降维-主成分分析
2018-01-10 08:48
225 查看
一、降维动机:
1.1、数据压缩:占内存小,可加快学习算法
下面举个小例子:
将数据从二维降至一维: 假使我们要采用两种不同的仪器来测量一些东西的尺寸,其中一个仪器测量结果的单位是英寸,另一个仪器测量的结果是厘米,我们希望将测量的结果作为我们机器学习的特征。现在的问题的是,两种仪器对同一个东西测量的结果不完全相等(由于误差、精度等),而将两者都作为 特征有些重复,因而,我们希望将这个二维的数据降至一维。
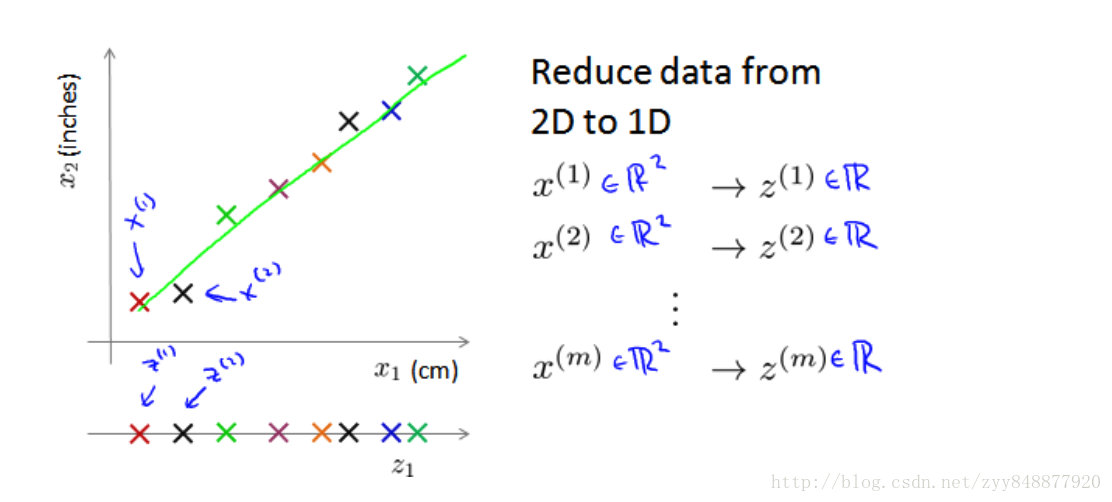
即想找一条直线,将数据投影到这条直线上。 如上例,原样本x(1)∈ℝ2,现变为z(1)∈ℝ1
将数据从三维降至二维: 这个例子中我们要将一个三维的特征向量降至一个二维的特征向量。过程是与上面类似的,我们将三维向量投射到一个二维的平面上,强迫使得所有的数据都在同一个平面上,降至二维的特征向量。
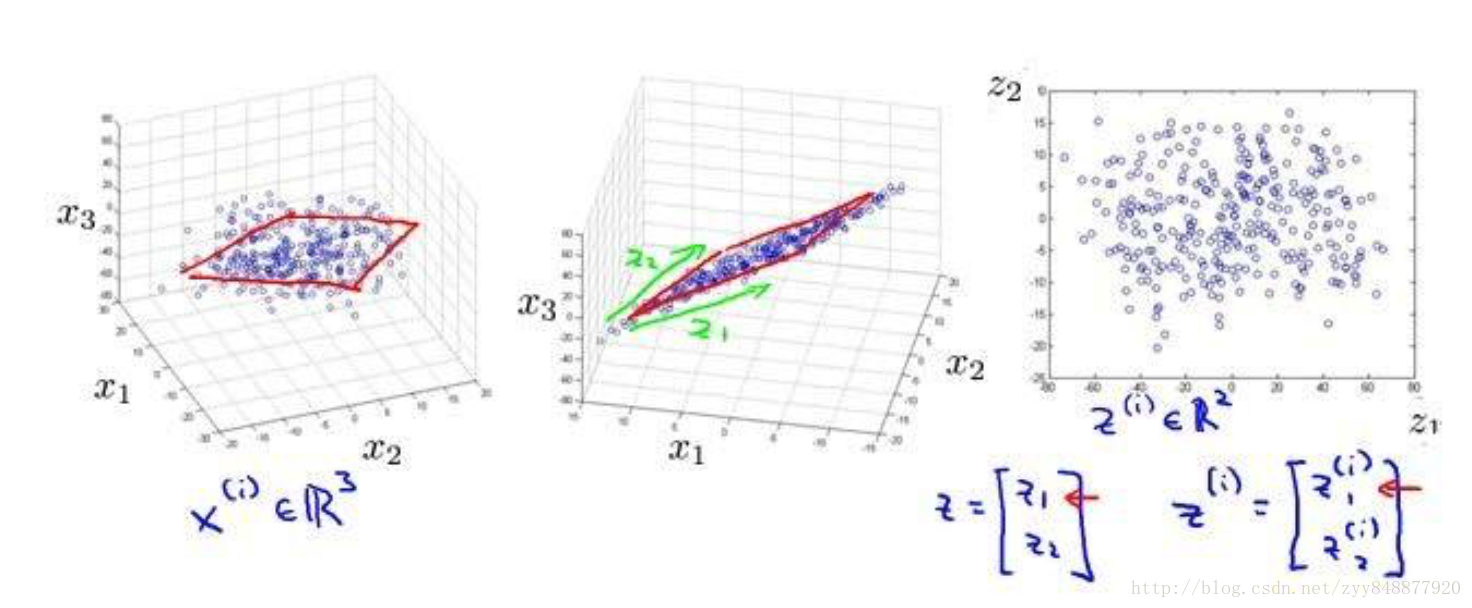
即想找一个平面,将数据投影到这个平面上。 如上例,原样本x(1)∈ℝ3,现变为z(1)∈ℝ2
1.2、数据可视化
降维的算法只负责减少维数,新产生的特征的意义就必须由我们自己去发现了 。
1.3、使得数据集更易使用;降低很多算法的计算开销;去除噪声;使得结果易懂。
二、常用的方法
2.1、主成分分析(PCA)
主成分分析是最常用的线性降维方法,它的目标是通过某种线性投影,将高维的数据映射到低维的空间中表示,并期望在所投影的维度上数据的方差最大,以此使用较少的数据维度,同时保留住较多的原数据点的特性。
优点:
1、 降低数据的复杂性,识别最重要的多个特征。可以对新求出的“主元“向量的重要性进行排序,根据需要取前面最重要的部分,将后面的维数省去,可以达到降维从而简化模型或是对数据进行压缩的效果。同时最大程度的保持了原有数据的信息。
2、 完全是无参数限制的。在PCA的计算过程中完全不需要人为的设定参数或是根据任何经验模型对计算进行干预,最后的结果只与数据相关,与用户独立。
第2点 也可以看作是缺点。因为如果用户对观测对象有一定的先验知识,掌握了数据的一些特征,却无法通过参数化等方法对处理过程进行干预,可能会得不到预期的效果,效率也不高。
缺点:
不一定需要,且可能损失有用信息。
适用数据类型:
数值型数据。
目标:两种解释方法
1、基于最小投影距离
在PCA中,我们要做的是找到一个方向向量(Vector direction),当我们把所有的数据都投射到该向量上时,我们希望投射平均均方误差能尽可能地小。方向向量是一个经过原点的向量,而投射误差是从特征向量向该方向向量作垂线的长度。
2、基于最大投影方差
数据从原来坐标系转换到了新的坐标系,新坐标系的选择是原始数据决定的。
第一个新坐标轴选择的是原始数据中方差最大的方向;
第二个新坐标轴的选择和第一个坐标轴正交且具有最大方差的方向。该过程一直重复,重复次数为原始数据中特征的数目。
