Hadoop体系的介绍
2017-11-28 20:39
148 查看
引言
大数据的处理:
收集、整合、清洗、储存、计算、结果可视化、系统运维
全栈工程师:
后台(代码开发+系统运维)+前台(前端)+产品需求和文档整理
大数据岗位出现了明显的分化:
1、大数据开发工程师
hadoop工程师、spark工程师、算法工程师
2、大数据可视化工程师
之前的前段进化(数据分析)
3、大数据的运维
系统的运维、集群的运维
4、大数据的处理技术体系
hadoop hadoop生态体系 以hadoop为主的一整个离线处理的技术栈
storm 实时的流计算框架 类似于队列思维的消息缓存组件
spark 特别火 spark技术栈
1、Hadoop快速入门
1.1、数据:
数据可以是连续的值,如声音、图像,称为模拟数据。
数据也可以是离散的,如符号、文字,称为数字数据。
1.2、大数据:
1.2.1、概念:
指的是传统数据处理应用软件不足以处理(存储和计算)他们的大而复杂的数据集。
最基本的衡量:大小

1.2.2、大数据特点:
容量大、种类多、速度快、价值高
1.3、Hadoop
1.3.1、介绍
hadoop是Apache旗下的一套开源软件平台
1.3.2、功能
利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理
1.3.3、核心组件
Common(基础功能组件)(工具包,RPC框架)JNDI和PRC
HDFS(Hadoop Distributed File System分布式文件系统)
YARN(Yet Another Resources Negotiator运算资源调度系统)
MapReduce(Map和Reduce分布式运算编程框架)
1.4、Hadoop在大数据和云计算当中的位置关系
云计算的两大底层支撑技术为:“虚拟化”和“大数据技术”
1.5、Hadoop技术应用架构概览
1.5.1、Hadoop应用于数据服务基础平台建设
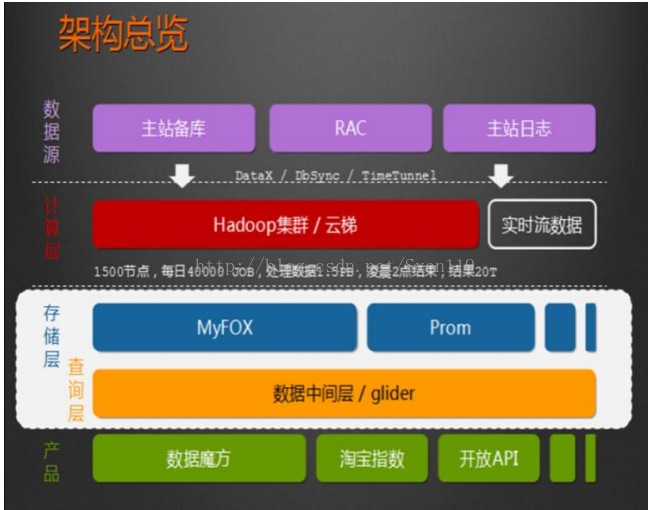
1.5.2、用户画像
1.5.3、hadoop用于网站点击流量数据挖掘
金融行业:个人征信分析
证券行业:投资模型分析
交通行业:车辆、路况监控分析
电信行业:用户上网行为分析
电商行业:用户浏览、购买行为分析
hadoop 并不会跟某个具体的行业或者某个具体的业务挂钩,它只是一种用来做海量数据分析处理的工具。
1.6、hadoop生态圈以及各组成部分的简介
重点组件:
HDFS:hadoop的分布式文件存储系统
MapReduce:Hadoop的分布式程序运算框架,也可以叫做一种编程模型
Hive:基于hadoop的类sql数据仓库工具
