机器学习中特征归一化的方法
2018-01-25 20:33
246 查看
数据标准化(归一化)处理是数据挖掘的一项基础工作,不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。以下是两种常用的归一化方法:
也称为离差标准化、线性函数归一化,是对原始数据的线性变换,使结果值映射到[0 - 1]之间。转换函数如下:
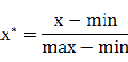
其中max为样本数据的最大值,min为样本数据的最小值。这种方法有个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1,转化函数为:
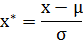
其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
1、在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,Z-score
standardization表现更好。
2、在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用第一种方法或其他归一化方法。比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0
255]的范围。
参考:http://blog.csdn.net/zbc1090549839/article/details/44103801
一、min-max标准化(Min-Max Normalization)
也称为离差标准化、线性函数归一化,是对原始数据的线性变换,使结果值映射到[0 - 1]之间。转换函数如下:
其中max为样本数据的最大值,min为样本数据的最小值。这种方法有个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
二、Z-score标准化方法
这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1,转化函数为: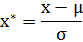
其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
1、在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,Z-score
standardization表现更好。
2、在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用第一种方法或其他归一化方法。比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0
255]的范围。
参考:http://blog.csdn.net/zbc1090549839/article/details/44103801

相关文章推荐
- 机器学习--特征缩放/均值归一化
- 特征向量的归一化方法
- 机器学习(一): python三种特征选择方法
- 机器学习中,有哪些特征选择的工程方法?
- 机器学习之特征选择方法
- 机器学习之(四)特征工程以及特征选择的工程方法
- 机器学习之特征归一化(normalization)
- DNS通道检测 国内学术界研究情况——研究方法:基于特征或者流量,使用机器学习决策树分类算法居多
- 机器学习归一化的几种方法
- 【机器学习】在工程上机器学习特征选择的方法
- 机器学习中的特征——特征选择的方法以及注意点
- 机器学习中的特征——特征选择的方法以及注意点
- 机器学习 —— 基础整理(四)特征提取之线性方法:主成分分析PCA、独立成分分析ICA、线性判别分析LDA
- 不会做特征工程的 AI 研究员不是好数据科学家!上篇 - 连续数据的处理方法 本文作者:s5248 编辑:杨晓凡 2018-01-19 11:32 导语:即便现代机器学习模型已经很先进了,也别
- 机器学习中常见的几种归一化方法以及原因
- 【方法】机器学习中的数据清洗与特征处理
- 机器学习中的特征——特征选择的方法以及注意点
- 机器学习-数据归一化方法
- 机器学习中的特征——特征选择的方法以及注意点
- 机器学习-数据归一化方法