理论:移动坐标轴
在PCA中,我们对数据的坐标进行了旋转,该旋转的过程取决于数据本身。第一条坐标轴旋转到覆盖数据的最大方差位置,因为数据的最大方差给出了数据的最重要的信息。在选择了覆盖数据最大差异性的坐标轴之后,与第一条坐标轴垂直的那个方向就是覆盖数据次大差异性的坐标轴,也就是我们要选择的第二条坐标轴。
主成分分析算法:
第一步是均值标准化/归一化。我们需要计算出所有特征的均值,然后令 xj= xj -μj,使得每个特征都有一个恰当的零均值; 如果特征是在不同的数量级上,我们还需要将其除以标准差 σ2。
第二步是计算协方差矩阵(covariance matrix)Σ:
第三步是计算协方差矩阵 Σ 的特征向量(eigenvectors):
在Numpy中实现PCA
将数据转换成前N个主成分的伪码大致如下:
1、去除平均值
2、计算协方差矩阵
3、计算协方差矩阵的特征值和特征向量
4、将特征值从大到小排序
5、保留最上面的N个特征向量
6、将数据转换到上述N个特征向量构建的新空间中
PCA算法
补充:
1、s.strip()函数
声明: s为字符串,rm为要删除的字符序列
s.strip(rm): 删除s字符串中开头、结尾处,位于 rm删除序列的字符;
s.lstrip(rm): 删除s字符串中开头处,位于 rm删除序列的字符;
s.rstrip(rm): 删除s字符串中结尾处,位于 rm删除序列的字符;
当rm为空时,默认删除空白符(包括’\n’, ‘\r’, ‘\t’, ’ ‘)
2、map(): Python 内置的高阶函数
它接收一个函数 f 和一个 list,并通过把函数 f 依次作用在 list 的每个元素上,得到一个新的list 并返回。
1.1、数据压缩:占内存小,可加快学习算法
下面举个小例子:
将数据从二维降至一维: 假使我们要采用两种不同的仪器来测量一些东西的尺寸,其中一个仪器测量结果的单位是英寸,另一个仪器测量的结果是厘米,我们希望将测量的结果作为我们机器学习的特征。现在的问题的是,两种仪器对同一个东西测量的结果不完全相等(由于误差、精度等),而将两者都作为 特征有些重复,因而,我们希望将这个二维的数据降至一维。
即想找一条直线,将数据投影到这条直线上。 如上例,原样本x(1)∈ℝ2,现变为z(1)∈ℝ1
将数据从三维降至二维: 这个例子中我们要将一个三维的特征向量降至一个二维的特征向量。过程是与上面类似的,我们将三维向量投射到一个二维的平面上,强迫使得所有的数据都在同一个平面上,降至二维的特征向量。
即想找一个平面,将数据投影到这个平面上。 如上例,原样本x(1)∈ℝ3,现变为z(1)∈ℝ2
1.2、数据可视化
降维的算法只负责减少维数,新产生的特征的意义就必须由我们自己去发现了 。
1.3、使得数据集更易使用;降低很多算法的计算开销;去除噪声;使得结果易懂。
二、常用的方法
2.1、主成分分析(PCA)
主成分分析是最常用的线性降维方法,它的目标是通过某种线性投影,将高维的数据映射到低维的空间中表示,并期望在所投影的维度上数据的方差最大,以此使用较少的数据维度,同时保留住较多的原数据点的特性。
