TensorFlow简单实例(二):logistic regression
2017-12-12 11:08
183 查看
http://www.longxyun.com/blog.html [原文地址]
目前机器学习中,逻辑回归多用来估计某种事物的可能性。
例如用户在某电商平台搜索了一类商品,那么估计他的可能性,估计他想要哪一类或者哪几类商品,推荐给他。这在目前大部分电商平台处处可见。
Logistic regression可以用来回归,也可以用来分类,主要是二分类。主要是二分类。还记得上几节讲的支持向量机SVM吗?它就是个二分类的例如,它可以将两个不同类别的样本给分开,思想是找到最能区分它们的那个分类超平面。但当你给一个新的样本给它,它能够给你的只有一个答案,你这个样本是正类还是负类。例如你问SVM,某个女生是否喜欢你,它只会回答你喜欢或者不喜欢。这对我们来说,显得太粗鲁了,要不希望,要不绝望,这都不利于身心健康。那如果它可以告诉我,她很喜欢、有一点喜欢、不怎么喜欢或者一点都不喜欢,你想都不用想了等等,告诉你她有49%的几率喜欢你,总比直接说她不喜欢你,来得温柔。而且还提供了额外的信息,她来到你的身边你有多少希望,你得再努力多少倍,知己知彼百战百胜,哈哈。Logistic regression就是这么温柔的,它给我们提供的就是你的这个样本属于正类的可能性是多少。
一个线性模型的输出值 y 越大,这个事件 P(Y=1|x) 发生的概率就越大。 另一方面,我们可以用事件的几率(odds)来表示事件发生与不发生的比值,假设发生的概率是 p ,那么发生的几率(odds)是 p/(1-p) , odds 的值域是 0 到正无穷,几率越大,发生的可能性越大。将我们的直觉与几率联系起来的就是下面这个(log odds)或者是 logit 函数
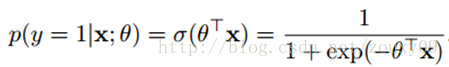
这里θ是模型参数,也就是回归系数,σ是sigmoid函数。实际上这个函数是由下面的对数几率(也就是x属于正类的可能性和负类的可能性的比值的对数)变换得到的:
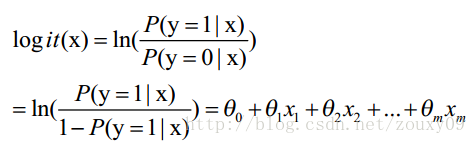
换句话说,y也就是我们关系的变量,例如她喜不喜欢你,与多个自变量(因素)有关,例如你人品怎样、车子是两个轮的还是四个轮的、长得胜过潘安还是和犀利哥有得一拼、有千尺豪宅还是三寸茅庐等等,我们把这些因素表示为x1, x2,…, xm。那这个女的怎样考量这些因素呢?最快的方式就是把这些因素的得分都加起来,最后得到的和越大,就表示越喜欢。但每个人心里其实都有一杆称,每个人考虑的因素不同,萝卜青菜,各有所爱嘛。例如这个女生更看中你的人品,人品的权值是0.6,不看重你有没有钱,没钱了一起努力奋斗,那么有没有钱的权值是0.001等等。我们将这些对应x1, x2,…, xm的权值叫做回归系数,表达为θ1, θ2,…, θm。他们的加权和就是你的总得分了。
所以说上面的logistic回归就是一个线性分类模型,它与线性回归的不同点在于:为了将线性回归输出的很大范围的数,例如从负无穷到正无穷,压缩到0和1之间,这样的输出值表达为“可能性”才能说服广大民众。当然了,把大值压缩到这个范围还有个很好的好处,就是可以消除特别冒尖的变量的影响(不知道理解的是否正确)。而实现这个伟大的功能其实就只需要平凡一举,也就是在输出加一个logistic函数。另外,对于二分类来说,可以简单的认为:如果样本x属于正类的概率大于0.5,那么就判定它是正类,否则就是负类。实际上,SVM的类概率就是样本到边界的距离,这个活实际上就让logistic regression给干了。
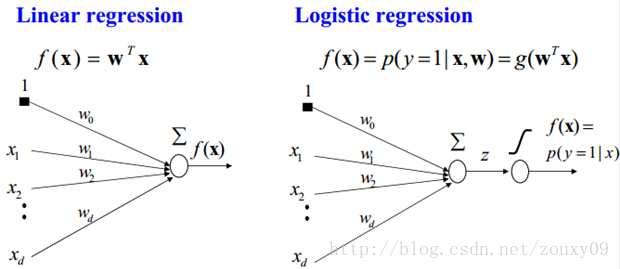
所以说,LogisticRegression 就是一个被logistic方程归一化后的线性回归,仅此而已。
好了,关于LR的八卦就聊到这。归入到正统的机器学习框架下,模型选好了,只是模型的参数θ还是未知的,我们需要用我们收集到的数据来训练求解得到它。那我们下一步要做的事情就是建立代价函数了。
LogisticRegression最基本的学习算法是最大似然。
假设我们有n个独立的训练样本{(x1, y1) ,(x2, y2),…, (xn, yn)},y={0, 1}。那每一个观察到的样本(xi, yi)出现的概率是:
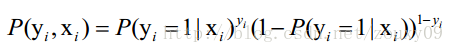
