seglink 论文阅读
2017-12-14 11:02
337 查看
题目:Detecting Oriented Text in Natural Images by Linking Segments
作者:Baoguang Shi1 Xiang Bai1∗ Serge Belongie2
cvpr2017
代码、论文、偏移生成
https://github.com/dengdan/seglink
https://arxiv.org/abs/1703.06520
http://fromwiz.com/share/s/34GeEW1RFx7x2iIM0z1ZXVvc2yLl5t2fTkEg2ZVhJR2n50xg
摘要
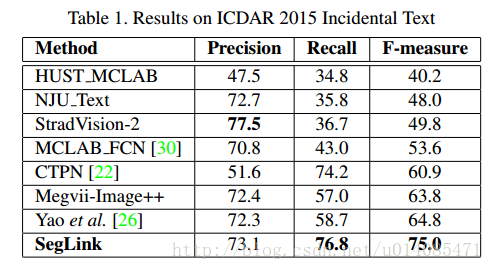
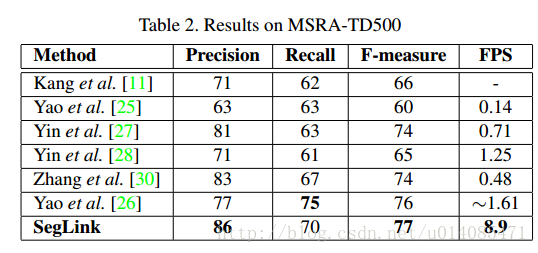
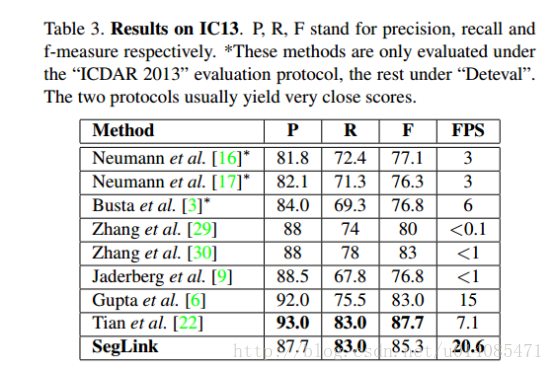
其主要思想是将文本分解为两个局部可检测的元素,即片段(分割)和链接。片段是对字符或者单词的方框,链接用来连接方框;最后检测是通过连接片段产生。f-measure达到75(ICDAR 2015),512-512超过20fps,而且可以检测非拉丁文。
1.介绍
特点:
鲁棒性:75 f-measure
有效性:20fps 512*512
概括性:非拉丁文检测(无修改,还是有训练吧?)
3.Segment Linking
输入固定大小,通过置信度输出固定数量的连接和片段,组合成边界框。bounding box是一个旋转的矩形:
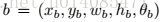
3.1 CNN模型
VGG16改fc为conv,再加conv8-11

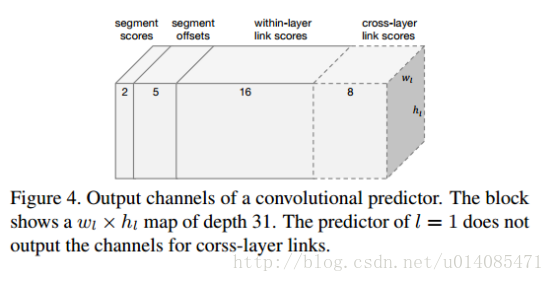
切片和连接在6个层上预测,conv4_3, conv7, conv8_2, conv9_2, conv10_2,conv11,一个3*3的卷积层接在这些层后面生成预测切片、链接的模型,这里对这些特征层和预测器加索引l=1,..6
3.2切片检测
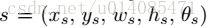
在输入图片上根据feature map的置信度与偏移设置default box
default box的map上的坐标(x,y)到输入图像的坐标转换
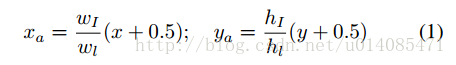
根据map的宽高设置一个固定的al(相当于每个点都代表固定大小的框)
预测器生成7个通道的结果,俩个是设置是与不是文字,5个渠道设置以下参数
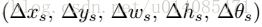
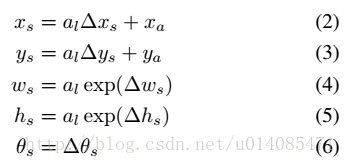
ps:这里就可以相当于,输入图像缩放到map大小,一块区域在这里代表一个点
经验值:
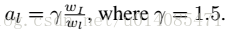
3.3层内链接
一个链接连接一对切片,连接一个单词的两个字母,分离两个单词(负样本)。
一个位置有八个方向的连接,预测器生成16通道,每个方向2个通道(是链接、不是链接)

