Scrayp-通过scrapyd部署爬虫
2018-01-20 22:41
405 查看
前言
爬虫写完了,很多时候本机部署就可以了,但是总有需要部署到服务器的,网上的文章也比较多,复制的也比较多,从下午3点钟摸索到晚上22点,这里记录一下。环境情况
我的系统是Deepin开发环境也是Deepin,python path用的是Anaconda建立的虚拟环境(python3.6)
部署系统是本机的Deepin
部署环境由于在本机部署,所以跟开发环境一致(就是这里有个坑)
用到的服务是scrapyd
参考文章
网上对于scrapy部署的文章真是很多,一搜就很多页结果,但是我看很多都是复制粘贴,命令错了也没改。我的是综合多个文章来实际执行的,这里列一下我看过的文章:https://www.jianshu.com/p/694a56b2199a 【scrapyd部署scrapy项目】
https://www.jianshu.com/p/495a971233b5 【scrapyd+supervisor在ubuntu部署scrapy项目】
https://www.jianshu.com/p/f0077adb74bb 【使用Scrapyd部署爬虫】
/detail/2726485705.html 【搭建分布式架构爬取知乎用户信息】
介绍
Scrapyd是scrapinghub官方提供的爬虫管理、部署、监控的方案,文档传送安装scrapyd
对于它的安装,网上的说法层出不穷,有可能是老版本吧?我的安装很简单,在本机虚拟环境中 pip isntall scrapyd,就完成了
没有安装scrapyd-client也没有安装scrapyd-deploy,就是这么简简单单。
使用
它的使用有3个步骤1、为了检查是否安装正确,在电脑任意一个地方打开终端,输入scrapyd,如果没有报错,请打开 http://localhost:6800 ,看到如下画面则代表服务启动成功,看到启动成功后就可以关闭了。
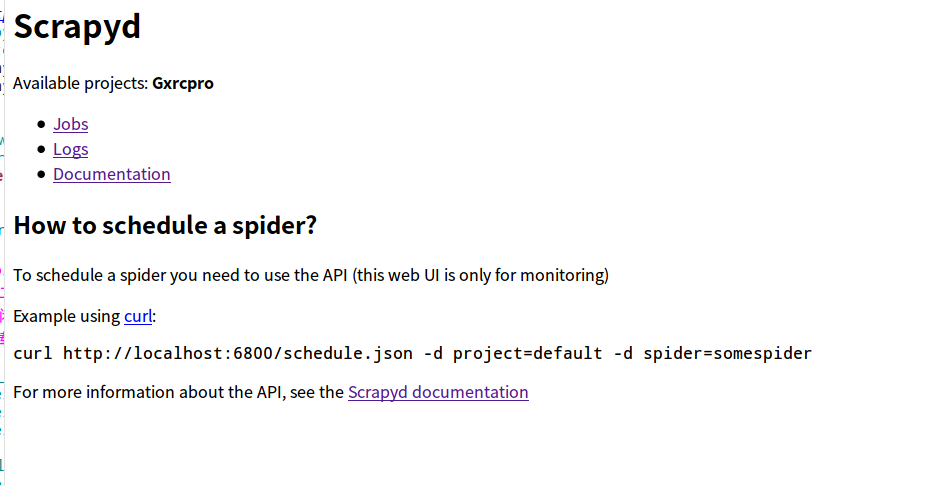
2、到scrapy工程目录内打开的scrapy.cfg文件,将原代码改为:
[settings] default = future.settings [deploy] url = http://localhost:6800/ project = Gxrcpro
保存即可
如果是在服务器上面部署,除了改bind端口为0.0.0.0外
bind端口更改地址:
anaconda3/envs/pspiders/lib/python3.6/site-packages/scrapyd
里面有个名为default_scrapyd.conf的文件,其中有一个设置是:
bind_address = 127.0.0.1
要将它改为 0.0.0.0
还需要
[settings] default = future.settings [deploy] url = http://0.0.0.0:6800/ project = Gxrcpro
设置成0.0.0.0,否则会提示name or service not known
3、由于之前在本地随意目录下打开scrapyd,导致爬虫启动失败,后来经过群友[wally小馒头]的帮助才知道失败是因为虚拟环境的问题,这次需要用到pycharm。
在pycharm里面打开teminal,然后输入命令scrapyd
接着看到服务启动,通过teminal左上角的绿色+号打开新的teminal窗口,在窗口输入命令:
scrapyd-deploy -p Gxrcpro
这里的Gxrc和Gxrcpro跟上面的cfg文件设置有关
如果收到一下信息就代表这次命令成功执行:
Packing version 1516456705 Deploying to project "Gxrcpro" in http://localhost:6800/addversion.json Server response (200): {"node_name": "ranbo-PC", "status": "ok", "project": "Gxrcpro", "version": "1516456705", "spiders": 1}
接着执行启动爬虫的命令:
curl http://localhost:6800/schedule.json -d project=Gxrcpro -d spider=gxrc
这里的Gxrcpro跟上面的cfg文件设置有关,而gxrc是你写代码时候填写的爬虫名字
收到如下信息:
{"node_name": "ranbo-PC", "status": "ok", "jobid": "5a6c4016fdec11e7ad5800e070785d37"}则代表这次成功启动爬虫,可以通过localhost:6800/Jobs来查看爬虫运行基本情况。

通过log可以看到爬虫的信息,如果是正在跑数据,则应该可以在log里面看到爬出来的数据;如果是出错,则会看到报错信息(之前我的环境路径不对,就是能启动,但是报错,爬虫就停止了)


相关文章推荐
- Python在Windows系统下基于Scrapyd部署爬虫项目(本地部署)
- Scrapyd 项目爬虫部署
- python之Scrapyd部署爬虫项目(使用虚拟环境)
- 如何将项目部署到Scrapyd(可以通过scrapy1.5中文官方文档进行学习)
- 基于Scrapyd的爬虫部署
- Scrapyd部署爬虫
- 第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
- centos系统下通过scrapyd部署python的scrapy
- 使用Scrapyd部署爬虫
- Scrapyd部署项目爬虫
- Scrapyd爬虫部署服务
- 使用scrapyd部署scrapy爬虫引擎
- Scrapyd部署爬虫项目
- ubuntu下scrapyd部署爬虫项目
- scrapyd 部署爬虫项目
- scrapyd部署爬虫遇到的问题
- Mac通过Docker部署Gitlab实践
- scrapyd部署总结
- Ubuntu上通过nginx部署Django笔记
- 通过Feature部署Sharepoint 2013的EventReceiver