数据预处理的几个方法:白化、去均值、归一化、PCA
2017-12-01 11:25
405 查看
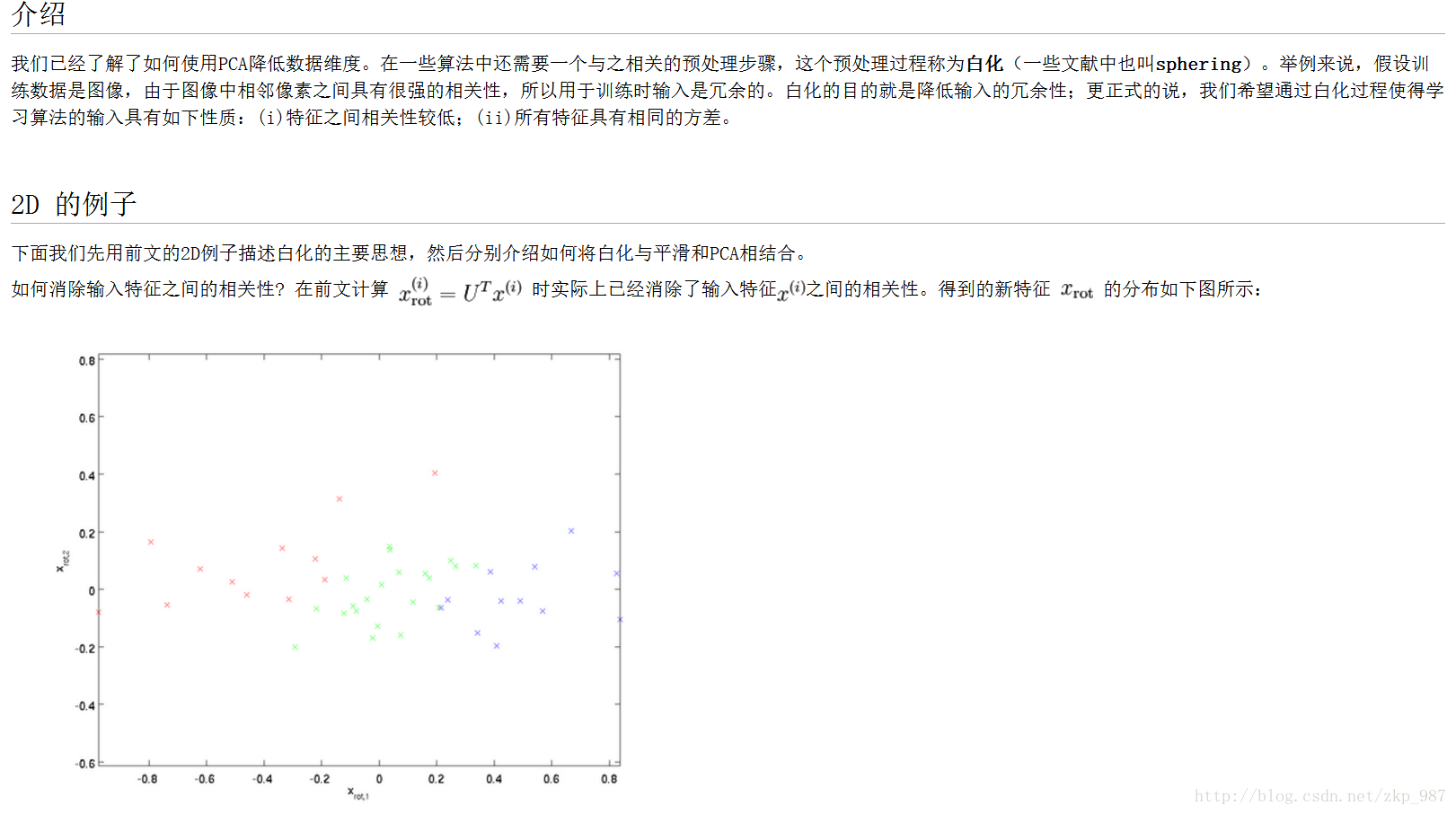


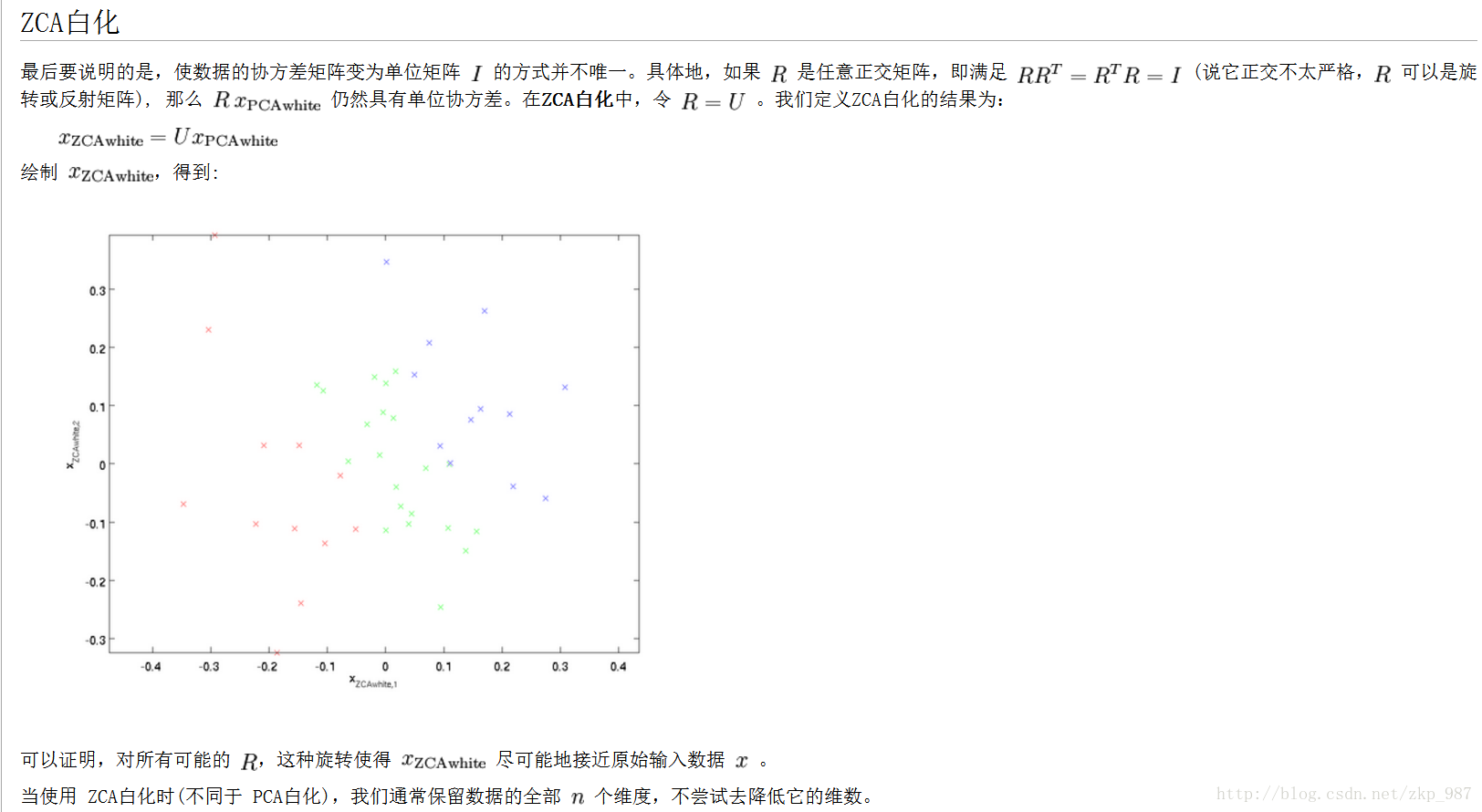
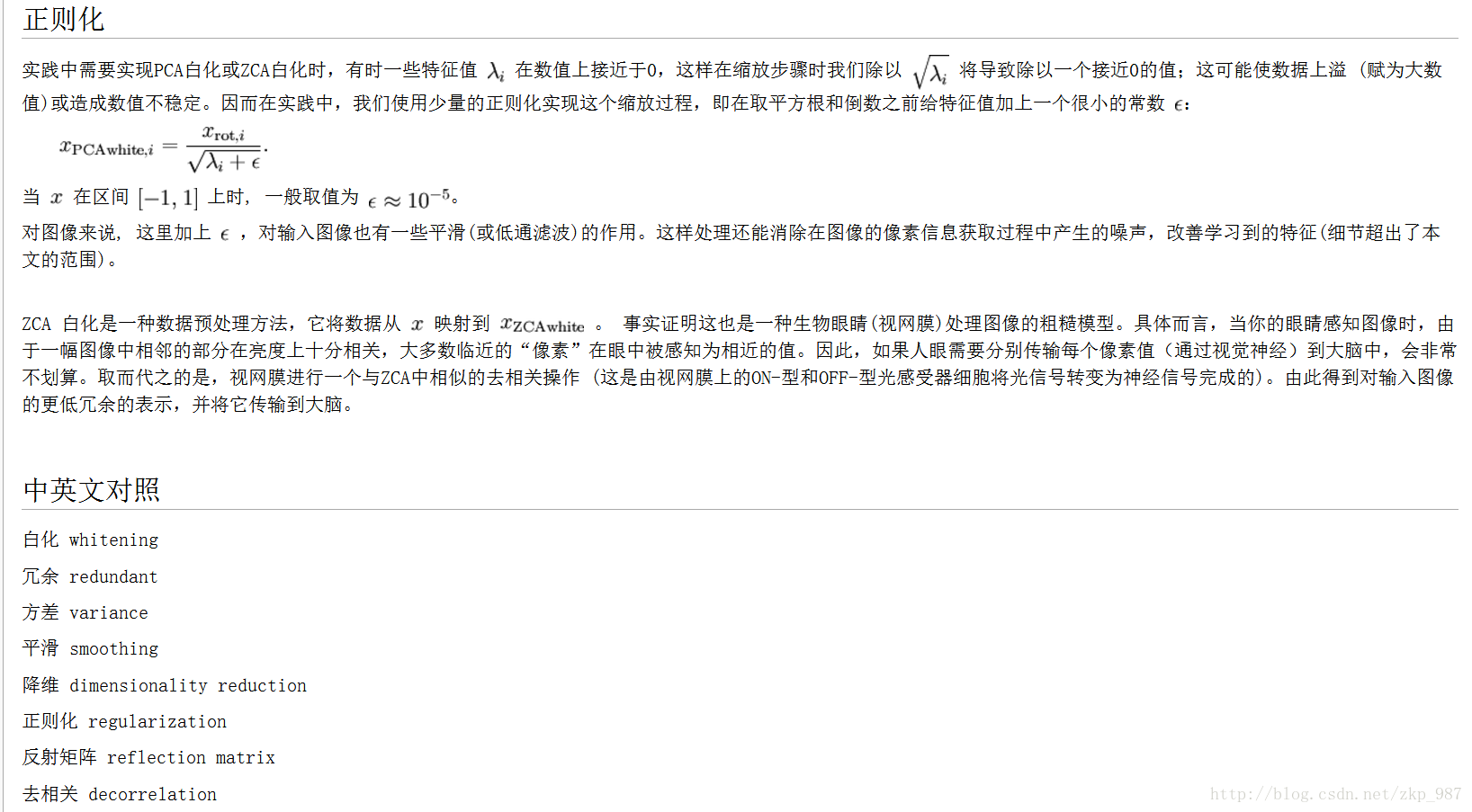
以上转载自:http://ufldl.stanford.edu/wiki/index.php/%E7%99%BD%E5%8C%96
假定数据表示成矩阵为X,其中我们假定X是[N*D]维矩阵(N是样本数据量,D为单张图片的数据向量长度)。
去均值,这是最常见的图片数据预处理,简单说来,它做的事情就是,对待训练的每一张图片的特征,都减去全部训练集图片的特征均值,这么做的直观意义就是,我们把输入数据各个维度的数据都中心化到0了。这么做的目的是减小计算量,把数据从原先的标准坐标系下的一个个向量组成的矩阵,变成以这些向量的均值为原点建立的坐标系,使用python的numpy工具包,这一步可以用X -= np.mean(X, axis = 0)轻松实现。
