论文阅读笔记-learning multi-domain convolutional neural networks for visual tracking
2016-11-28 19:20
661 查看
论文阅读笔记-learning multi-domain convolutional neural networks for visual tracking
VOT 2015挑战赛的冠军论文,16年又发表在CVPR上,性能很强大,几乎可以称得上是目前跟踪性能最好的一种算法。
铺垫完了之后,说一下该算法的优缺点:
优点嘛,当然是跟的准,基本上形变啊,快速移动啊,光照啊,低分辨率啊,遮挡啊,这些都不是问题;
不过缺点也很明显,那就是慢!官方数据说是一秒一帧就已经很慢了,而在第一帧开始之时单是网络再训练就得十几秒,每隔十帧的网络微调也得花费两倍的时间,中间的九帧倒是差不多一秒一帧。
不过性能好,再慢也忍了,接下来就详述一下这篇论文的内容。
首先,作者抛出了一个引子,说基于分类的网络不适用于做目标跟踪,原因在于,同一个object在不同的序列里可能是目标,也有可能只是一个路人甲,而分类的话不会区分这些;此外,之前那些算法都是为所有的序列学习一个统一的分类器,没有具体区分目标到底是人是鬼,啊不,是人是车,作者觉得这怎么可以呢,我们应该针对每一个序列的目标单独训练其分类器,大家互不影响,这样才对嘛。但是呢,作者又考虑到底层的很多特征是通用的,也是可以互利互惠的,因此,灵机一动,设计出了下图这样的网络结构:
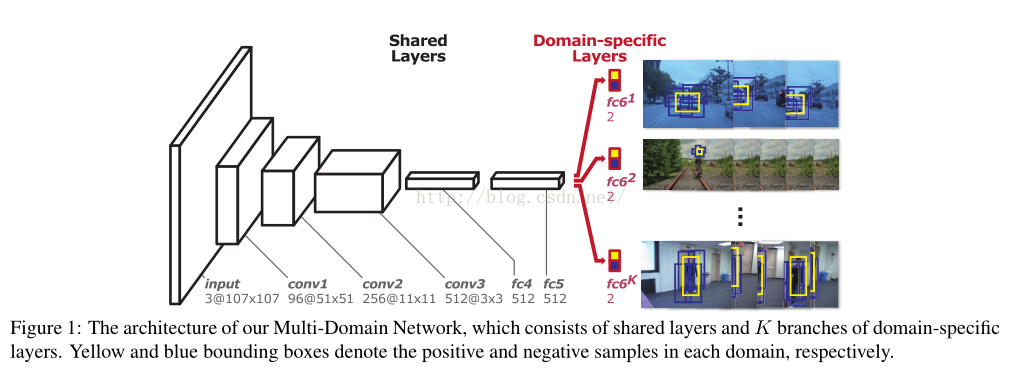
这个网络结构算是比较符合作者的心意了,前面这些层叫shared layers,大家一起公用提提特征啥的,最后一层呢是specific layer,这个就是本文的大特色了,论文的题目multi-domain说的就是这里。这里的特别之处在于,针对每一个训练序列,作者都为它单独分了一个支路,有多少个序列,就分多少支路,这样就实现了作者针对每一个序列单独训练分类器的设想。每一个fc6的分枝都是一个二分类器,来针对这个序列分别给出正负样本的概率得分,是不是听起来就很牛逼的样子。
接着来说说训练网络的一些细节问题,为了在第三个卷积层获得3*3的特征,作者反向推算出输入的图像大小应该是107*107,,所以所有的输入图像大小都是107*107哦;为了有个好的初始化,迁移学习大法好,作者对于前三层卷积层就直接迁移使用了VGG-M训练好的参数,然后用很小的学习率更新,后面全连接层用的随机初始化,学习率是前三层的十倍倍乘。至于输入图像,并不是原图像,而是crop出的部分图像,也就是样本,然后resize到固定大小107*107,再送入网络。
另外一点要说的是,作者到底是如何摆放这些序列的训练顺序的,如果你说一个接一个,一个训练完了再训练下一个呗,那就太naive了,当初naive的我就这样试着训练了一个自以为会很牛逼,结果惨不忍睹的网络,会对最后一个序列过拟合啊亲! 聪明的作者当然也考虑到了这个问题,所以,他在训练的时候,一个序列只训练一个batch,就换下个序列,然后外面用个大循环,多循环几回就把每个序列都训练到位了,是不是很机智。
好,搞懂这些之后,就开始网络训练了,大概个把小时以后,训练过程结束。训练结束也就意味着我们即将告别这些形形色色的fc6各分支同胞们,感谢他们在训练过程中做出的贡献,但是由于这是针对每个序列特有的分类器,而未来的行程中他们将不再有什么价值,所以,这些分支将全被拆掉。取而代之的是一个全新的单个的fc6,在跟踪阶段,我们将会用第一帧的正负样本来对这个新的fc6进行训练,使之成为对当前目标所特有的分类器。与此同时,前三个卷积层参数会冻结,来保留低层通用特征,不进行参数更新,而fc4和fc5会有微微的更新,以适应新序列新目标。
跟踪阶段里,作者也是使用了很多的技巧,至于详情有机会再补喽。
VOT 2015挑战赛的冠军论文,16年又发表在CVPR上,性能很强大,几乎可以称得上是目前跟踪性能最好的一种算法。
铺垫完了之后,说一下该算法的优缺点:
优点嘛,当然是跟的准,基本上形变啊,快速移动啊,光照啊,低分辨率啊,遮挡啊,这些都不是问题;
不过缺点也很明显,那就是慢!官方数据说是一秒一帧就已经很慢了,而在第一帧开始之时单是网络再训练就得十几秒,每隔十帧的网络微调也得花费两倍的时间,中间的九帧倒是差不多一秒一帧。
不过性能好,再慢也忍了,接下来就详述一下这篇论文的内容。
首先,作者抛出了一个引子,说基于分类的网络不适用于做目标跟踪,原因在于,同一个object在不同的序列里可能是目标,也有可能只是一个路人甲,而分类的话不会区分这些;此外,之前那些算法都是为所有的序列学习一个统一的分类器,没有具体区分目标到底是人是鬼,啊不,是人是车,作者觉得这怎么可以呢,我们应该针对每一个序列的目标单独训练其分类器,大家互不影响,这样才对嘛。但是呢,作者又考虑到底层的很多特征是通用的,也是可以互利互惠的,因此,灵机一动,设计出了下图这样的网络结构:
这个网络结构算是比较符合作者的心意了,前面这些层叫shared layers,大家一起公用提提特征啥的,最后一层呢是specific layer,这个就是本文的大特色了,论文的题目multi-domain说的就是这里。这里的特别之处在于,针对每一个训练序列,作者都为它单独分了一个支路,有多少个序列,就分多少支路,这样就实现了作者针对每一个序列单独训练分类器的设想。每一个fc6的分枝都是一个二分类器,来针对这个序列分别给出正负样本的概率得分,是不是听起来就很牛逼的样子。