3.4层间链接
一个单词可能在不同尺寸的map上被发现,所以提出这种方法,层间链接只连接相邻层
这里有个重要的特点,前面的map是后面的map的2倍,因为他们是经过池化或者是步长2的卷积,不过必须是偶数才可能有这样的关系,所以这里设置输入图像的大小要能对128整除
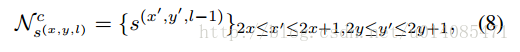
层间链接只在l=2…6做检测,每个点输出4个邻居的链接,每个链接还是用俩个值表示,所以是8个通道
ps:预测卷积核应该同时对两个map做卷积,具体得看代码才知道
每个feature-map输出大概如下(map1没有层间链接)
3.5整合碎片和链接
根据置信分数过滤,阈值分别是α,β,实验发现阈值不敏感,0.1变化对应f-measure小于1%变化。
碎片和链接可以被当作图,合并计算完整的bounding box遵循算法1:

大概是:
求平均角度
找直线,确认b,使得所有块中心到线距离最短
在直线上做垂直射线到各个片段,找到最长距离的(可能是射线经过片段边边,具体看代码)
计算bounding box
4.训练
4.1正样本定义
(a.中心在bounding box里
(b.大小满足下列
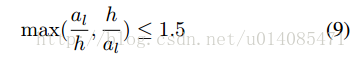
还有一个没理解: it is labeled as it is labeled as positive and matched to the word that has the closest size,i.e. the one with the minimal value at the left-hand side of Eq. 9 (多个单词的情况下如果大小相近还是可以连在一起?)
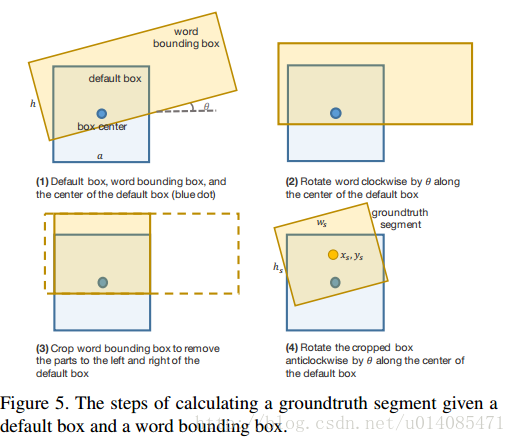
4.2偏移量根据fig5计算,根据公式2-6推导:
4.3链接根据俩个原则设置正样本,1:两个切片都是正的,2同一个单词
4.4优化
损失函数
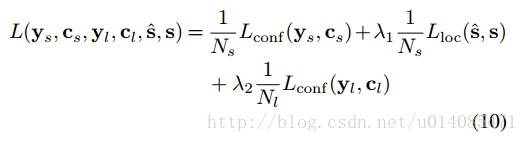
权重在实践中都设了1
4.5在线困难消极样本挖掘
遵循文献20的方法,保持消极:积极样本数量不超过3:1
Shrivastava, A. Gupta, and R. B. Girshick. Training region-based object detectors with online hard example mining. In CVPR, 2016
4.6数据增强
像ssd和yolo那样缩放裁剪训练
5.实验
SynthText 预训练
4 GPUs in parallel,training a batch takes about 0.5s. The whole training process takes less than a day.
非拉丁文本也不错
不好的结果:

