Python在Windows系统下基于Scrapyd部署爬虫项目(本地部署)
2018-03-22 18:26
621 查看
部署前准备
1.准备一个支持scrapy项目的虚拟环境,确保能正常运行scrapy爬虫,已经下载需要的各种包
2.进入虚拟环境后安装scrapyd,scrapyd-client这两个包,具体命令如下
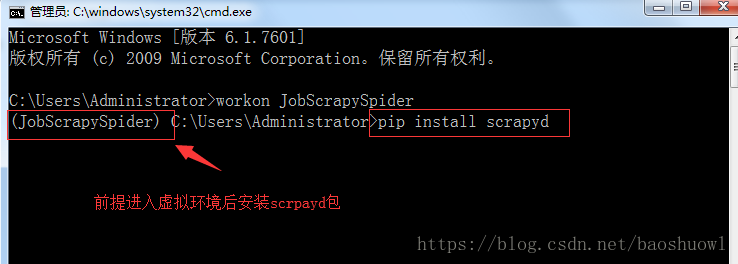

安装scrapyd,scrapyd-client包后,在虚拟环境下运行scrpayd命令
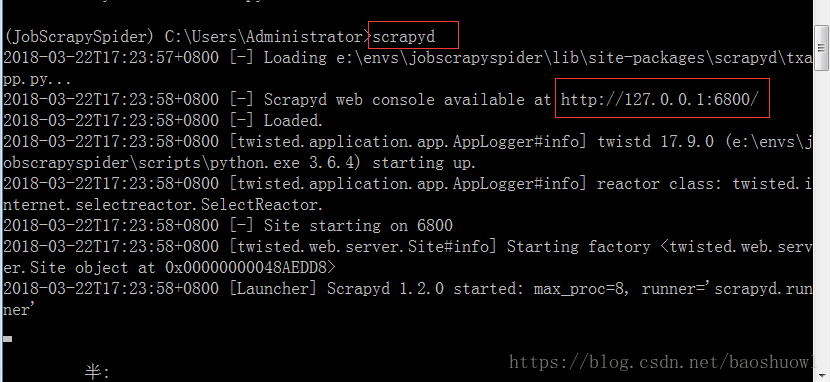
打开浏览器输入http://localhost:6800,如果显示以下页面则安装成功
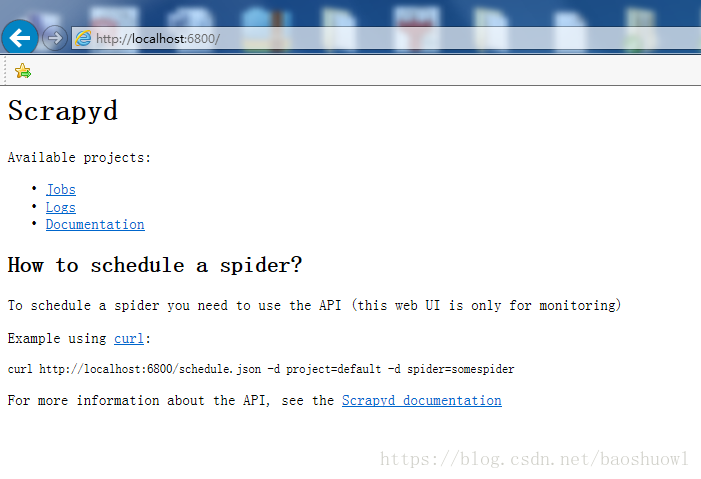
进行部署
3.在非C盘符下创建一个文件夹,名字为scrapyproject用来存放项目的子文件夹,创建后进入该文件夹shilt+鼠标右键选择打开命令行工具,输入scrapyd执行(前提必须进入虚拟环境才能执行),此时scrapyproject文件夹里会自动创建一个dbs文件夹,用来存放爬虫项目的数据文件,
因为安装了scrapyd-client包,所以在虚拟环境中的Scripts文件夹中会有一个scrapyd-deploy文件,因为此文件只能在linux中打开,所以要自己写一个windoes的bat文件

在scrapyd-deploy文件中写入以下代码
4000 @echo off "C:\Users\qianzhen\Envs\scrapySpider\Scripts\python.exe" "C:\Users\qianzhen\Envs\scrapySpider\Scripts\scrapyd-deploy" %1 %2 %3 %4 %5 %6 %7 %8 %9