HBase:基于hadoop的列式分布式NoSQL数据库
ZooKeeper:分布式协调服务组件
Mahout:基于MapReduce/Flink/Spark等分布式运算框架的机器学习算法库
Oozie/Azkaban:工作流调度引擎
Spoop:数据迁入迁出工具
Flume:日志采集工具
2、分布式系统概述
集群+负载均衡
分布式:
1、该软件系统会划分成多个子系统或模块,各自运行在不同的机器上,子系统或模块之间通过网络通信进行协作,实现最终的整体功能
2、比如分布式操作系统、分布式程序设计语言及其编译(解释)系统、分布式文件系统和分布式数据库系统等。
利用多个节点共同协作完成一项或多项具体业务功能的系统是分布式系统。
3、离线分析系统结构概述
web日志数据挖掘:
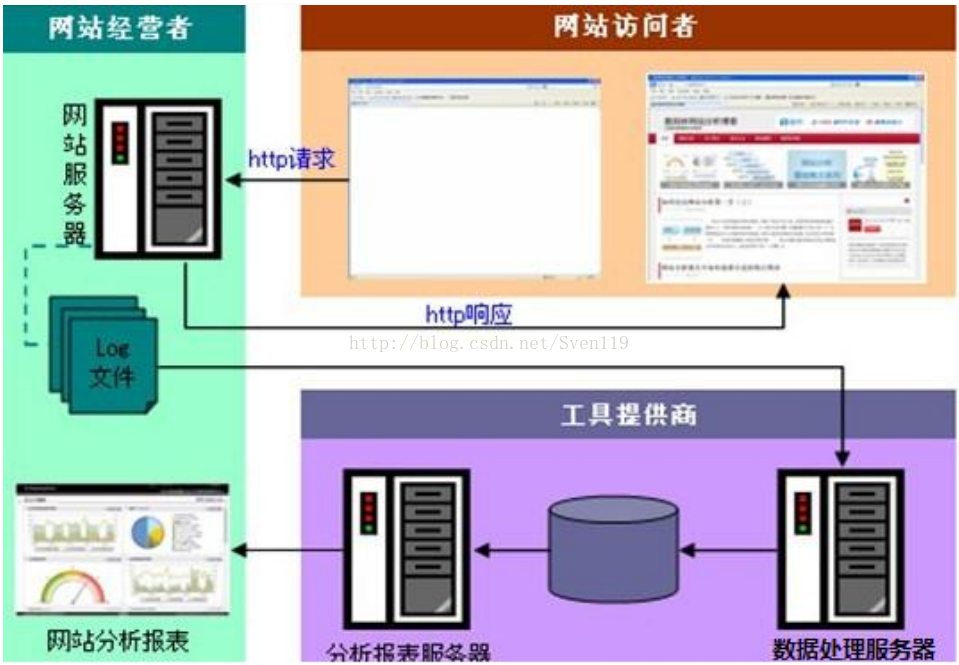
数据处理流程:

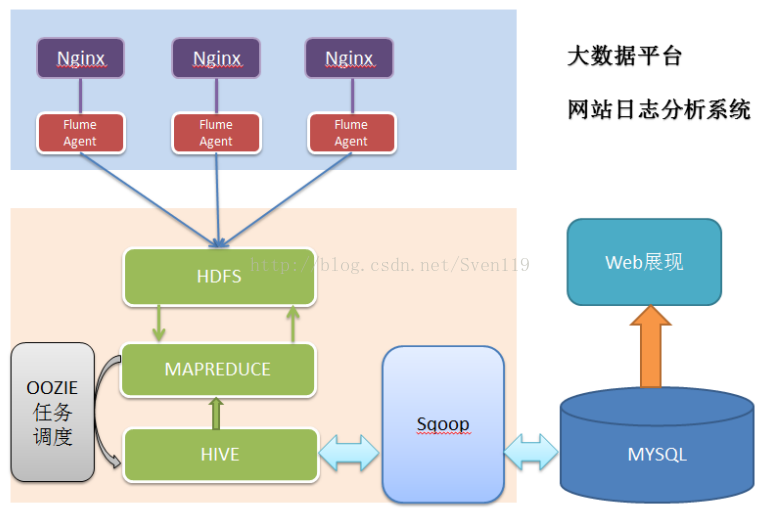
项目整体技术架构图:
大数据的处理:
收集、整合、清洗、储存、计算、结果可视化、系统运维
全栈工程师:
后台(代码开发+系统运维)+前台(前端)+产品需求和文档整理
大数据岗位出现了明显的分化:
1、大数据开发工程师
hadoop工程师、spark工程师、算法工程师
2、大数据可视化工程师
之前的前段进化(数据分析)
3、大数据的运维
系统的运维、集群的运维
4、大数据的处理技术体系
hadoop hadoop生态体系 以hadoop为主的一整个离线处理的技术栈
storm 实时的流计算框架 类似于队列思维的消息缓存组件
spark 特别火 spark技术栈
1、Hadoop快速入门
1.1、数据:
数据可以是连续的值,如声音、图像,称为模拟数据。
数据也可以是离散的,如符号、文字,称为数字数据。
1.2、大数据:
1.2.1、概念:
指的是传统数据处理应用软件不足以处理(存储和计算)他们的大而复杂的数据集。
最基本的衡量:大小
1.2.2、大数据特点:
容量大、种类多、速度快、价值高
1.3、Hadoop
1.3.1、介绍
hadoop是Apache旗下的一套开源软件平台
1.3.2、功能
利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理
1.3.3、核心组件
Common(基础功能组件)(工具包,RPC框架)JNDI和PRC
HDFS(Hadoop Distributed File System分布式文件系统)
YARN(Yet Another Resources Negotiator运算资源调度系统)
MapReduce(Map和Reduce分布式运算编程框架)