优点:
1、 降低数据的复杂性,识别最重要的多个特征。可以对新求出的“主元“向量的重要性进行排序,根据需要取前面最重要的部分,将后面的维数省去,可以达到降维从而简化模型或是对数据进行压缩的效果。同时最大程度的保持了原有数据的信息。
2、 完全是无参数限制的。在PCA的计算过程中完全不需要人为的设定参数或是根据任何经验模型对计算进行干预,最后的结果只与数据相关,与用户独立。
第2点 也可以看作是缺点。因为如果用户对观测对象有一定的先验知识,掌握了数据的一些特征,却无法通过参数化等方法对处理过程进行干预,可能会得不到预期的效果,效率也不高。
缺点:
不一定需要,且可能损失有用信息。
适用数据类型:
数值型数据。
目标:两种解释方法
1、基于最小投影距离
在PCA中,我们要做的是找到一个方向向量(Vector direction),当我们把所有的数据都投射到该向量上时,我们希望投射平均均方误差能尽可能地小。方向向量是一个经过原点的向量,而投射误差是从特征向量向该方向向量作垂线的长度。
2、基于最大投影方差
数据从原来坐标系转换到了新的坐标系,新坐标系的选择是原始数据决定的。
第一个新坐标轴选择的是原始数据中方差最大的方向;
第二个新坐标轴的选择和第一个坐标轴正交且具有最大方差的方向。该过程一直重复,重复次数为原始数据中特征的数目。
理论:移动坐标轴
在PCA中,我们对数据的坐标进行了旋转,该旋转的过程取决于数据本身。第一条坐标轴旋转到覆盖数据的最大方差位置,因为数据的最大方差给出了数据的最重要的信息。在选择了覆盖数据最大差异性的坐标轴之后,与第一条坐标轴垂直的那个方向就是覆盖数据次大差异性的坐标轴,也就是我们要选择的第二条坐标轴。
主成分分析算法:
第一步是均值标准化/归一化。我们需要计算出所有特征的均值,然后令 xj= xj -μj,使得每个特征都有一个恰当的零均值; 如果特征是在不同的数量级上,我们还需要将其除以标准差 σ2。
第二步是计算协方差矩阵(covariance matrix)Σ:
第三步是计算协方差矩阵 Σ 的特征向量(eigenvectors):
在Numpy中实现PCA
将数据转换成前N个主成分的伪码大致如下:
1、去除平均值
2、计算协方差矩阵
3、计算协方差矩阵的特征值和特征向量
4、将特征值从大到小排序
5、保留最上面的N个特征向量
6、将数据转换到上述N个特征向量构建的新空间中
PCA算法
def loadDataSet(fileName, delim='\t'): fr=open(fileName) stringArr=[line.strip().split(delim) for line in fr.readlines()] datArr=[map(float, line) for line in stringArr] #把每一行数据都变成float类型 return mat(datArr) #mat()是生成一个矩阵。 def pca(dataMat, topNfeat=9999999): meanVals=mean(dataMat, axis=0) #对列求平均值 meanRemoved=dataMat-meanVals covMat=cov(meanRemoved, rowvar=0) #得到协方矩阵 eigVals, eigVects= linalg.eig(mat(covMat)) eigValInd=argsort(eigVals) eigValInd = eigValInd[:-(topNfeat + 1):-1] # cut off unwanted dimensions redEigVects = eigVects[:, eigValInd] # reorganize eig vects largest to smallest lowDDataMat = meanRemoved * redEigVects # transform data into new dimensions reconMat = (lowDDataMat * redEigVects.T) + meanVals return lowDDataMat, reconMat
补充:
1、s.strip()函数
声明: s为字符串,rm为要删除的字符序列
s.strip(rm): 删除s字符串中开头、结尾处,位于 rm删除序列的字符;
s.lstrip(rm): 删除s字符串中开头处,位于 rm删除序列的字符;
s.rstrip(rm): 删除s字符串中结尾处,位于 rm删除序列的字符;
当rm为空时,默认删除空白符(包括’\n’, ‘\r’, ‘\t’, ’ ‘)
2、map(): Python 内置的高阶函数
它接收一个函数 f 和一个 list,并通过把函数 f 依次作用在 list 的每个元素上,得到一个新的list 并返回。

相关文章推荐
- 降维:主成分分析(PCA)
- 降维-主成分分析(PCA)
- python实现PCA(主成分分析)降维
- PCA(主成分分析)、主份重构、特征降维
- 数据挖掘学习------------------1-数据准备-4-主成分分析(PCA)降维和相关系数降维
- 深度学习中的降维操作——PCA(主成分分析)
- spark mllib 数据降维 主成分分析(PCA)
- 【机器学习算法-python实现】PCA 主成分分析、降维
- 主成分分析实战篇:南极考察站检测数据降维
- 【机器学习】数据降维—核主成分分析(Kernel PCA)
- 数据降维之主成分分析、多维缩放、t分布随机近邻嵌入、自编码神经网络
- 机器学习之降维算法2-主成分分析(PCA)
- 降维系列算法【主成分分析】
- 主成分分析降维(MNIST数据集)
- 数据降维技术——PCA(主成分分析)
- 降维--主成分分析(PCA)
- 【机器学习算法-python实现】PCA 主成分分析、降维
- 机器学习(七):主成分分析PCA降维_Python
- 利用 主成分分析(PCA) 降维 个人理解