归一化,归一化的直观理解含义是,我们做一些工作去保证所有的维度上数据都在一个变化幅度上。通常我们有两种方法来实现归一化。一个是在数据都去均值之后,每个维度上的数据都除以这个维度上数据的标准差(X /= np.std(X, axis = 0))。 另外一种方式是我们除以数据绝对值最大值,以保证所有的数据归一化后都在-1到1之间。多说一句,其实在任何你觉得各维度幅度变化非常大的数据集上,你都 可以考虑归一化处理。不过对于图像而言,其实这一步反倒可做可不做,像素的值变化区间都在[0,255]之间,所以其实图像输入数据天生幅度就是一致的。
PCA和白化/whitening,这是另外一种形式的数据预处理。在经过去均值操作之后,我们可以计算数据的协方差矩阵,从而可以知道数据各个维度之间的相关性,简单示例代码如下:
假定输入数据矩阵X是[N*D]维的
X -= np.mean(X, axis = 0) # 去均值
cov = np.dot(X.T, X) / X.shape[0] # 计算协方差
得到的结果矩阵中元素(i,j)表示原始数据中,第i维和第j维的相关性。有意思的是,其实协方差矩阵的对角线包含了每个维度的变化幅度。另外,我们都知道协方差矩阵是对称的,我们可以在其上做矩阵奇异值分解(SVD factorization):
