Mac OS X 上搭建 Hadoop 开发环境指南
2018-01-20 10:52
232 查看
Hadoop 的配置有些麻烦,目前没有一键配置的功能,虽然当时我在安装过程中也参考了有关教程,但还是遇到了很多坑,一些老版本的安装过程已不适用于 hadoop2.x,下面就介绍一下具体步骤。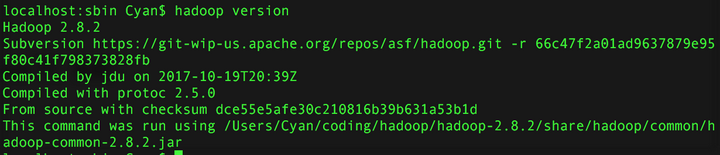 添加好了环境变量,下面就是修改一些相关配置文件。
添加好了环境变量,下面就是修改一些相关配置文件。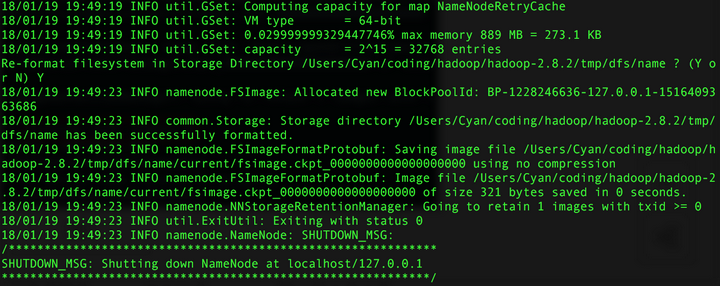 2. 启动 HDFS在终端首先进入 /sbin 目录:
2. 启动 HDFS在终端首先进入 /sbin 目录: 勾选 Remote Login(远程登录),然后添加当前用户:
勾选 Remote Login(远程登录),然后添加当前用户: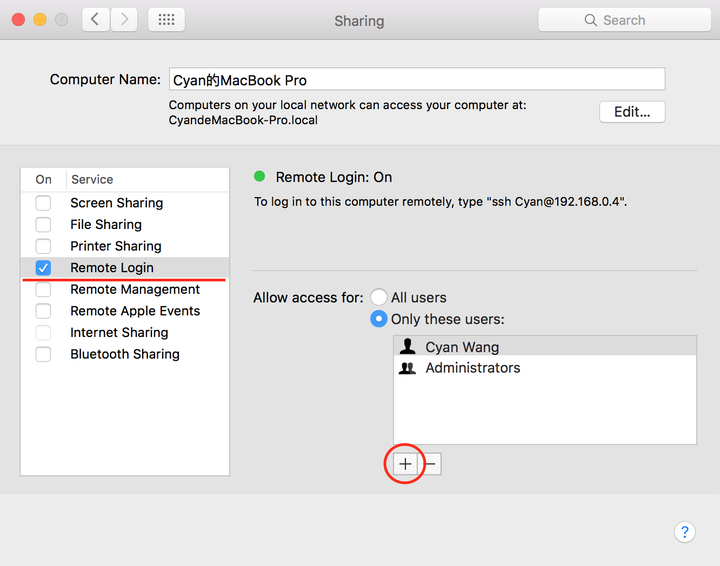 这样就会解决 connection 的问题,如果还有其他错误,请检查路径添加的版本和本机的版本是否匹配。3. 启动 yarn在终端首先进入 /sbin 目录:
这样就会解决 connection 的问题,如果还有其他错误,请检查路径添加的版本和本机的版本是否匹配。3. 启动 yarn在终端首先进入 /sbin 目录: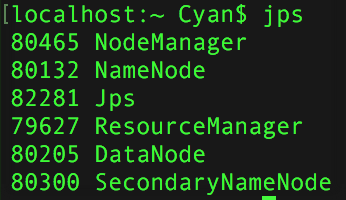 我们也可以在浏览器中打开 http://localhost:50070/ 来查看Hadoop 的启动情况:
我们也可以在浏览器中打开 http://localhost:50070/ 来查看Hadoop 的启动情况: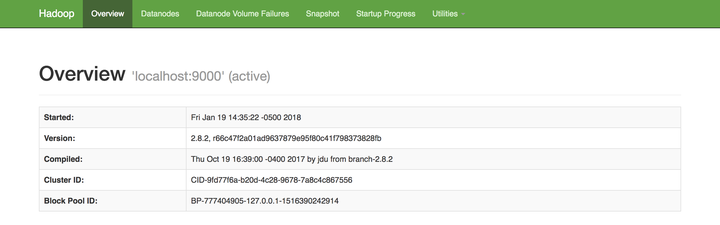 Hadoop 的安装启动就完成啦!接下来就可以通过一些 shell 命令来操作 Hadoop 下的文件了,例如:
Hadoop 的安装启动就完成啦!接下来就可以通过一些 shell 命令来操作 Hadoop 下的文件了,例如:
安装 Java
因为之后使用 Hadoop 需要运行 jar 包,所以 Java 环境是必须的,这里不作赘述,相信大多数学习 Hadoop 的小伙伴计算机上都早已经搭好 Java 环境。下载 Hadoop 源码
点击 这里 ,有所有的历史版本。本教程以 hadoop-2.8.2 为例,下载 hadoop-2.8.2.tar.gz即可。下载完成后,解压到本地合适的目录下。添加 Hadoop 环境变量
在 .bash_profile 文件中配置 Hadoop 的环境变量,使用 vim 打开该文件,在终端运行如下命令打开文件:vim ~/.bash_profile进入编辑模式后添加以下两行代码(修改成自己机子上的路径):
export HADOOP_HOME=/Users/Cyan/coding/hadoop/hadoop-2.8.2 export PATH=$PATH:$HADOOP_HOME/bin退出编辑模式,使用 :wq 保存修改,然后运行 source 命令使文件中的修改立即生效:
#source ~/.bash_profile在终端执行命令:
hadoop version结果如下,说明 hadoop 路径配置好了:
添加好了环境变量,下面就是修改一些相关配置文件。修改 Hadoop 的配置文件
需要修改的 Hadoop 配置文件都在目录 etc/hadoop 下,包括:hadoop-env.shcore-site.xmlhdfs-site.xmlmapred-site.xmlyarn-site.xml下面我们逐步进行配置:1. 修改 hadoop-env.sh 文件直接设置 JAVA_HOME 的路径,不要用$JAVA_HOME 代替,因为 Hadoop 对系统变量的支持不是很好。修改下面两个路径(用你机子上的 JAVA 路径和 Hadoop 目录的路径代替):export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_151.jdk/Contents/Home export HADOOP_CONF_DIR=/Users/Cyan/coding/hadoop/hadoop-2.8.2/etc/hadoop2. 修改 core-site.xml 文件设置 Hadoop 的临时目录和文件系统,localhost:9000 表示本地主机。如果使用远程主机,要用相应的 IP 地址来代替,填写远程主机的域名,则需要到 /etc/hosts 文件中做 DNS 映射。在 core-site.xml 文件里作如下配置:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> <!--用来指定hadoop运行时产生文件的存放目录 自己创建--> <property> <name>hadoop.tmp.dir</name> <value>/Users/Cyan/coding/hadoop/hadoop-2.8.2/tmp</value> </property> </configuration>3. 修改 hdfs-site.xml 文件hdfs-site.xml 的配置修改如下,注意 name 和 data 的路径都要替换成本地的路径:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <!--不是root用户也可以写文件到hdfs--> <property> <name>dfs.permissions</name> <value>false</value> <!--关闭防火墙--> </property> <!--把路径换成本地的name坐在位置--> <property> <name>dfs.namenode.name.dir</name> <value>/home/hadoop/cdh4/hadoop/dfs/name</value> </property> <!--在本地新建一个存放hadoop数据的文件夹,然后将路径在这 c74d 里配置一下--> <property> <name>dfs.datanode.data.dir</name> <value>/data1/hadoop</value> </property> </configuration>4. 修改 mapred-site.xml 文件由于根目录下 etc/hadoop 中没有 mapred-site.xml 文件,所以需要创建该文件。但是目录中提供了 mapred-site.xml.template 模版文件。我们将其重命名为 mapred-site.xml,然后将 yarn 设置成数据处理框架:
<configuration> <property> <!--指定mapreduce运行在yarn上--> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration5. 修改 yarn-site.xml 文件配置数据的处理框架 yarn:
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>localhost:9000</value> </property> </configuration>至此需要修改和配置的文件都已经没有问题了。
启动 Hadoop
1. 启动 NameNode在终端运行命令:hadoop namenode -format结果如下就是成功了:
2. 启动 HDFS在终端首先进入 /sbin 目录:cd /Users/Cyan/coding/hadoop/hadoop-2.8.2/sbin然后启动 HDFS:
./start-dfs.sh如果成功了,过程中需要输三次密码。如果报错 “connection refused”,则需要在计算机系统设置中打开远程登录许可。点击 Sharing(共享):
勾选 Remote Login(远程登录),然后添加当前用户:这样就会解决 connection 的问题,如果还有其他错误,请检查路径添加的版本和本机的版本是否匹配。3. 启动 yarn在终端首先进入 /sbin 目录:cd /Users/Cyan/coding/hadoop/hadoop-2.8.2/sbin然后启动 yarn:
./ start-yarn.sh在终端执行:
jps结果如下,证明 Hadoop 可以成功启动:
我们也可以在浏览器中打开 http://localhost:50070/ 来查看Hadoop 的启动情况:Hadoop 的安装启动就完成啦!接下来就可以通过一些 shell 命令来操作 Hadoop 下的文件了,例如:hadoop fs -ls / 查看根目录下的文件及文件夹 hadoop fs -mkdir /test 在根目录下创建一个文件夹 testdata hadoop fs -rm /.../... 移除某个文件 hadoop fs -rmr /... 移除某个空的文件夹

相关文章推荐
- Mac OS X下搭建Android开发环境(包括SDK和NDK)
- Mac OS X 下Node.js开发环境的搭建
- 我在Mac OS X 操作系统上搭建Android开发环境的经历
- Golang (Go语言) Mac OS X下环境搭建 环境变量配置 开发工具配置 Sublime Text 2
- Mac OS X 下搭建Erlang开发环境
- Win7 上 iPhone开发环境搭建之一VMware上安装Mac OS X Server 10.6
- 搭建Mac OS X下cocos2d-x的Android开发环境
- Mac环境下搭建Hadoop开发框架
- iOS开发39-Mac OS X下搭建XAMPP环境
- Mac OS X & Linux下搭建Nrf51822开发环境与编译过程
- Mac OS X上IntelliJ IDEA 13与Tomcat 8的Java Web开发环境搭建
- MAC OS X Android开发环境搭建
- Mac OS + IntelliJ Idea +Git 开发环境搭建实战
- 在Mac OS X上安装VirtualBox 和 Vagrant搭建Java web本地开发环境
- 【Lua】撸啊!第一弹:Lua开发环境搭建(Mac OS X)
- 如何在Mac OS X下搭建Android开发环境
- 搭建emacs下的rails开发环境(MAC OS X)
- Mac OS X 10.6下搭建J2ME及Subclipse开发环境全过程
- hadoop 自学指南二之开发环境搭建
- Mac OS X 10.9下搭建java web开发环境之一 开启和配置本机的Apache服务