异常检测与推荐系统 机器学习基础(8)
2016-03-01 14:51
495 查看
异常检测
异常检测被广泛应用于欺诈检测(例如信用卡被偷事件)。给定大量数据,指出与均值有巨大差异的点。例如,在制造业中检测缺陷与异常。高斯分布对数据建模往往会很有用。本模块涉及“推荐系统”(Amazon, Netflix, Apple 等公司用它来向用户推荐产品)。推荐系统(Recommender systems)寻找用户与产品间的交互模式从而生成推荐建议。该课程介绍了推荐算法,例如协同过滤算法与低秩矩阵分解。
密度估计
问题动机
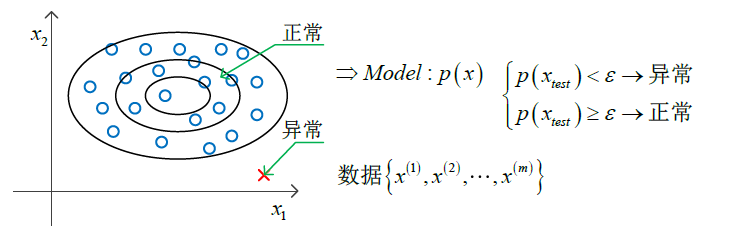
异常检测的案例:(欺诈/不正常行为)
特征 x(i)
于数据中建立模型 p(x)
定义异常值,根据 p(x)<ε
当然,参数 ε 是决定异常的关键。
高斯分布
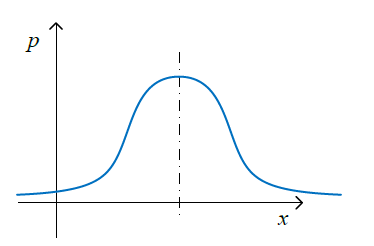
x∼N(μ,σ2)=12π−−√σe(−(x−μ)22σ2)p(x;μ,σ2)μ=1m∑i=1mx(i),σ2=1m∑i=1m(x(i)−μ)2
算法
1 密度估计
类似《数理统计》中的极大似然估计方法。p(x)=p(x1;μ1,σ21)p(x2;μ2,σ22)⋯p(xn;μn,σ2n)=∏i=1np(xi;μi,σ2i)x∈Rn;x1∼N(μ1,σ21),⋯,xn∼N(μn,σ2n)
2 算法流程
选择能作为指出异常例子的特征 xi参数估计 μi,σ2i
μi=1m∑j=1mx(j)i,σ2i=1m∑j=1m(x(j)i−μi)2
给定新的例子 x,计算 p(x)
p(x)=∏j=1np(xj;μj,σ2j)=∏j=1n12π−−√σje⎛⎝−(xj−μj)22σ2j⎞⎠
p(x)<ε,则为异常。
构建异常检测系统
值得注意的事,异常检测并不是一种监督学习方法。开发与评估异常检测系统
估计异常检测系统最直接且有效的方法是采用数值评估的方法。数据集将被分为训练集、验证集与预测集:60%, 20%, 20%。其中我们训练集是无异常的,记作 x(i),验证集与预测集包含标签(是否异常),记作 (x(i)CV,y(i)CV) 与 (x(i)test,y(i)test)。
例如:10000正常,20异常(异常的数量一般很少)
训练集:6000正常
验证集:2000正常,10异常
预测集:2000正常,10异常
1 算法评估
算法可调整的参数有特征与阈值 ε,用于改善系统性能,其改善的方法遵循迭代的规则:xtrain−→−p(x)xCV参数: 特征,ε值反复评估,迭代至最好的 p(x)−→−−−−best p(x)xtest→结果
评估指标
预测准确率
召回率/查准率
F1 值
异常检测 vs. 监督学习
在异常检测系统设计中,给定的数据是存在标签的(正常:异常?1:0),那么,这是不是意味着异常检测等同于监督学习呢?