U,S,V = np.linalg.svd(cov)
其中U为特征向量,我们如果相对原始数据(去均值之后)去做相关操作,只需要进行如下运算:
Xrot = np.dot(X, U)
这么理解一下可能更好,U是一组正交基向量。所以我们可以看做把原始数据X投射到这组维度保持不变的正交基底上,从而也就完成了对原始数据的去相关。如果去相关之后你再求一下Xrot的协方差矩阵,你会发现这时候的协方差矩阵是一个对角矩阵了。而numpy中的np.linalg.svd更好的一个特性是,它返回的U是对特征值排序过的,这也就意味着,我们可以用它进行降维操作。我们可以只取top的一些特征向量,然后做和原始数据做矩阵乘法,这个时候既降维减少了计算量,同时又保存下了绝大多数的原始数据信息,这就是所谓的主成分分析/PCA:
Xrot_reduced = np.dot(X, U[:,:100])
这个操作之后,我们把原始数据集矩阵从[N*D]降维到[N*100],保存了前100个能包含绝大多数数据信息的维度。实际应用中,你在PCA降维之后的数据集上,做各种机器学习的训练,在节省空间和时间的前提下,依旧能有很好的训练准确度。
最后再提一下whitening操作。所谓whitening,就是把各个特征轴上的数据除以对应特征值, 从而达到在每个特征轴上都归一化幅度的结果。whitening变换的几何意义和理解是,如果输入的数据是多变量高斯,那whitening之后的 数据是一个均值为0而不同方差的高斯矩阵。这一步简单代码实现如下:
白化数据
Xwhite = Xrot / np.sqrt(S + 1e-5)
提个醒:whitening操作会有严重化噪声的可能。注意到我们在上述代码中,分母的部分加入了一个很小的数1e-5,以防止出现除以0的情况。 但是数据中的噪声部分可能会因whitening操作而变大,因为whitening操作的本质是把输入的每个维度都拉到差不多的幅度,那么本不相关的有微弱幅度变化的 噪声维度,也被拉到了和其他维度同样的幅度。当然,我们适当提高分母中的安全因子(1e-5)可以在一定程度上缓解这个问题。
下面给出图示:
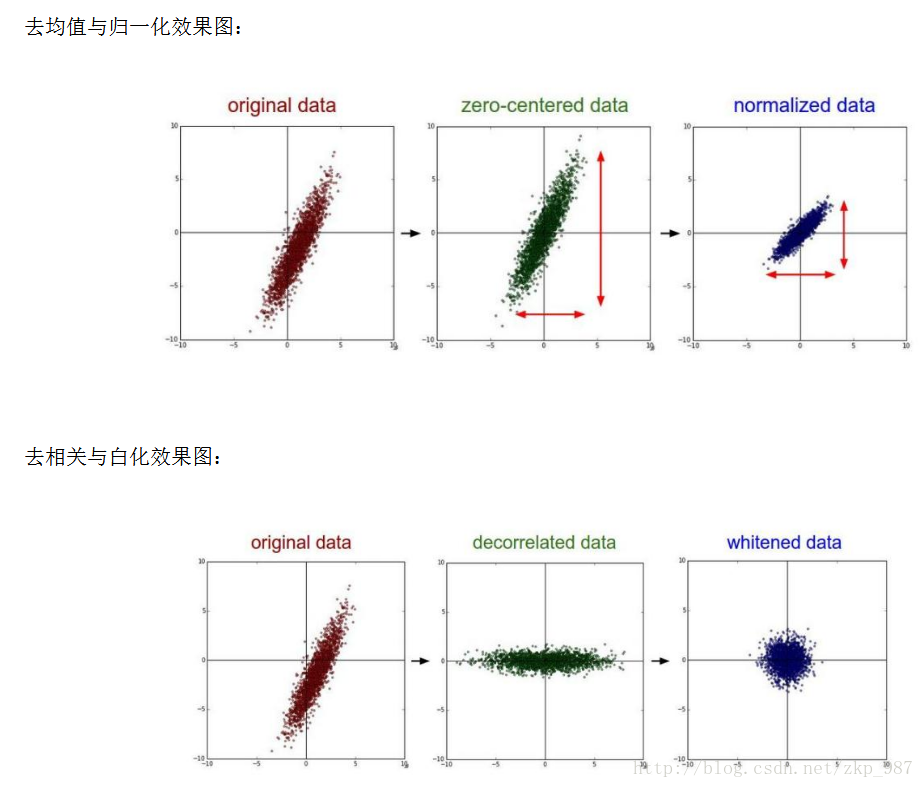

相关文章推荐
- 神经网络基本原理-4.3数据预处理(零中心化+归一化+PCA+白化)
- (Python实现)数据PCA降维白化和L2归一化-深度学习实践常用数据预处理
- [ 转]数据归一化和两种常用的归一化方法:极小极大标准化,0均值1标准差标准化
- 斯坦福大学深度学习公开课cs231n学习笔记(6)神经网路输入数据预处理(归一化,PCA等)及参数初始化
- 机器学习数据预处理方法与技巧系统讲解
- 几个复制表结构和表数据的方法
- 【机器学习】【数据预处理】数据的规范化,归一化,标准化,正则化
- 机器学习数据预处理方法与技巧系统讲解
- 数据分析中的降维方法-PCA
- 数据归一化和两种常用的归一化方法
- excel导入数据库:SQL Server数据库中成批导入数据的几个常用方法
- SQL Server中删除重复数据的几个方法
- php+mysqli预处理技术实现添加、修改及删除多条数据的方法
- c# -- mysql中的读取数据的几个方法
- 数据预处理(方法介绍)
- HttpClient 4使用方法的几个例子(代理,StringEntity字符串数据,文件上传)(转载)
- C# CAD二次开发 扩展数据的几个重要方法
- 深度学习中的数据预处理方法
- [转帖]记录:删除数据库中重复数据的几个方法
- Python数据预处理—归一化,标准化,正则化