机器学习入门笔记(一):有关概念介绍
2018-01-26 20:44
302 查看
1.什么是机器学习
简单来说就是在现有的以往数据基础上,通过相应的算法对机器进行训练生成模型,然后对未来做出预测。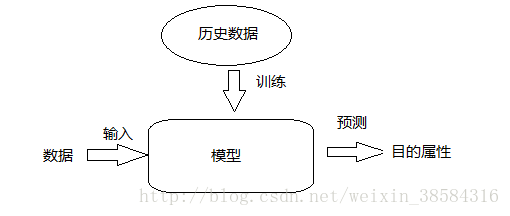
2.机器学习流程

一个典型的机器学习流程大致可以分为以上几个步骤,下面对每一步骤进行简要的解释:
(1)场景解析
通过对所要实现的业务进行分析,对场景进行抽象,选择相应的算法。例如采取监督学习还是非监督学习,以及进一步的分类、聚类、文本分析、回归算法等的选取。
(2)数据预处理
主要对于业务数据进行相应的处理,如采样、归一化、标准化、去噪等处理。提高数据集的质量,对于数据的训练结果有很大的影响。主要是数据ETL工程。
(3)特征工程
对一些不易进行数学运算的特征进行数据抽象,使之易于运算。对特征进行评估,还包括特征衍生、特征降维等一些操作。是机器学习中非常重要的一环。
(4)模型训练
通过对数据进行预处理和特征工程后,把数据代入模型中进行训练,最后生成模型。并把要预测数据输入模型,得出结果。
(5)评估
对模型的质量进行评价,同时也是对整个机器学习过程进行评估。
(6)进行预测
对实际的需要进行预测。包括对每天新产生的数据进行训练,更新模型。
3.算法分类
具体的机器学习算法多达几十种,在这里我们主要分为四种算法:(1)监督学习(supervised learning)
算法中用于训练的数据都有特征值和目标值,模型的生成本质上为特征值和目标值的映射关系的形成。
(2)无监督学习(unsupervised learning)
没有确定的目标值,不依赖于打包数据的机器学习算法。多通过距离和密度等进行相关算法。
(3)半监督学习(semi-supervised learning)
监督算法的打标是一件费时费力的事情,半监督算法对于分类的算法有一定的难度,半监督学习通过对部分数据进行打标训练来生成模型。目前在许多场景下有广泛的应用。
(4)强化学习(reinforcement learning)
整个算法系统不断的与外界进行交互,取得反馈,根据反馈做出相应的决策。如阿尔法狗的算法等。
具体的分类如下:
<
| 监督学习 | k-紧邻、逻辑回归、随机森林、朴素贝叶斯、支持向量机(svm) |
| 非监督学习 | DBSCAN、协同过滤、LDA、K-means |
| 半监督学习 | 标签传播 |
| 强化学习 | 隐马尔科夫 |
4.一些基本概念
(1)过拟合(over-fitting)在对训练数据进行训练时准确率很高,但在实际的应用中准确率却下降,迁移性较低。模型偏离真正模型,过度符合训练集,
(2)精确率(precision)、召回率(Recall)、F1值
True Positive(真正, TP):将正类预测为正类数.
True Negative(真负 , TN):将负类预测为负类数.
False Positive(假正, FP):将负类预测为正类数
False Negative(假负 , FN):将正类预测为负类数
计算公式
精确率 = TP/(TP+FP)
召回率 = TP/(TP+FN)
F1值=2*精确率*召回率/(精确率+召回率)
精确率和覆盖度分别从不同的维度上对模型结果进行了评估,F1值则综合两者的准确性和覆盖度进行评估,是前两个指标的综合。
(3)ROC和AUC
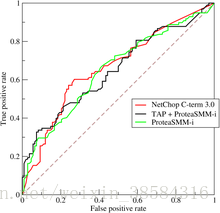
如上图:fp值为横坐标,tp值为纵坐标,这个曲线称作ROC曲线,可以看出,图像越靠近左上角则模型的效果越好。
曲线与x轴所包含的面积成为AUC值,AUC值越大说明模型的拟合效果越好,AUC值在0--1之间,AUC值到达0.9以上时,说明这个模型的效果较好。

相关文章推荐
- 程序员的机器学习入门笔记(一):基本概念介绍
- 程序员的机器学习入门笔记(二):Python常用库的介绍,及安装(Centos 6.5)
- 程序员的机器学习入门笔记(六):决策树的入门介绍
- 机器学习入门——概念介绍
- 【机器学习入门】Andrew NG《Machine Learning》课程笔记之二 :基本概念、代价函数、梯度下降和线性回归
- 程序员的机器学习入门笔记(五):文本分类的入门介绍
- [机器学习入门] 李宏毅机器学习笔记-24(introduction of Structured Learning;结构化学习介绍)
- 程序员的机器学习入门笔记(七):推荐系统入门介绍
- [机器学习入门] 李宏毅机器学习笔记-29 (Sequence Labeling Problem part 1;结构化预测-序列标记 part 1)
- MongoDB快速入门笔记(二)之MongoDB的概念及简单操作
- iPhone开发入门笔记(三)—关于数据类型介绍 (NSObject)
- 机器学习入门笔记——线性回归
- [机器学习入门] 李宏毅机器学习笔记-2 (Regression:Case Study ;回归:案例研究)
- [机器学习入门] 李宏毅机器学习笔记-15 (Unsupervised Learning: Word Embedding;无监督学习:词嵌入)
- 机器学习笔记——基础概念汇总
- Oracle RAC学习笔记:基本概念及入门 03
- [机器学习入门] 李宏毅机器学习笔记-26(Structured Support Vector Machine part 1;结构化支持向量机part 1)
- [机器学习入门] 李宏毅机器学习笔记-10 (Tips for Deep Learning;深度学习小贴士)
- 机器学习入门学习笔记:(4.1)SVM算法
- 先搞懂这八大基础概念,再谈机器学习入门!