作者:Baoguang Shi1 Xiang Bai1∗ Serge Belongie2
cvpr2017
代码、论文、偏移生成
https://github.com/dengdan/seglink
https://arxiv.org/abs/1703.06520
http://fromwiz.com/share/s/34GeEW1RFx7x2iIM0z1ZXVvc2yLl5t2fTkEg2ZVhJR2n50xg
摘要
其主要思想是将文本分解为两个局部可检测的元素,即片段(分割)和链接。片段是对字符或者单词的方框,链接用来连接方框;最后检测是通过连接片段产生。f-measure达到75(ICDAR 2015),512-512超过20fps,而且可以检测非拉丁文。
1.介绍
特点:
鲁棒性:75 f-measure
有效性:20fps 512*512
概括性:非拉丁文检测(无修改,还是有训练吧?)
3.Segment Linking
输入固定大小,通过置信度输出固定数量的连接和片段,组合成边界框。bounding box是一个旋转的矩形:
3.1 CNN模型
VGG16改fc为conv,再加conv8-11
切片和连接在6个层上预测,conv4_3, conv7, conv8_2, conv9_2, conv10_2,conv11,一个3*3的卷积层接在这些层后面生成预测切片、链接的模型,这里对这些特征层和预测器加索引l=1,..6
3.2切片检测
在输入图片上根据feature map的置信度与偏移设置default box
default box的map上的坐标(x,y)到输入图像的坐标转换
根据map的宽高设置一个固定的al(相当于每个点都代表固定大小的框)
预测器生成7个通道的结果,俩个是设置是与不是文字,5个渠道设置以下参数
ps:这里就可以相当于,输入图像缩放到map大小,一块区域在这里代表一个点
经验值:
3.3层内链接
一个链接连接一对切片,连接一个单词的两个字母,分离两个单词(负样本)。
一个位置有八个方向的连接,预测器生成16通道,每个方向2个通道(是链接、不是链接)
3.4层间链接
一个单词可能在不同尺寸的map上被发现,所以提出这种方法,层间链接只连接相邻层
这里有个重要的特点,前面的map是后面的map的2倍,因为他们是经过池化或者是步长2的卷积,不过必须是偶数才可能有这样的关系,所以这里设置输入图像的大小要能对128整除
层间链接只在l=2…6做检测,每个点输出4个邻居的链接,每个链接还是用俩个值表示,所以是8个通道
ps:预测卷积核应该同时对两个map做卷积,具体得看代码才知道
每个feature-map输出大概如下(map1没有层间链接)
3.5整合碎片和链接
根据置信分数过滤,阈值分别是α,β,实验发现阈值不敏感,0.1变化对应f-measure小于1%变化。
碎片和链接可以被当作图,合并计算完整的bounding box遵循算法1:
大概是:
求平均角度
找直线,确认b,使得所有块中心到线距离最短
在直线上做垂直射线到各个片段,找到最长距离的(可能是射线经过片段边边,具体看代码)
计算bounding box
4.训练
4.1正样本定义
(a.中心在bounding box里
(b.大小满足下列
还有一个没理解: it is labeled as it is labeled as positive and matched to the word that has the closest size,i.e. the one with the minimal value at the left-hand side of Eq. 9 (多个单词的情况下如果大小相近还是可以连在一起?)
4.2偏移量根据fig5计算,根据公式2-6推导:
4.3链接根据俩个原则设置正样本,1:两个切片都是正的,2同一个单词
4.4优化
损失函数
权重在实践中都设了1
4.5在线困难消极样本挖掘
遵循文献20的方法,保持消极:积极样本数量不超过3:1
Shrivastava, A. Gupta, and R. B. Girshick. Training region-based object detectors with online hard example mining. In CVPR, 2016
4.6数据增强
像ssd和yolo那样缩放裁剪训练
5.实验
SynthText 预训练
4 GPUs in parallel,training a batch takes about 0.5s. The whole training process takes less than a day.
非拉丁文本也不错
不好的结果:

相关文章推荐
- 双流神经网络及3D卷积系列论文阅读笔记
- 硕博经验——科研论文阅读与写作实战技巧
- 《Very Deep Convolutional Networks for Large-Scale Image Recognition》论文阅读
- 论文阅读(Xiang Bai——【CVPR2016】Multi-Oriented Text Detection with Fully Convolutional Networks)
- 论文阅读笔记-learning multi-domain convolutional neural networks for visual tracking
- 阅读图像显著性检测论文一:A Model of Saliency-Based Visual Attention for Rapid Scene Analysis
- 论文阅读和撰写方法总结
- LeNet论文阅读:LeNet结构以及参数个数计算
- 论文阅读笔记:U-Net: Convolutional Networks for Biomedical Image Segmentation
- node2vec论文阅读
- 1611.A Discriminatively Learned CNN Embedding for Person Re-identification论文阅读笔记
- 目标检测定位与分割论文阅读心得总结:FCN U-Net R-CNN FR-CNN Faster R-CNN Mask R-CNN
- 论文阅读(Weilin Huang——【arXiv2016】Accurate Text Localization in Natural Image with Cascaded Convolutional Text Network)
- 论文阅读(1)——ImageNet Classification with Deep Convolutional Neural Networks
- 【CV论文阅读】生成式对抗网络GAN
- 论文阅读理解 - Panoptic Segmentation 全景分割
- 整理阅读的论文(五)
- SmartDroid论文阅读
- ResNet论文阅读---《Deep Residual Learning for Image Recognition》
- CNN用于医学图像轮廓检测的最近发展 论文阅读