;
cin>>N>>R>>Q;
for(int i=1;i<=2*N;++i)cin>>a[i].f_score,a[i].index=i;
for(int i=1;i<=2*N;++i)cin>>a[i].strength;
for(int i=1;i<=R;++i)
{
for(int j=1;j<=2*N;j+=2)
{
if(a[j].strength>a[j+1].strength)a[j].f_score+=1;
else
a[j+1].f_score+=1;
}
sort(a+1,a+1+N*2,complare);
}
cout<<a[Q].index;
return 0;
}#1AC0ms/2023KB
#2TLE
#3WA
#4AC0ms/2070KB
#5WA
#6AC184ms/2265KB
#7AC488ms/2589KB
#8TLE
#9TLE
#10TLE
之后考虑使用归并排序,但由于开始对归并排序认识不足,认为归并排序无非就是一个模板,只要写出来就可以和STL中的sort一样尽情使用了,所以导致第二次也是各种错误。
第二次提交代码:
#include<bits/stdc++.h>
using namespace std;
struct node
{
int strength,f_score,index;
}a[200001];
node r[200001];
void msort(int x,int y)//归并排序的模板,在实现的时候也是好不容易才感觉符合题目要求,只不过。。。
{
if(x==y)return ;
int mid=(x+y)/2;
int p=x,q=mid+1,i=x;
msort(x,mid);
msort(mid+1,y);
while(p<=mid||q<=y)
{
if(q>y||(p<=mid&&a[p].f_score>=a[q].f_score))
{
if(a[p].f_score==a[q].f_score)
{
if(a[p].index>a[q].index)r[i++]=a[q++];
else r[i++]=a[p++];
}
else r[i++]=a[p++];
}
else r[i++]=a[q++];
}
for(i=x;i<=y;++i)a[i]=r[i];
}
bool complare(node x,node y)
{
if(x.f_score==y.f_score)return x.index<y.index;
else return x.f_score>y.f_score;
}
int main()
{
int N,R,Q;
cin>>N>>R>>Q;
for(int i=1;i<=2*N;++i)cin>>a[i].f_score,a[i].index=i;
for(int i=1;i<=2*N;++i)cin>>a[i].strength;
sort(a+1,a+1+N*2,complare);
for(int i=1;i<=R;++i)
{
for(int j=1;j<=2*N;j+=2)
{
if(a[j].strength>a[j+1].strength)a[j].f_score+=1;
else
a[j+1].f_score+=1;
}
msort(1,N*2);//时间复杂度相比较第一次提交并没有改变QAQ,还是o(r*(n+nlogn))。
}
cout<<a[Q].index;
return 0;
}
#1AC0ms/1976KB
#2TLE
#3AC8ms/4464KB
#4WA
#5WA
#6AC148ms/2523KB
#7AC408ms/3203KB
#8WA
#9TLE
#10TLE
明显可以看出这样其实和之前的快排并没有多大区别,反而代码更复杂了,空间复杂度更高了。
最后,在看了大佬们的题解之后,我才明白这题考察的确实是归并排序,但却不是直接去用模板,可能是考察一种归并或是分治的思想吧。在所有队伍两两相互比赛的时候,其实就已经形成了2个有序数列,这已经实现了归并排序中划分与排序两个步骤,因此我们只需要对排序后的两个有序数列进行合并操作就可以了。此处可使用一个合并函数merge来实现。
merge(first1,last1,first2,last2,result,compare);
firs1t为第一个容器的首迭代器,last1为第一个容器的末迭代器
first2为第二个容器的首迭代器,last2为容器的末迭代器,
result为存放结果的容器,comapre为比较函数(可略写,默认为合并为一个升序序列)。
所以最后AC的代码:
#include<bits/stdc++.h>
using namespace std;
struct node
{
int strength,f_score,index;
}a[200001];
node b[100001],c[100001];
bool complare(node x,node y)
{
if(x.f_score==y.f_score)return x.index<y.index;
else return x.f_score>y.f_score;
}
int main()
{
int N,R,Q;
cin>>N>>R>>Q;
for(int i=1;i<=2*N;++i)cin>>a[i].f_score,a[i].index=i;
for(int i=1;i<=2*N;++i)cin>>a[i].strength;
sort(a+1,a+1+N*2,complare);
for(int i=1;i<=R;++i)
{
int p=1,q=1;
for(int j=1;j<=2*N;j+=2)
{
if(a[j].strength>a[j+1].strength)
{
a[j].f_score+=1;
b[p++]=a[j];
c[q++]=a[j+1];
} // 时间复杂度:o(r*(n+n))
else
{
a[j+1].f_score+=1;
c[q++]=a[j];
b[p++]=a[j+1];
}
}
merge(b+1,b+p,c+1,c+q,a+1,complare);
}
cout<<a[Q].index;
return 0;
}
#1AC0ms/1996KB
#2AC336ms/6652KB
#3AC0ms/1988KB
#4AC0ms/2039KB
#5AC8ms/2417KB
#6AC32ms/2488KB
#7AC84ms/3289KB
#8AC160ms/4359KB
#9AC244ms/6718KB
#10AC312ms/6585KB
总结:
从本次分析可以看出,对于一般题目,我们尝使用的是快排或sort,但对于有些题目来说,用快排时间复杂度确实很高,就目前小白的知识水平来说这时我们可以考虑归并,但一定要题目中有符合归并思想的描述,就比如本题的两两比较,之后我们要利用题目描述完成归并排序,而不是把它当作一个模板,生搬硬套。否则,用快排和归并的平均时间复杂度都是o(nlogn),并没有什么区别,反而会损失更多的辅助空间。
最后,看了一下午,对于merge函数的理解感觉还不是很到位,明天一定要搞懂它,其次,要开始贪心的学习了。加油!!!

相关文章推荐
- 寒假训练2018.2.7训练日志------dp学习(二)尼克的任务
- 寒假训练2018.2.6训练日志------dp学习(一)
- 寒假训练2018.1.31训练日志------贪心基础学习
- 寒假训练2018.2.2训练日志------贪心基础题目练习总结(二)
- 寒假训练2018.2.3--2.5训练日志------dp学习
- python二路归并排序实现法
- 2018_bzu_寒假训练计划
- 【word2vec】之 训练模型结果的结构探究 模型改造 python gensim
- 归并排序(二路归并)
- 寒假训练--KMP--poj3461Oulipo
- 寒假训练--01背包,完全背包--小P的故事——神奇的Dota
- 寒假训练--并查集--小鑫的城堡
- sduacm16级寒假训练 动态规划(一)
- ACM练级日志: CodeForces 414C 归并排序、逆序数和栈内存
- 2016寒假训练——栈模拟
- 寒假训练—2018.3.1
- 寒假训练报告2.2(数论基础)
- SDAU训练日志第十篇----------动态规划(6)(2018年2月7日)
- 二路归并排序实现
- 寒假第四周训练——DFS题目汇总