标出的两个路径要设置为当前虚拟环境的路径
4.修改scrapy爬虫项目的scrapy.cfg文件

5.在虚拟环境的情况下在命令行中进入爬虫项目文件夹
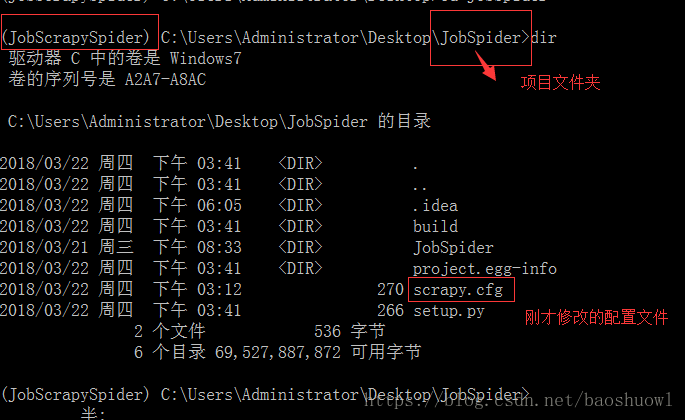
6.执行一下命令
1>scrapyd-deploy
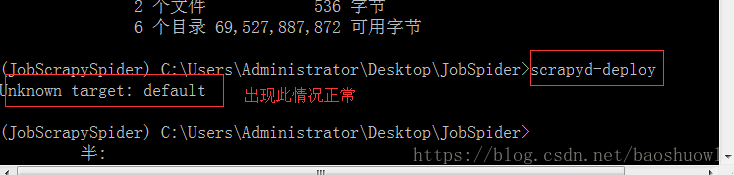
2>scrapyd-deploy -l
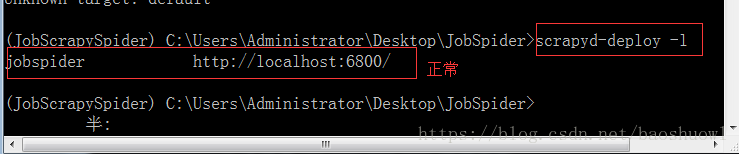
3>scrapy list
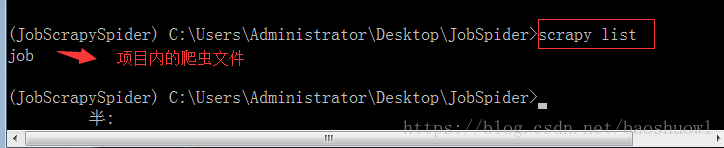
7.执行打包上传命令
scrapyd-deploy 项目名称(在scrapy.cfg中设置的) -p 爬虫项目名

8.继续打开http://localhost:6800,看看爬虫有没有部署成功
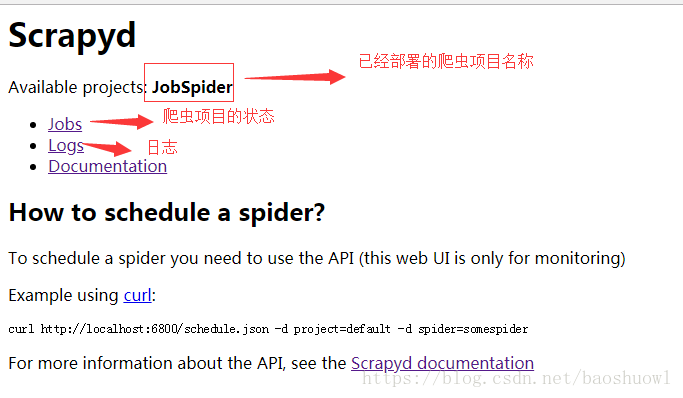
9.运行我们的爬虫
需要下载curl工具:
链接:https://pan.baidu.com/s/18B0ODhyhvmdVpQJlraZowQ 密码:pkwy
运行命令:
curl http://localhost:6800/schedule.json -d project=项目名称 -d spider=爬虫名称

返回http://localhost:6800,点击jobs查看
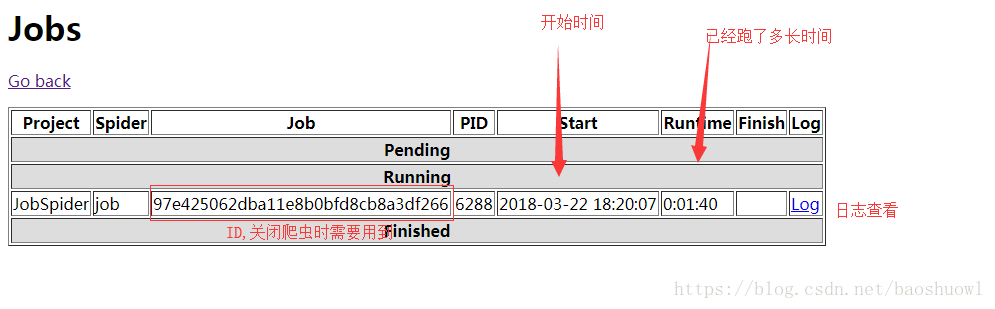
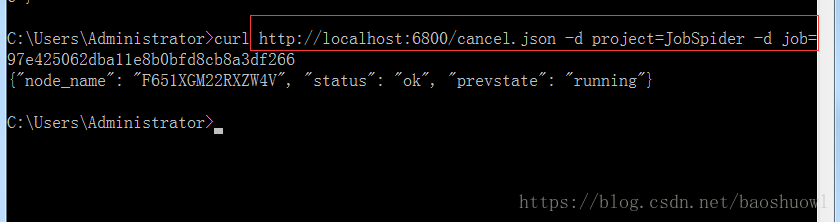
10.停止爬虫
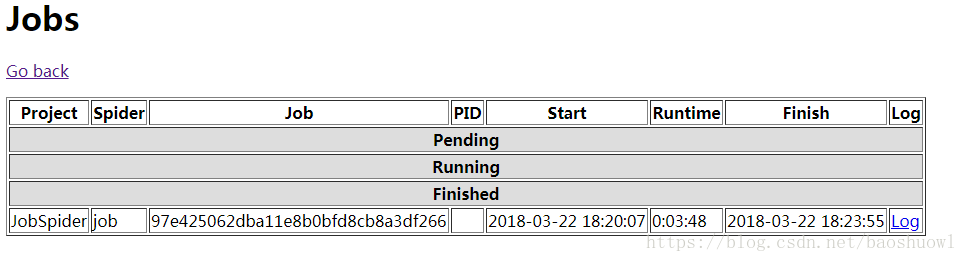
curl http://localhost:6800/cancel.json -d project=scrapy项目名称 -d job=运行ID
PS:其他一些命令
删除scrapy项目
curl http://localhost:6800/delproject.json -d project=scrapy项目名称(要先停止)
查看有多少个scrapy项目在api中
curl http://localhost:6800/listprojects.json 1、获取状态 http://127.0.0.1:6800/daemonstatus.json 2、获取项目列表 http://127.0.0.1:6800/listprojects.json 3、获取项目下已发布的爬虫列表 http://127.0.0.1:6800/listspiders.json?project=myproject 4、获取项目下已发布的爬虫版本列表 http://127.0.0.1:6800/listversions.json?project=myproject 5、获取爬虫运行状态 http://127.0.0.1:6800/listjobs.json?project=myproject 6、启动服务器上某一爬虫(必须是已发布到服务器的爬虫) http://127.0.0.1:6800/schedule.json (post方式,data={"project":myproject,"spider":myspider})
7、删除某一版本爬虫 http://127.0.0.1:6800/delversion.json (post方式,data={"project":myproject,"version":myversion})
8、删除某一工程,包括该工程下的各版本爬虫
http://127.0.0.1:6800/delproject.json(post方式,data={"project":myproject}) scrapyd部署爬虫的优势:
1、方便监控爬虫的实时运行状态,也可以通过接口调用开发自己的监控爬虫的页面
2、方便统一管理,可以同时启动或关闭多个爬虫
3、拥有版本控制,如果爬虫出现了不可逆的错误,可以通过接口恢复到之前的任意版本

相关文章推荐
- 第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
- python之Scrapyd部署爬虫项目(使用虚拟环境)
- Scrapyd部署爬虫项目
- Scrapyd 项目爬虫部署
- Python基于Flask框架配置依赖包信息的项目迁移部署
- Python之Fabric模块 Fabric是基于Python实现的SSH命令行工具,简化了SSH的应用程序部署及系统管理任务,它提供了系统基础的操作组件,可以实现本地或远程shell命令,包括:
- Python基于Flask框架配置依赖包信息的项目迁移部署小技巧
- 开源you-get项目爬虫,以及基于python+selenium的自动测试利器
- 基于Scrapyd的爬虫部署
- ubuntu下scrapyd部署爬虫项目
- 部署在本地的项目实现公网访问--基于Localtunnel实现内网穿透
- Scrapyd部署项目爬虫
- 基于Python的爬虫项目一——城市天气
- scrapyd 部署爬虫项目
- 基于Python的网络爬虫入门
- 把ASP.NET MVC项目部署到本地IIS上的完整步骤
- websphere上部署基于cxf框架的webservice项目报错问题的解决方案
- 跨过Nginx上基于uWSGI部署Django项目的坑
- [Python实战项目] - xpath 爬虫实战,获取纵横小说网连载小说最新章节(一)
- 基于Jenkins 实现php项目的自动化测试、自动打包和自动部署