1.4、Hadoop在大数据和云计算当中的位置关系
云计算的两大底层支撑技术为:“虚拟化”和“大数据技术”
1.5、Hadoop技术应用架构概览
1.5.1、Hadoop应用于数据服务基础平台建设
1.5.2、用户画像
1.5.3、hadoop用于网站点击流量数据挖掘
金融行业:个人征信分析
证券行业:投资模型分析
交通行业:车辆、路况监控分析
电信行业:用户上网行为分析
电商行业:用户浏览、购买行为分析
hadoop 并不会跟某个具体的行业或者某个具体的业务挂钩,它只是一种用来做海量数据分析处理的工具。
1.6、hadoop生态圈以及各组成部分的简介
重点组件:
HDFS:hadoop的分布式文件存储系统
MapReduce:Hadoop的分布式程序运算框架,也可以叫做一种编程模型
Hive:基于hadoop的类sql数据仓库工具
HBase:基于hadoop的列式分布式NoSQL数据库
ZooKeeper:分布式协调服务组件
Mahout:基于MapReduce/Flink/Spark等分布式运算框架的机器学习算法库
Oozie/Azkaban:工作流调度引擎
Spoop:数据迁入迁出工具
Flume:日志采集工具
2、分布式系统概述
集群+负载均衡
分布式:
1、该软件系统会划分成多个子系统或模块,各自运行在不同的机器上,子系统或模块之间通过网络通信进行协作,实现最终的整体功能
2、比如分布式操作系统、分布式程序设计语言及其编译(解释)系统、分布式文件系统和分布式数据库系统等。
利用多个节点共同协作完成一项或多项具体业务功能的系统是分布式系统。
3、离线分析系统结构概述
web日志数据挖掘:
数据处理流程:
项目整体技术架构图:

相关文章推荐
- hadoop 体系介绍
- 第1周 Hadoop的源起与体系介绍
- Hadoop学习系列(2.Hadoop框架介绍与搜索技术体系介绍)
- Alex 的 Hadoop 菜鸟教程: 第1课 hadoop体系介绍
- 从零学习Hadoop--001Hadoop的起源与体系介绍
- Hadoop体系介绍
- hadoop的源起与体系介绍
- Hadoop体系介绍
- hadoop学习笔记1(Hadoop的源起与体系介绍)
- Hadoop的起源和体系介绍
- Hadoop的源起与体系介绍
- hadoop介绍和体系架构
- Hadoop学习笔记:(1)Hadoop体系介绍
- 第五十九课 Hadoop入门介绍
- Hadoop集群虚拟机网卡的介绍和配置
- Hadoop 1.x 服务介绍
- 面向服务的体系结构(SOA) 之 ESB介绍及职责
- Hadoop生态系统介绍
- 服务器三大体系SMP、NUMA、MPP介绍