特征选择
特征选择是为了希望异常值检测更加准确。特征的分布近似为高斯分布,更有利于算法。我们通过数值运算将原有的特征分布由非高斯分布逼近于高斯分布。
增加一些有效的特征,有利于异常检测,方法包含增加新特征、从原有特征衍生的特征。
多元高斯分布
多元高斯分布能检测到更多有利于异常检测的信息。多元高斯分布
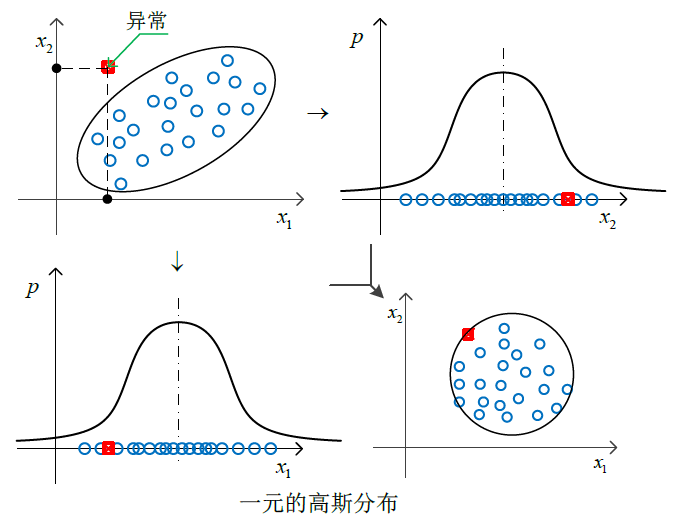
有时候,一元的高斯分布去除了特征间的关联性,会导致异常值也属于正常范围内,而多元高斯分布很好的保留了各个特征两两间的关联性,这里,我们用协方差来表示2个变量间的独立性,即关联程度,可称之为相关系数。
变量: x∈Rn,p(x)
参数: μ∈Rn,Σ∈Rn×n
模型:
p(x;μ,Σ)=12π−−√|Σ|12e(−12(x−μ)TΣ−1(x−μ))
其中,|Σ| 为协方差矩阵 Σ 的行列式值。
使用多元高斯分布的异常检测
多元高斯分布与一元高斯分布的区别在于参数 μ 与 Σ 的估计方法。μ=1m∑mi=1x(i),Σ=1m∑mi=1(x(i)−μ)(x(i)−μ)T
我们可以发现,当协方差矩阵 Σ 为对角矩阵的时候,多元高斯分布又变成了一元高斯分布,其中对角线上的值为各个特征的方程 σ2i。
下面,我们对一元高斯分布于多元高斯分布做一个简单的对比,

推荐系统
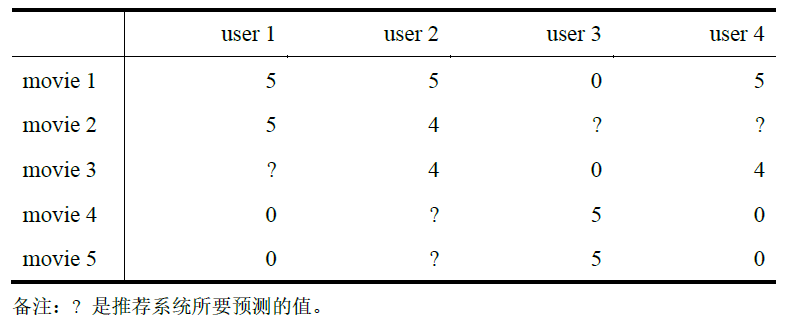
本模块涉及的知识包含协同过滤算法与低秩矩阵分解。预测电影评分
问题制定
预测电影评分的问题有如下定义:nu 为用户数;
nm 为电影数;
r(i,j)=1,即用户 j 对电影 i 评分过;
y(i,j),当 r(i,j)=1 时,用户 j 对电影 i 的评分。
基于内容的推荐
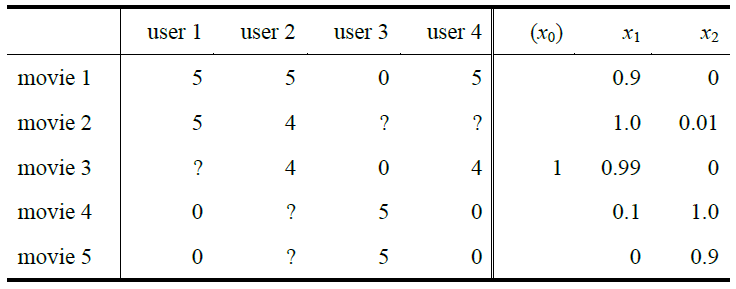
问题的描述:
参数
x(i) :电影 i 的特征向量;
θ(j) :用户 j 的参数向量, ;
n :特征 (x1,x2,…,xn) 的数量;
m(j) :用户 j 评分过的电影数;
(θ(j))T(x(i)) :用户 j 对电影 i 的评分。
目标方程(类似最小二乘问题)
子目标: θ(i)
minθ(j) 12m(j)∑i:r(i,j)=1((θ(j))T(x(i))−y(i,j))2+λ2m(j)∑k=1n(θ(j)k)2
优化目标: θ(1),⋯,θ(nu)
minθ(1),⋯,θ(nu)12∑j=1nu∑i:r(i,j)=1((θ(j))T(x(i))−y(i,j))2+λ2∑j=1nu∑k=1n(θ(j)k)2
梯度:
⎧⎩⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪∂∂θ(j)kJ=∑i:r(i,j)=1((θ(j))T(x(i))−y(i,j))x(i)k,k=0∂∂θ(j)kJ=∑i:r(i,j)=1((θ(j))T(x(i))−y(i,j))x(i)k+λθ(j)k,k≠0