接着来说说训练网络的一些细节问题,为了在第三个卷积层获得3*3的特征,作者反向推算出输入的图像大小应该是107*107,,所以所有的输入图像大小都是107*107哦;为了有个好的初始化,迁移学习大法好,作者对于前三层卷积层就直接迁移使用了VGG-M训练好的参数,然后用很小的学习率更新,后面全连接层用的随机初始化,学习率是前三层的十倍倍乘。至于输入图像,并不是原图像,而是crop出的部分图像,也就是样本,然后resize到固定大小107*107,再送入网络。
另外一点要说的是,作者到底是如何摆放这些序列的训练顺序的,如果你说一个接一个,一个训练完了再训练下一个呗,那就太naive了,当初naive的我就这样试着训练了一个自以为会很牛逼,结果惨不忍睹的网络,会对最后一个序列过拟合啊亲! 聪明的作者当然也考虑到了这个问题,所以,他在训练的时候,一个序列只训练一个batch,就换下个序列,然后外面用个大循环,多循环几回就把每个序列都训练到位了,是不是很机智。
好,搞懂这些之后,就开始网络训练了,大概个把小时以后,训练过程结束。训练结束也就意味着我们即将告别这些形形色色的fc6各分支同胞们,感谢他们在训练过程中做出的贡献,但是由于这是针对每个序列特有的分类器,而未来的行程中他们将不再有什么价值,所以,这些分支将全被拆掉。取而代之的是一个全新的单个的fc6,在跟踪阶段,我们将会用第一帧的正负样本来对这个新的fc6进行训练,使之成为对当前目标所特有的分类器。与此同时,前三个卷积层参数会冻结,来保留低层通用特征,不进行参数更新,而fc4和fc5会有微微的更新,以适应新序列新目标。
跟踪阶段里,作者也是使用了很多的技巧,至于详情有机会再补喽。

相关文章推荐
- 论文笔记《Learning Multi-Domain Convolutional Neural Networks for Visual Tracking》
- 论文笔记之:Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
- 论文原创笔记:Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
- Learning Multi-Domain Convolutional Neural Networks for Visual Tracking 笔记
- 深度学习笔记(一):Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
- 【计算机视觉】《Learning Multi-Domain Convolutional Neural Networks for Visual Tracking》
- 论文笔记之:Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Tracking
- Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
- 目标跟踪算法五:MDNet: Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
- 《3D Convolutional Neural Networks for Human Action Recognition》论文阅读笔记
- earning Multi-Domain Convolutional Neural Networks for Visual Tracking
- 【论文阅读笔记】CVPR2015-Long-term Recurrent Convolutional Networks for Visual Recognition and Description
- 【论文阅读笔记】Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- 论文笔记 STCT: Sequentially Training Convolutional Networks for Visual Tracking
- 论文阅读笔记:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- 论文笔记之:Fully-Convolutional Siamese Networks for Object Tracking
- 论文阅读:End-to-End Learning of Deformable Mixture of Parts and Deep Convolutional Neural Networks for H
- 论文阅读笔记:Fully Convolutional Networks for Semantic Segmentation
- 论文笔记 Visual Tracking with Fully Convolutional Networks
- 【论文笔记】Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition