Scrapy简单入门及实例讲解
2017-12-20 17:46
211 查看
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
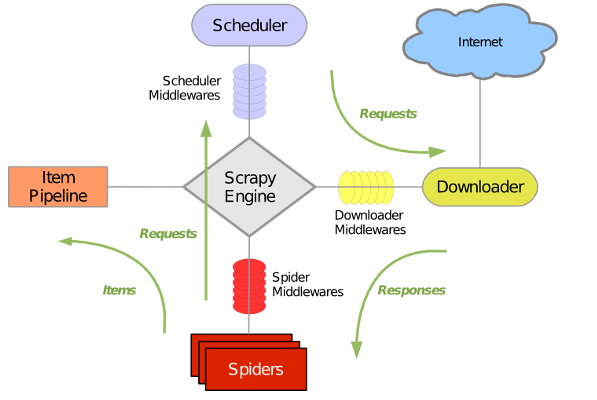
Scrapy主要包括了以下组件:
引擎(Scrapy)
用来处理整个系统的数据流, 触发事务(框架核心)
调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
引擎从调度器中取出一个链接(URL)用于接下来的抓取
引擎把URL封装成一个请求(Request)传给下载器
下载器把资源下载下来,并封装成应答包(Response)
爬虫解析Response
解析出实体(Item),则交给实体管道进行进一步的处理
解析出的是链接(URL),则把URL交给调度器等待抓取
一、安装
注:windows平台需要依赖pywin32,请根据自己系统32/64位选择下载安装,https://sourceforge.net/projects/pywin32/
二、爬虫举例
入门篇:美剧天堂前100最新(http://www.meijutt.com/new100.html)
1、创建工程
2、创建爬虫程序
3、自动创建目录及文件
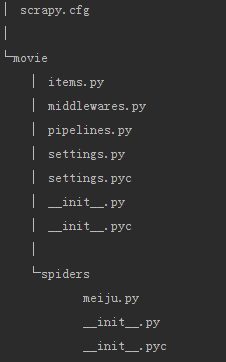
4、文件说明:
scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py 设置数据存储模板,用于结构化数据,如:Django的Model
pipelines 数据处理行为,如:一般结构化的数据持久化
settings.py 配置文件,如:递归的层数、并发数,延迟下载等
spiders 爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名
5、设置数据存储模板
items.py
6、编写爬虫
meiju.py
7、设置配置文件
settings.py增加如下内容
8、编写数据处理脚本
pipelines.py
9、执行爬虫
10、结果

进阶篇:爬取校花网(http://www.xiaohuar.com/list-1-1.html)
1、创建一个工程
2、创建爬虫程序
3、自动创建目录及文件

4、文件说明:
scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py 设置数据存储模板,用于结构化数据,如:Django的Model
pipelines 数据处理行为,如:一般结构化的数据持久化
settings.py 配置文件,如:递归的层数、并发数,延迟下载等
spiders 爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名
5、设置数据存储模板
6、编写爬虫
7、设置配置文件
8、编写数据处理脚本
9、执行爬虫
结果:
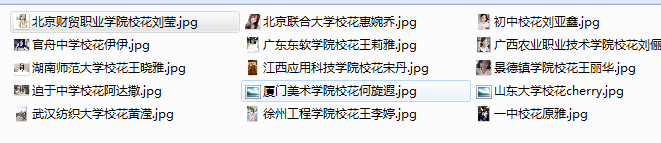
终极篇:我想要所有校花图
注明:基于进阶篇再修改为终极篇
# xh.py
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
Scrapy主要包括了以下组件:
引擎(Scrapy)
用来处理整个系统的数据流, 触发事务(框架核心)
调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
引擎从调度器中取出一个链接(URL)用于接下来的抓取
引擎把URL封装成一个请求(Request)传给下载器
下载器把资源下载下来,并封装成应答包(Response)
爬虫解析Response
解析出实体(Item),则交给实体管道进行进一步的处理
解析出的是链接(URL),则把URL交给调度器等待抓取
一、安装
二、爬虫举例
入门篇:美剧天堂前100最新(http://www.meijutt.com/new100.html)
1、创建工程
2、创建爬虫程序
3、自动创建目录及文件
4、文件说明:
scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py 设置数据存储模板,用于结构化数据,如:Django的Model
pipelines 数据处理行为,如:一般结构化的数据持久化
settings.py 配置文件,如:递归的层数、并发数,延迟下载等
spiders 爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名
5、设置数据存储模板
items.py
6、编写爬虫
meiju.py
7、设置配置文件
settings.py增加如下内容
8、编写数据处理脚本
pipelines.py
9、执行爬虫
10、结果
进阶篇:爬取校花网(http://www.xiaohuar.com/list-1-1.html)
1、创建一个工程
2、创建爬虫程序
3、自动创建目录及文件
4、文件说明:
scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py 设置数据存储模板,用于结构化数据,如:Django的Model
pipelines 数据处理行为,如:一般结构化的数据持久化
settings.py 配置文件,如:递归的层数、并发数,延迟下载等
spiders 爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名
5、设置数据存储模板
6、编写爬虫
7、设置配置文件
8、编写数据处理脚本
9、执行爬虫
结果:
终极篇:我想要所有校花图
注明:基于进阶篇再修改为终极篇
# xh.py

相关文章推荐
- Scrapy简单入门及实例讲解与安装
- Scrapy简单入门及实例讲解
- Scrapy简单入门及实例讲解
- activiti学习笔记 最简单入门实例
- NSURLSession 简单入门及断点下载续传实例
- Android入门简单实例
- zookeeper 入门讲解实例
- 简洁 DIV+CSS布局入门之四 ( DIV+CSS常用 常用CSS DIV+CSS实例 简单DIV+CSS DIV+CSS布局分析 DIV+CSS流程)
- Hibernate学习笔记(一)——简单的Hibernate实例入门
- Ajax+PHP简单基础入门实例教程
- cocos2d x 入门学习(一)实例制作简单的射击小游戏Star Fighter
- Mybatis 入门之resultMap与resultType讲解实例
- MVC——入门+最简单的小实例
- JFreeChart简单介绍及入门实例
- Hibernate 4.2 简单入门实例
- zookeeper入门讲解实例
- WebService入门系列教程-简单的WebSercice实例
- smarty简单入门实例
- Lucene入门以及简单实例
- Apache POI:Java程序读写Microsoft Office格式文档——简单完整实例讲解