值得注意的事,电影数量与用户数量决定了优化的搜索空间;另外,基于内容的推荐系统,特征值的提取,需要了解电影的成分(即爱情、动作等成分)。
协同过滤
协同过滤
协同过滤的实质是自行学习所要使用的特征,即 x(i) 是未知的,需要通过算法求解。有一个巧妙的思路是已知 θ(j) 去学习 x(i) ,即定义如下目标方程:子目标:x(i)
minx(i)12∑j:r(i,j)=1((θ(j))T(x(i))−y(i,j))2+λ2∑k=1n(x(i)k)2
优化目标: x(1),⋯,x(nm)
minx(1),⋯,x(nm)12∑i=1nm∑j:r(i,j)=1((θ(j))T(x(i))−y(i,j))2+λ2∑i=1nm∑k=1n(x(i)k)2
值得注意的是,这里的参数 θ(j) 给定的。
1 简单的协同过滤算法
给定 x(1),⋯,x(nm),估计 θ(1),⋯,θ(nu);给定 θ(1),⋯,θ(nu),估计 x(1),⋯,x(nm);
基本的协同过滤算法:
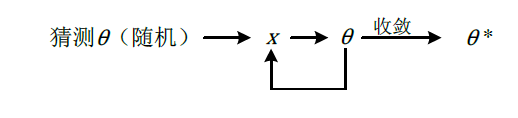
协同过滤算法
协同过滤算法并不是 x 与 θ 分开计算的迭代过程,而是以 x 与 θ 为学习参数的迭代过程。优化算法的目标为
minx(1),⋯,x(nm)θ(1),⋯,θ(nu)J(x(1),⋯,x(nm),θ(1),⋯,θ(nu))
其中,x∈Rn,θ∈Rn,此处 x 中不包含 x0 。值得注意的事,该优化问题的维度是 nm×n+nu×n 。
这里的代价函数 J 为
J(x(1),⋯,x(nm),θ(1),⋯,θ(nu))=12∑(i,j):r(i,j)=1+λ2∑i=1nm∑k=1n(x(i)k)2+λ2∑j=1nu∑k=1n(x(j)k)2((θ(j))T(x(i))−y(i,j))2
1 协同过滤的算法
x(1),⋯,x(nm),θ(1),⋯,θ(nu) 随机初始化优化算法求解 minJ 得到 x(1),⋯,x(nm),θ(1),⋯,θ(nu)
预测用户 j 对电影 i 的评分 (θ(j))T(x(i))
低秩矩阵分解
矢量化:低秩矩阵分解
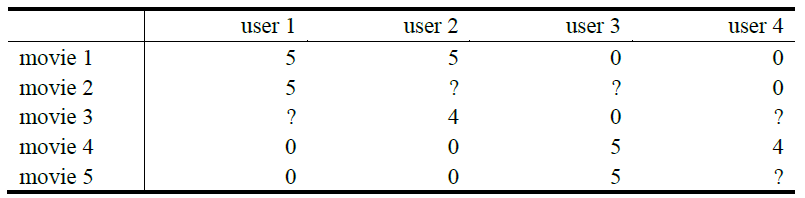
⇒Y=⎡⎣⎢⎢⎢⎢⎢⎢55?005?4000?05500?4?⎤⎦⎥⎥⎥⎥⎥⎥−→−−−−−−−−−−−orY(i,j)=(x(i))Tθ(j)Y(i,j)=(θ(j))Tx(i)⎡⎣⎢⎢⎢⎢⎢⎢⎢(θ(1))Tx(1)(θ(1))Tx(2)⋮(θ(1))Tx(nm)(θ(2))Tx(1)(θ(2))Tx(2)⋮(θ(2))Tx(nm)⋯⋯⋱⋯(θ(nu))Tx(1)(θ(nu))Tx(2)⋮(θ(nu))Tx(nm)⎤⎦⎥⎥⎥⎥⎥⎥⎥
矢量化的表达方式为 Y=XΘT
X = ⎡⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢−(x(1))T−−(x(2))T−⋮−(x(nm))T−⎤⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥,Θ=⎡⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢−(θ(1))T−−(θ(2))T−⋮−(θ(nu))T−⎤⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥
1 寻找相似的电影
电影 i,其特征 x(i)∈Rn,寻找相似的电影 j,其 x(j) 满足∥∥x(i)−x(j)∥∥→small
即电影 j 是相似于电影 i 的。
实施细节:均值归一化
Y=⎡⎣⎢⎢⎢⎢⎢⎢55?005?4000?05500?40?????⎤⎦⎥⎥⎥⎥⎥⎥⇒μ=⎡⎣⎢⎢⎢⎢⎢⎢2.52.522.251.25⎤⎦⎥⎥⎥⎥⎥⎥−→−−−−Y′=Y−μ⎡⎣⎢⎢⎢⎢⎢⎢2.52.5?−2.25−1.252.5?2−2.25−1.25−2.5?−22.753.75−2.5−2.5?1.75−1.25?????⎤⎦⎥⎥⎥⎥⎥⎥对于未对任何电影做过评分的用户,均值归一化的预处理方法会非常的有效(但不等同有理)。而均值归一化之后的评分的计算方法为 (θ(j))Tx(i)+μi。
相关检索
欺诈检测:http://code.csdn.net/news/2824689
推荐系统:http://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy2/
协同过滤算法:http://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy2/
极大似然估计:http://blog.csdn.net/bingduanlbd/article/details/24384771
均值归一化:http://blog.csdn.net/acdreamers/article/details/44664205

相关文章推荐
- 用Python从零实现贝叶斯分类器的机器学习的教程
- My Machine Learning
- 机器学习---学习首页 3ff0
- mahout基于用户推荐的简单例子(2)
- 反向传播(Backpropagation)算法的数学原理
- 也谈 机器学习到底有没有用 ?
- mahout+eclipse推荐系统开发学习之helloworld
- 如何用70行代码实现深度神经网络算法
- 不到100行代码实现一个简单的推荐系统
- 量子计算机编程原理简介 和 机器学习
- 近200篇机器学习&深度学习资料分享(含各种文档,视频,源码等)
- 已经证实提高机器学习模型准确率的八大方法
- 初识机器学习算法有哪些?
- 机器学习相关的库和工具
- 10个关于人工智能和机器学习的有趣开源项目
- 机器学习实践中应避免的7种常见错误
- 机器学习书单
- 北美常用的机器学习/自然语言处理/语音处理经典书籍
- 如何提升COBOL系统代码分析效率
- 基于内容的推荐Content-based Recommendation