上面为什么是这样呢?当y=1的时候,后面那一项是不是没有了,那就只剩下x属于1类的概率,当y=0的时候,第一项是不是没有了,那就只剩下后面那个x属于0的概率(1减去x属于1的概率)。所以不管y是0还是1,上面得到的数,都是(x, y)出现的概率。那我们的整个样本集,也就是n个独立的样本出现的似然函数为(因为每个样本都是独立的,所以n个样本出现的概率就是他们各自出现的概率相乘):
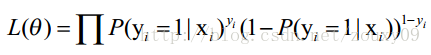
那最大似然法就是求模型中使得似然函数最大的系数取值θ*。这个最大似然就是我们的代价函数(cost function)了。
OK,那代价函数有了,我们下一步要做的就是优化求解了。我们先尝试对上面的代价函数求导,看导数为0的时候可不可以解出来,也就是有没有解析解,有这个解的时候,就皆大欢喜了,一步到位。如果没有就需要通过迭代了,耗时耗力。
我们先变换下L(θ):取自然对数,然后化简(不要看到一堆公式就害怕哦,很简单的哦,只需要耐心一点点,自己动手推推就知道了。注:有xi的时候,表示它是第i个样本,下面没有做区分了,相信你的眼睛是雪亮的),得到:
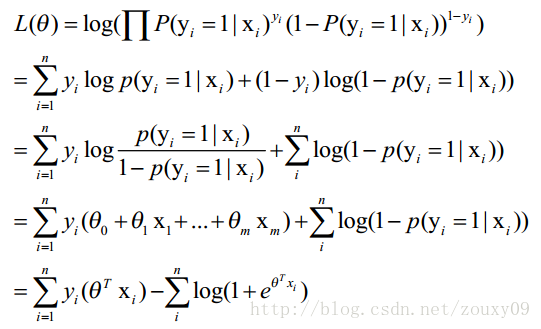
这时候,用L(θ)对θ求导,得到:
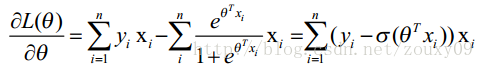
bae2
然后我们令该导数为0,你会很失望的发现,它无法解析求解。不信你就去尝试一下。所以没办法了,只能借助高大上的迭代来搞定了。这里选用了经典的梯度下降算法。
Tensorflow下的逻辑回归模型实例:
Python2.7+Tensorflow1.0

目前机器学习中,逻辑回归多用来估计某种事物的可能性。
例如用户在某电商平台搜索了一类商品,那么估计他的可能性,估计他想要哪一类或者哪几类商品,推荐给他。这在目前大部分电商平台处处可见。
Logistic regression可以用来回归,也可以用来分类,主要是二分类。主要是二分类。还记得上几节讲的支持向量机SVM吗?它就是个二分类的例如,它可以将两个不同类别的样本给分开,思想是找到最能区分它们的那个分类超平面。但当你给一个新的样本给它,它能够给你的只有一个答案,你这个样本是正类还是负类。例如你问SVM,某个女生是否喜欢你,它只会回答你喜欢或者不喜欢。这对我们来说,显得太粗鲁了,要不希望,要不绝望,这都不利于身心健康。那如果它可以告诉我,她很喜欢、有一点喜欢、不怎么喜欢或者一点都不喜欢,你想都不用想了等等,告诉你她有49%的几率喜欢你,总比直接说她不喜欢你,来得温柔。而且还提供了额外的信息,她来到你的身边你有多少希望,你得再努力多少倍,知己知彼百战百胜,哈哈。Logistic regression就是这么温柔的,它给我们提供的就是你的这个样本属于正类的可能性是多少。
一个线性模型的输出值 y 越大,这个事件 P(Y=1|x) 发生的概率就越大。 另一方面,我们可以用事件的几率(odds)来表示事件发生与不发生的比值,假设发生的概率是 p ,那么发生的几率(odds)是 p/(1-p) , odds 的值域是 0 到正无穷,几率越大,发生的可能性越大。将我们的直觉与几率联系起来的就是下面这个(log odds)或者是 logit 函数
这里θ是模型参数,也就是回归系数,σ是sigmoid函数。实际上这个函数是由下面的对数几率(也就是x属于正类的可能性和负类的可能性的比值的对数)变换得到的:
换句话说,y也就是我们关系的变量,例如她喜不喜欢你,与多个自变量(因素)有关,例如你人品怎样、车子是两个轮的还是四个轮的、长得胜过潘安还是和犀利哥有得一拼、有千尺豪宅还是三寸茅庐等等,我们把这些因素表示为x1, x2,…, xm。那这个女的怎样考量这些因素呢?最快的方式就是把这些因素的得分都加起来,最后得到的和越大,就表示越喜欢。但每个人心里其实都有一杆称,每个人考虑的因素不同,萝卜青菜,各有所爱嘛。例如这个女生更看中你的人品,人品的权值是0.6,不看重你有没有钱,没钱了一起努力奋斗,那么有没有钱的权值是0.001等等。我们将这些对应x1, x2,…, xm的权值叫做回归系数,表达为θ1, θ2,…, θm。他们的加权和就是你的总得分了。
所以说上面的logistic回归就是一个线性分类模型,它与线性回归的不同点在于:为了将线性回归输出的很大范围的数,例如从负无穷到正无穷,压缩到0和1之间,这样的输出值表达为“可能性”才能说服广大民众。当然了,把大值压缩到这个范围还有个很好的好处,就是可以消除特别冒尖的变量的影响(不知道理解的是否正确)。而实现这个伟大的功能其实就只需要平凡一举,也就是在输出加一个logistic函数。另外,对于二分类来说,可以简单的认为:如果样本x属于正类的概率大于0.5,那么就判定它是正类,否则就是负类。实际上,SVM的类概率就是样本到边界的距离,这个活实际上就让logistic regression给干了。
所以说,LogisticRegression 就是一个被logistic方程归一化后的线性回归,仅此而已。
好了,关于LR的八卦就聊到这。归入到正统的机器学习框架下,模型选好了,只是模型的参数θ还是未知的,我们需要用我们收集到的数据来训练求解得到它。那我们下一步要做的事情就是建立代价函数了。
LogisticRegression最基本的学习算法是最大似然。
假设我们有n个独立的训练样本{(x1, y1) ,(x2, y2),…, (xn, yn)},y={0, 1}。那每一个观察到的样本(xi, yi)出现的概率是:
上面为什么是这样呢?当y=1的时候,后面那一项是不是没有了,那就只剩下x属于1类的概率,当y=0的时候,第一项是不是没有了,那就只剩下后面那个x属于0的概率(1减去x属于1的概率)。所以不管y是0还是1,上面得到的数,都是(x, y)出现的概率。那我们的整个样本集,也就是n个独立的样本出现的似然函数为(因为每个样本都是独立的,所以n个样本出现的概率就是他们各自出现的概率相乘):
那最大似然法就是求模型中使得似然函数最大的系数取值θ*。这个最大似然就是我们的代价函数(cost function)了。
OK,那代价函数有了,我们下一步要做的就是优化求解了。我们先尝试对上面的代价函数求导,看导数为0的时候可不可以解出来,也就是有没有解析解,有这个解的时候,就皆大欢喜了,一步到位。如果没有就需要通过迭代了,耗时耗力。
我们先变换下L(θ):取自然对数,然后化简(不要看到一堆公式就害怕哦,很简单的哦,只需要耐心一点点,自己动手推推就知道了。注:有xi的时候,表示它是第i个样本,下面没有做区分了,相信你的眼睛是雪亮的),得到:
这时候,用L(θ)对θ求导,得到:
bae2
然后我们令该导数为0,你会很失望的发现,它无法解析求解。不信你就去尝试一下。所以没办法了,只能借助高大上的迭代来搞定了。这里选用了经典的梯度下降算法。
Tensorflow下的逻辑回归模型实例:
Python2.7+Tensorflow1.0
# -*- coding: utf-8 -*- ''' A logistic regression learning algorithm example using TensorFlow library. This example is using the MNIST database of handwritten digits (http://yann.lecun.com/exdb/mnist/) Author: Aymeric Damien Project: https://github.com/aymericdamien/TensorFlow-Examples/ ''' from __future__ import print_function import tensorflow as tf # Import MNIST data(下载数据) from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("/tmp/data/", one_hot=True) # 参数:学习率,训练次数, learning_rate = 0.01 training_epochs = 25 batch_size = 100 display_step = 1 # tf Graph Input x = tf.placeholder(tf.float32, [None, 784]) # mnist data image of shape 28*28=784 y = tf.placeholder(tf.float32, [None, 10]) # 0-9 digits recognition => 10 classes # Set model weights W = tf.Variable(tf.zeros([784, 10])) b = tf.Variable(tf.zeros([10])) # softmax模型 pred = tf.nn.softmax(tf.matmul(x, W) + b) # Softmax # Minimize error using cross entropy(损失函数用cross entropy) cost = tf.reduce_mean(-tf.reduce_sum(y*tf.log(pred), reduction_indices=1)) # Gradient Descent(梯度下降优化) optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost) # Initializing the variables init = tf.global_variables_initializer() # Launch the graph with tf.Session() as sess: sess.run(init) # Training cycle for epoch in range(training_epochs): avg_cost = 0. total_batch = int(mnist.train.num_examples/batch_size) # Loop over all batches for i in range(total_batch): batch_xs, batch_ys = mnist.train.next_batch(batch_size) # Run optimization op (backprop) and cost op (to get loss value) _, c = sess.run([optimizer, cost], feed_dict={x: batch_xs, y: batch_ys}) # Compute average loss avg_cost += c / total_batch # Display logs per epoch step if (epoch+1) % display_step == 0: print("Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format(avg_cost)) print("Optimization Finished!") # Test model correct_prediction = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1)) # Calculate accuracy accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) print("Accuracy:", accuracy.eval({x: mnist.test.images, y: mnist.test.labels}))

相关文章推荐
- tensorflow学习笔记四:mnist实例--用简单的神经网络来训练和测试(MNIST For ML Beginners)
- Tensorflow实例:实现简单的卷积神经网络
- 基于tensorflow的神经网络简单实例
- tensorflow学习笔记四:mnist实例--用简单的神经网络来训练和测试
- TensorFlow下进行MNIST手写数字识别实例,从最简单的两层到LeNet5
- TensorFlow简单实例(一):linear_regression
- tensorflow 学习笔记(四) - mnist实例--用简单的神经网络来训练和测试
- tensorflow-简单实例1
- 基于tensorflow的简单线性回归实例
- Tensorflow的一个简单实例,线性回归
- tensorflow学习笔记四:mnist实例--用简单的神经网络来训练和测试
- Tensorflow学习笔记:模型训练数据的保存和恢复的简单实例
- TensorFlow简单实例(三):nearest_neighbor
- Jquery中把一段html代码动态写入到DIV中(简单实例)
- pig简单的代码实例:报表统计行业中的点击和曝光量
- 实例学习SSIS(一)-- 制作一个简单的ETL包
- 简单触发器实例
- 简单的TCP通讯实例
- 手动建立makefile简单实例解析
- struts2+ajax简单实例