结构化风险模型----转:沪深300指数的风格因子暴露度分析(一)
2018-01-04 14:56
267 查看
from: https://xueqiu.com/7381621247/73649418
1 概述
Barra 结构化风险模型是全球知名的投资组合表现和风险分析工具。最近一段时间,我们米筐科技量化策略研究团队对该模型进行了系统研究,并在米筐科技公司的策略研究平台上进行了实现。接下来一段时间,我们将以系列专题的形式展示我们的研究成果。在这一份报告里,我们将对
Barra 结构化模型作简单介绍,并对因子的构建及暴露度的计算进行探讨。为了对因子的有效性作简单的测试,我们对沪深
300 组合 从 2014 年 5 月到 2016 年 3 月共 23 期的因子暴露度进行了计算和分析。
2 均值-方差模型(Markowitz Mean-Variance Model)
1952 年,马柯维茨发表了《证券组合选择》,建立起现代投资组合理论的框架。马科维茨认为,投资者可以用预期收益率
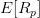
,以及收益率的标准差
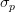
来完全构建和衡量一个投资组合,因此,该模型又称为均值-方差模型。依据他的观点,对于一个资产数目为
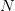
,且各资产头寸相同的投资组合,如果已知每一个资产收益率的方差
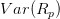
和资产两两之间的协方差
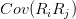
,则我们可以计算这个投资组合的方差:
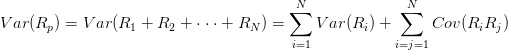
对于包含
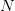
个资产的投资组合,我们需要计算
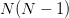
个协方差,通常以协方差矩阵来表示:
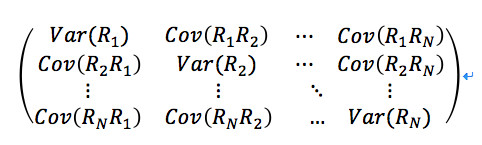
此时,资产的协方差矩阵包含了我们投资组合的一切风险信息。在实际计算中,我们需要通过历史数据来计算经验协方差矩阵
(empirical covariance matrix),作为协方差矩阵的估计。然而,使用经验协方差矩阵存在以下问题:
(1)数据量要求大。要对协方差矩阵实现较为准确的估计,需要保证观测值数目大于矩阵的维数。考虑以沪深
300 的 300 个成分股作为投资组合,以月度数据计算经验协方差矩阵,则需要至少
300/12 = 25 年的数据,因此缺乏现实可行性;
(2)依据历史数据进行协方差估计无法反映投资组合中资产的结构性变化(例如并购);
(3)大量资产两两之间的协方差计算,容易出现多重比较谬误(multiple
comparison fallacy)的问题,因而引起资产之间相关性的错误判断。
(4)历史数据中包含大量的噪音,因此简单使用资产的协方差矩阵进行预测会造成较大的偏差。
2 结构化风险模型 (Structural Risk Model, SRM)
针对以上用资产的协方差矩阵来衡量投资组合风险所存在的缺陷,国际著名的投资组合表现分析研究机构
MSCI Barra 使用结构化风险模型(也称多因子模型,以下简称
SRM)来衡量投资组合的表现和风险。其核心思想是,我们可以选取一系列公共因子(common
factors)和特异因子 (idiosyncratic
factors)来描述一个投资组合的风险。常用的公共因子有所属行业,成长性,市盈率等,特异因子则是和公共因子相对的概念,用于解释每个资产的收益率中不能用公共因子解释的部分。基于这个思路,投资组合的收益率
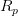
可以用资产的头寸
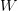
,因子暴露(factor
exposure)矩阵
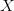
,因子收益率
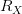
和特异因子(idiosyncratic
factors)收益率
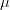
的线性组合来表示:
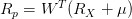
其中,因子暴露
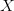
又称因子载荷(factor
loading),用于衡量因子对投资组合收益率的贡献。当因子为行业因子时,
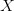
为取值只有
0 和 1 的哑变量(dummy variable),表示该资产是否属于该行业;当因子为市盈率等连续变量时,为减少回归建模中残差的异方差性,通常要进行剔除离群值和标准化的处理。
另外,SRM
给出了以下的两个假设:
(1)对于同一个资产

,因子收益率和特异收益率不存在线性相关,即
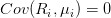
;
(2)对于两个不同的资产

和
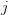
,它们的特异收益率也不存在线性相关,即
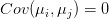
。基于这两个假设,我们可以推导出
SRM 的投资组合风险表达式:
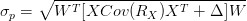
其中

为投资组合收益率的标准差,
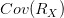
为因子收益率的协方差矩阵。
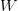
和
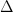
分别为权重向量和特异因子收益率方差矩阵。
上述两个表达式即为结构化风险模型的核心。虽然它们的形式上稍显复杂,但它们的意义是明确的:投资组合的风险可以用因子收益率的协方差矩阵,而非投资组合中资产的收益率的协方差矩阵来描述。从数据处理的角度来看,SRM是一种数据降维技术。因此,它具有数据降维通常的优点:
(1)去除数据中的噪音;
(2)它能够**减少计算量,因此也降低了出现多重比较谬误的可能性。例如,一个包含
500 个资产的投资组合,如果要构建其相关系数矩阵,则需要计算
500*(500-1)/2 = 124,750 个相关系数,如果选用 50 个因子的相关系数来描述,则只需要计算
50*(50-1)/2 = 1225 个相关系数;
(3)因子的统计量通常比资产的统计量有更好的稳定性,因此基于SRM能给出更精确的长期预测;
(4)因子暴露度的调整可以捕捉资产的结构性变化;
(5)因子本身有清晰的经济学涵义,在对
SRM 的因子进行筛选的过程中,也会加深我们对于投资组合风险来源的认识。
3 公共因子的选择
在一般的 SRM 实现中,因子被分为两大类:行业因子和风格因子。参照国家统计局的行业分类方法,我们选定了
19 个行业因子(表1),以取值为
0 或 1 的哑变量(dummy variable)表示。而风格因子则对应一些选择投资组合常见的主题和标准,包括9个类型:贝塔值(beta),动量(momentum),规模(size),盈利率(earnings
yield),波动率(volatility),成长性(growth),价值(value),杠杆(leverage)和流动性(liquidity)。因此在目前的建模中,我们一共使用28个因子。
4 风格因子的实现
行业因子的定义见表1。
表1:依据国家统计局的分类选定的行业因子
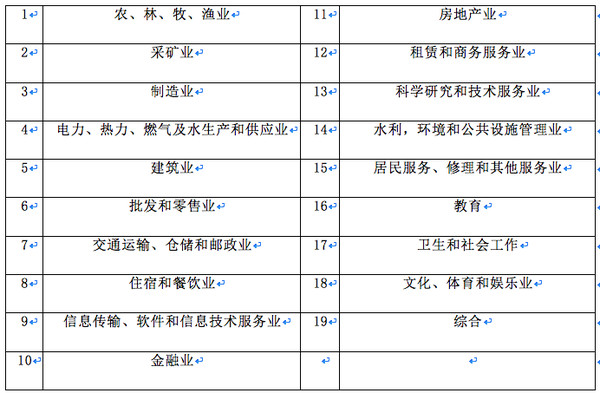
接下来我们将介绍如何构建风格因子。在部分风格因子的构建中,我们使用了多个细分因子(一些资料称其为
atom descriptors)来组成一个因子,以表征该因子不同的特征。例如,在盈利率因子的构建中,我们使用了市盈率,每股经营活动产生的现金流量净额和每股收益(扣除/稀释)三个描述变量。如果在线性回归模型中直接使用这些细分因子,因为它们所属的类型相同,因此可能会导致有多个细分因子所属的因子类型对模型参数估计的影响力过大,且容易引起共线性的问题。对此,我们把属于同一类型的多个因子进行加权组合得到该类型对应的暴露度。而因子的权重可通过对上一期数据进行随机森林(random
forest)回归分析获得。
另外我们需要对一些稳定性较差(自相关性较低)的因子(动量和波动率)进行指数加权处理,给予时间较近的交易日数据较大的权重。具体地,我们采用半衰期为30天的指数系数(
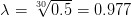
),此时在风险暴露度矩阵的估计中,近
30 个交易日的数据将会占一半的权重。我们在 200 个交易日处做截断(更早的交易日的权重非常小,已可忽略不计)。在下面的因子计算中,我们将会统一使用
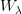
表示归一化指数权重向量。
最后,在风格因子的计算中,除了在
RiceQuant 策略研究平台上调用的变量外,我们还需要定义以下的衍生变量和运算:
衍生变量:

和
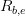
分别表示股票和基准组合的
200 个交易日的每日超额收益率时间序列;
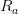
和

分别表示股票和基准组合中资产的
200 个交易日的每日收益率时间序列;

表示归一化指数权重;
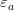
是贝塔值计算后得到的残差+截距项。outstanding_shares
表示流通股本,TotalVolumeTraded/outstanding_shares 计算得到的即我们通常说的换手率。
运算:

表示计算变量的协方差;
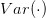
表示计算变量的方差;
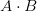
表示计算向量
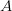
和向量
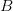
的内积;
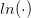
表示对变量取对数;
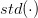
表示计算变量的标准差;

表示计算变量均值,
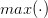
和

分别表示取一组数据中的最大值和最小值。
基于以上的讨论,我们的风格因子构建所需的变量见表2,具体计算见表3。
表2:RiceQuant 策略研究平台上调用的变量
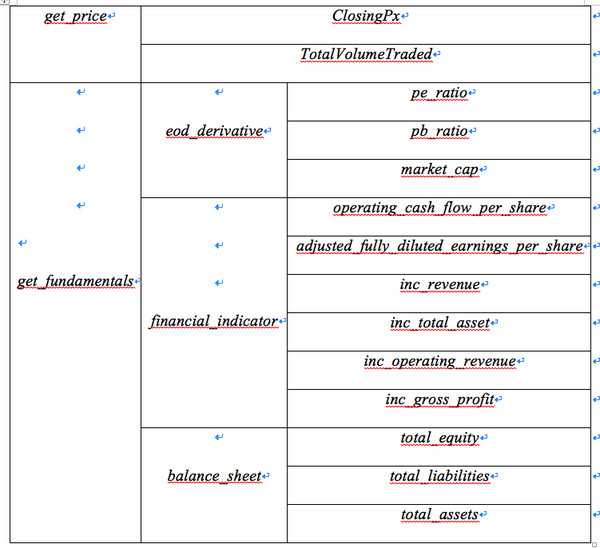
表3:风格因子的的定义和计算

5 沪深300的因子暴露度分析
接下来,我们将把沪深300指数和各个风格因子的变化趋势进行比较分析(图1和图2)。在这里,我们首先给出沪深300指数的基本计算公式:
报告期指数=报告期成份股的调整市值/基日成份股的调整市值×1000
其中基日为2004年12月31日。由于可以看出,沪深300指数主要决定于其成分股的市值。基于这个认识,我们对各个风格因子的变化进行分析。
5.1 规模因子,盈利率因子和价值因子
基于风格因子的定义,规模因子的暴露度是直接对市值取对数,而盈利率因子暴露度中的市盈率和市值成正比,因此这两个因子和沪深300的变化趋势基本一致(图1);而对于价值因子的暴露度,其和市值成反比,因此和沪深300的变化呈相反趋势(图2)。
5.2 贝塔值因子
贝塔值是衡量一个投资组合对基准组合的敏感性的指标。在这里,虽然我们使用的投资组合是沪深300的300个成分股,但贝塔值并不恒等于1。其原因在于,我们进行每一期因子暴露度计算时,都使用月底的成分股权重,和过去
200 个交易日沪深 300 指数成分股的权重稍有不同。在图 1 中,我们可以看到当指数出现大幅震荡时,贝塔值因子暴露度会明显偏离于
1,即依据每期月末的权重构建的沪深 300 成分股组合,和过去
200 个交易日的沪深 300 指数的敏感性显著提高或是降低(图1)。
5.3 动量因子
在动量因子的构建过程中,我们使用了
200 个交易日的加权平均值来展示个股的长期动量,对比沪深 300 指数的和动量因子的变化趋势,可以发现当市场出现大幅震荡时,这个因子暴露度的变化呈现出一定的滞后性。2015年下半年市场出现大幅下跌,但2016年2月动量才从正变为负(图1)。
5.4 波动率因子
波动率因子暴露度的走势和沪深300指数的走势基本一致,较好地反映了市场的波动情况(图1)。
5.5 成长性因子
成长性因子的构建使用了四个变量的同比增长率,和企业的股票市值并没有直接联系。有意思的是,沪深300的成长性因子暴露度出现三个峰值,这三个峰值均出现在市场波动较小的阶段,可能反映出在市场行情较为平淡时,投资者较为倾向于投资具有较好成长性的股票(图2)。
5.6 杠杆因子
杠杆因子的计算公式是:(负债合计+总资产)/总资产,和企业的股票市值没有直接联系,但其暴露度变化和沪深300指数的变化呈现相反的趋势。可能反映在牛市当中,杠杆低的企业的股票更受投资者青睐(图2)。
5.7 流动性因子
流动性因子的走势和沪深300指数的走势基本一致,较好地反映了市场的整体交易情况(图2)。
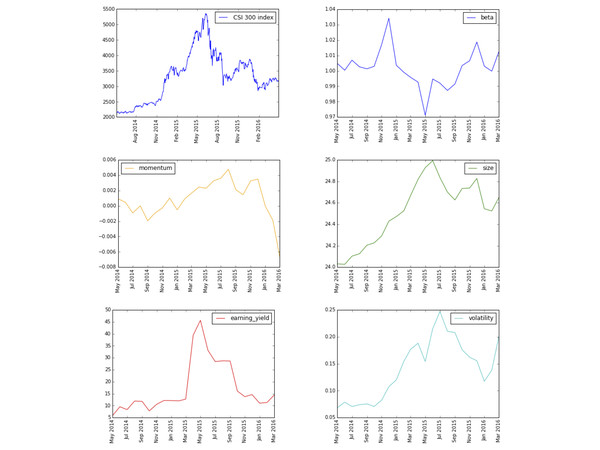
图1 沪深300指数变化和风格因子(贝塔值,动量,规模,盈利率和波动率)的对比
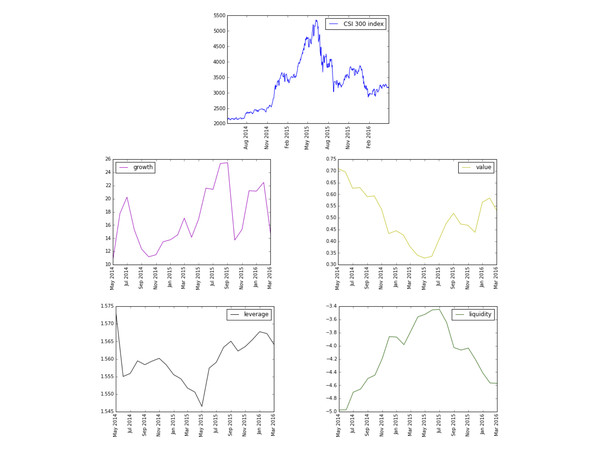
图2 沪深300指数变化和风格因子(成长性,价值,杠杆和流动性)的对比
6 总结
在这一份报告里,我们简要介绍了Barra
结构化风险模型,并对一系列风格因子进行了构建和分析。我们以沪深
300 成分股作为投资组合进行测试。测试结果表明,大部分因子均较好地反映了沪深
300 指数的变化特征,以及在不同的市场环境下投资者的一些投资倾向。在动量因子的分析中,我们发现因子只能反映市场的长期动量变化,而当市场出现大幅震荡的行情时,其变化出现了一定的滞后性。所以在下一步的建模中,我们将进一步添加表征短期和中期动量的细分因子,使其能够捕捉不同情况下的市场变化趋势
作者:Ricequant量化
链接:https://xueqiu.com/7381621247/73649418
来源:雪球
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1 概述
Barra 结构化风险模型是全球知名的投资组合表现和风险分析工具。最近一段时间,我们米筐科技量化策略研究团队对该模型进行了系统研究,并在米筐科技公司的策略研究平台上进行了实现。接下来一段时间,我们将以系列专题的形式展示我们的研究成果。在这一份报告里,我们将对
Barra 结构化模型作简单介绍,并对因子的构建及暴露度的计算进行探讨。为了对因子的有效性作简单的测试,我们对沪深
300 组合 从 2014 年 5 月到 2016 年 3 月共 23 期的因子暴露度进行了计算和分析。
2 均值-方差模型(Markowitz Mean-Variance Model)
1952 年,马柯维茨发表了《证券组合选择》,建立起现代投资组合理论的框架。马科维茨认为,投资者可以用预期收益率
,以及收益率的标准差
来完全构建和衡量一个投资组合,因此,该模型又称为均值-方差模型。依据他的观点,对于一个资产数目为
,且各资产头寸相同的投资组合,如果已知每一个资产收益率的方差
和资产两两之间的协方差
,则我们可以计算这个投资组合的方差:
对于包含
个资产的投资组合,我们需要计算
个协方差,通常以协方差矩阵来表示:
此时,资产的协方差矩阵包含了我们投资组合的一切风险信息。在实际计算中,我们需要通过历史数据来计算经验协方差矩阵
(empirical covariance matrix),作为协方差矩阵的估计。然而,使用经验协方差矩阵存在以下问题:
(1)数据量要求大。要对协方差矩阵实现较为准确的估计,需要保证观测值数目大于矩阵的维数。考虑以沪深
300 的 300 个成分股作为投资组合,以月度数据计算经验协方差矩阵,则需要至少
300/12 = 25 年的数据,因此缺乏现实可行性;
(2)依据历史数据进行协方差估计无法反映投资组合中资产的结构性变化(例如并购);
(3)大量资产两两之间的协方差计算,容易出现多重比较谬误(multiple
comparison fallacy)的问题,因而引起资产之间相关性的错误判断。
(4)历史数据中包含大量的噪音,因此简单使用资产的协方差矩阵进行预测会造成较大的偏差。
2 结构化风险模型 (Structural Risk Model, SRM)
针对以上用资产的协方差矩阵来衡量投资组合风险所存在的缺陷,国际著名的投资组合表现分析研究机构
MSCI Barra 使用结构化风险模型(也称多因子模型,以下简称
SRM)来衡量投资组合的表现和风险。其核心思想是,我们可以选取一系列公共因子(common
factors)和特异因子 (idiosyncratic
factors)来描述一个投资组合的风险。常用的公共因子有所属行业,成长性,市盈率等,特异因子则是和公共因子相对的概念,用于解释每个资产的收益率中不能用公共因子解释的部分。基于这个思路,投资组合的收益率
可以用资产的头寸
,因子暴露(factor
exposure)矩阵
,因子收益率
和特异因子(idiosyncratic
factors)收益率
的线性组合来表示:
其中,因子暴露
又称因子载荷(factor
loading),用于衡量因子对投资组合收益率的贡献。当因子为行业因子时,
为取值只有
0 和 1 的哑变量(dummy variable),表示该资产是否属于该行业;当因子为市盈率等连续变量时,为减少回归建模中残差的异方差性,通常要进行剔除离群值和标准化的处理。
另外,SRM
给出了以下的两个假设:
(1)对于同一个资产
,因子收益率和特异收益率不存在线性相关,即
;
(2)对于两个不同的资产
和
,它们的特异收益率也不存在线性相关,即
。基于这两个假设,我们可以推导出
SRM 的投资组合风险表达式:
其中
为投资组合收益率的标准差,
为因子收益率的协方差矩阵。
和
分别为权重向量和特异因子收益率方差矩阵。
上述两个表达式即为结构化风险模型的核心。虽然它们的形式上稍显复杂,但它们的意义是明确的:投资组合的风险可以用因子收益率的协方差矩阵,而非投资组合中资产的收益率的协方差矩阵来描述。从数据处理的角度来看,SRM是一种数据降维技术。因此,它具有数据降维通常的优点:
(1)去除数据中的噪音;
(2)它能够**减少计算量,因此也降低了出现多重比较谬误的可能性。例如,一个包含
500 个资产的投资组合,如果要构建其相关系数矩阵,则需要计算
500*(500-1)/2 = 124,750 个相关系数,如果选用 50 个因子的相关系数来描述,则只需要计算
50*(50-1)/2 = 1225 个相关系数;
(3)因子的统计量通常比资产的统计量有更好的稳定性,因此基于SRM能给出更精确的长期预测;
(4)因子暴露度的调整可以捕捉资产的结构性变化;
(5)因子本身有清晰的经济学涵义,在对
SRM 的因子进行筛选的过程中,也会加深我们对于投资组合风险来源的认识。
3 公共因子的选择
在一般的 SRM 实现中,因子被分为两大类:行业因子和风格因子。参照国家统计局的行业分类方法,我们选定了
19 个行业因子(表1),以取值为
0 或 1 的哑变量(dummy variable)表示。而风格因子则对应一些选择投资组合常见的主题和标准,包括9个类型:贝塔值(beta),动量(momentum),规模(size),盈利率(earnings
yield),波动率(volatility),成长性(growth),价值(value),杠杆(leverage)和流动性(liquidity)。因此在目前的建模中,我们一共使用28个因子。
4 风格因子的实现
行业因子的定义见表1。
表1:依据国家统计局的分类选定的行业因子
接下来我们将介绍如何构建风格因子。在部分风格因子的构建中,我们使用了多个细分因子(一些资料称其为
atom descriptors)来组成一个因子,以表征该因子不同的特征。例如,在盈利率因子的构建中,我们使用了市盈率,每股经营活动产生的现金流量净额和每股收益(扣除/稀释)三个描述变量。如果在线性回归模型中直接使用这些细分因子,因为它们所属的类型相同,因此可能会导致有多个细分因子所属的因子类型对模型参数估计的影响力过大,且容易引起共线性的问题。对此,我们把属于同一类型的多个因子进行加权组合得到该类型对应的暴露度。而因子的权重可通过对上一期数据进行随机森林(random
forest)回归分析获得。
另外我们需要对一些稳定性较差(自相关性较低)的因子(动量和波动率)进行指数加权处理,给予时间较近的交易日数据较大的权重。具体地,我们采用半衰期为30天的指数系数(
),此时在风险暴露度矩阵的估计中,近
30 个交易日的数据将会占一半的权重。我们在 200 个交易日处做截断(更早的交易日的权重非常小,已可忽略不计)。在下面的因子计算中,我们将会统一使用
表示归一化指数权重向量。
最后,在风格因子的计算中,除了在
RiceQuant 策略研究平台上调用的变量外,我们还需要定义以下的衍生变量和运算:
衍生变量:
和
分别表示股票和基准组合的
200 个交易日的每日超额收益率时间序列;
和
分别表示股票和基准组合中资产的
200 个交易日的每日收益率时间序列;
表示归一化指数权重;
是贝塔值计算后得到的残差+截距项。outstanding_shares
表示流通股本,TotalVolumeTraded/outstanding_shares 计算得到的即我们通常说的换手率。
运算:
表示计算变量的协方差;
表示计算变量的方差;
表示计算向量
和向量
的内积;
表示对变量取对数;
表示计算变量的标准差;
表示计算变量均值,
和
分别表示取一组数据中的最大值和最小值。
基于以上的讨论,我们的风格因子构建所需的变量见表2,具体计算见表3。
表2:RiceQuant 策略研究平台上调用的变量
表3:风格因子的的定义和计算
5 沪深300的因子暴露度分析
接下来,我们将把沪深300指数和各个风格因子的变化趋势进行比较分析(图1和图2)。在这里,我们首先给出沪深300指数的基本计算公式:
报告期指数=报告期成份股的调整市值/基日成份股的调整市值×1000
其中基日为2004年12月31日。由于可以看出,沪深300指数主要决定于其成分股的市值。基于这个认识,我们对各个风格因子的变化进行分析。
5.1 规模因子,盈利率因子和价值因子
基于风格因子的定义,规模因子的暴露度是直接对市值取对数,而盈利率因子暴露度中的市盈率和市值成正比,因此这两个因子和沪深300的变化趋势基本一致(图1);而对于价值因子的暴露度,其和市值成反比,因此和沪深300的变化呈相反趋势(图2)。
5.2 贝塔值因子
贝塔值是衡量一个投资组合对基准组合的敏感性的指标。在这里,虽然我们使用的投资组合是沪深300的300个成分股,但贝塔值并不恒等于1。其原因在于,我们进行每一期因子暴露度计算时,都使用月底的成分股权重,和过去
200 个交易日沪深 300 指数成分股的权重稍有不同。在图 1 中,我们可以看到当指数出现大幅震荡时,贝塔值因子暴露度会明显偏离于
1,即依据每期月末的权重构建的沪深 300 成分股组合,和过去
200 个交易日的沪深 300 指数的敏感性显著提高或是降低(图1)。
5.3 动量因子
在动量因子的构建过程中,我们使用了
200 个交易日的加权平均值来展示个股的长期动量,对比沪深 300 指数的和动量因子的变化趋势,可以发现当市场出现大幅震荡时,这个因子暴露度的变化呈现出一定的滞后性。2015年下半年市场出现大幅下跌,但2016年2月动量才从正变为负(图1)。
5.4 波动率因子
波动率因子暴露度的走势和沪深300指数的走势基本一致,较好地反映了市场的波动情况(图1)。
5.5 成长性因子
成长性因子的构建使用了四个变量的同比增长率,和企业的股票市值并没有直接联系。有意思的是,沪深300的成长性因子暴露度出现三个峰值,这三个峰值均出现在市场波动较小的阶段,可能反映出在市场行情较为平淡时,投资者较为倾向于投资具有较好成长性的股票(图2)。
5.6 杠杆因子
杠杆因子的计算公式是:(负债合计+总资产)/总资产,和企业的股票市值没有直接联系,但其暴露度变化和沪深300指数的变化呈现相反的趋势。可能反映在牛市当中,杠杆低的企业的股票更受投资者青睐(图2)。
5.7 流动性因子
流动性因子的走势和沪深300指数的走势基本一致,较好地反映了市场的整体交易情况(图2)。
图1 沪深300指数变化和风格因子(贝塔值,动量,规模,盈利率和波动率)的对比
图2 沪深300指数变化和风格因子(成长性,价值,杠杆和流动性)的对比
6 总结
在这一份报告里,我们简要介绍了Barra
结构化风险模型,并对一系列风格因子进行了构建和分析。我们以沪深
300 成分股作为投资组合进行测试。测试结果表明,大部分因子均较好地反映了沪深
300 指数的变化特征,以及在不同的市场环境下投资者的一些投资倾向。在动量因子的分析中,我们发现因子只能反映市场的长期动量变化,而当市场出现大幅震荡的行情时,其变化出现了一定的滞后性。所以在下一步的建模中,我们将进一步添加表征短期和中期动量的细分因子,使其能够捕捉不同情况下的市场变化趋势
作者:Ricequant量化
链接:https://xueqiu.com/7381621247/73649418
来源:雪球
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

相关文章推荐
- Barra 结构化风险模型实现(1)——沪深300指数的风格因子暴露度分析
- 转:结构化风险模型与业绩归因
- (斯坦福机器学习课程笔记)混合高斯模型,朴素贝叶斯,混合朴素贝叶斯模型,因子分析
- 信息安全风险分析理论模型概述
- EM算法--应用到三个模型: 高斯混合模型 ,混合朴素贝叶斯模型,因子分析模型
- 第13节-混合高斯模型,混合贝叶斯模型,因子分析及其EM求解
- 结构化与面向对象的需求分析与模型设计
- 数学之路-数据分析进阶-Cox比例风险回归模型
- 风险分析模型
- 因子分析-模型参数估计方法
- 斯坦福ML公开课笔记13B-因子分析模型及其EM求解
- 14.混合高斯模型,混合贝叶斯模型,因子分析算法
- 斯坦福ML公开课笔记13B-因子分析模型及其EM求解
- 聚类、逻辑回归、主成分与因子分析等几类模型要点
- AMOS分析技术:测量模型分析;聊聊验证性因子分析(CFA)与探索性因子分析(EFA)的异同点
- HBase数据模型解析和基本的表设计分析
- Linux设备模型分析之device(基于3.10.1内核)
- tomcat的NIO线程模型源码分析
- PHP源码分析之线程安全模型