Hadoop学习笔记:(1)Hadoop体系介绍
2018-03-07 14:59
232 查看
Hadoop是一个能对大量数据进行分布式处理的软件框架。使得开发人员在不了解底层分布式细节的情况下,开发分布式程序。利用集群的特长进行高速运算和存储。
分布式系统是一组通过网络进行通信,为了完成共同的任务为协调工作的计算机节点组成的系统。目的是利用更多的机器,更多更快的处理和存储数据。分布式和集群的差别在于集群中每个节点是相似的,提供相似的功能,而分布式是把任务分为多个子任务,并把子任务分布在不同机器上。
Hadoop2框架如下图:
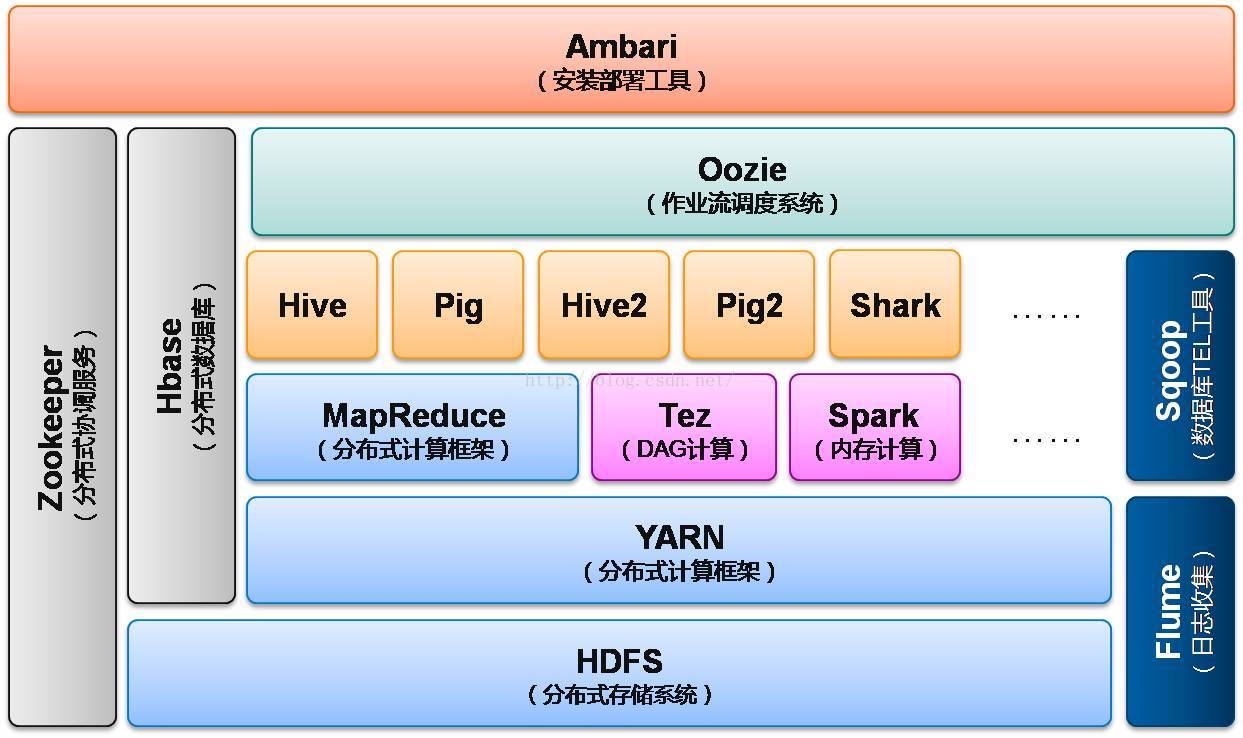
Hadoop的核心架构主要包括组件:
HDFS:Hadoop Distributed File System分布式文件系统,主要存储Hadoop集群中各存储节点存储的数据;
MapReduce:处理大量半结构化数据集合的编程模型,先将输入流分片,然后将分片数据交给map()处理,最后将map()处理结果交给Reduce()汇总输出;
YARN:分布式计算框架,包含三个组件(1)Resource Manager:负责全局资源分配管理 (2)Node Manager:每台机器的代理,监控应用程序的资源应用情况,并汇报给Resorce Manager。 (3)Application Master:负责当前节点的调度;
Tez:分布式计算框架,将Map和Reduce进一步拆分,拆分后的元操作任意灵活组合,形成一个大的DAG作业;
Spark:内存计算框架,与MapReduce的持久存储相比,Spark使用弹性分布式数据集,确保数据实时处理;
HBase:构建在HDFS系统上的分布式、面向列的存储系统。不是关系型数据库,不支持SQL;
ZooKeeper:分布式协调服务,主要实现数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master选举、分布式锁和分布式队列等功能;
Flume:一个高可靠、高可用的开源分布式海量日志收集系统,日志数据可以通过Flume流向存储终端目的地;
Sqoop:数据库TEL工具,主要用于Hadoop(Hive)和传统型数据库(mysql等)的数据传递;
Hive:数据仓库工具,将结构化的文件映射成一张数据库表,提供查询功能;
Pig:操作Hadoop的轻量级脚本语言,用来并行的处理数据流的引擎;
Shark:Spark和Hive之上的SQL查询引擎;
Oozie:管理Hadoop作业的工作流调度系统
Ambari:主要用于创建、管理、监控Hadoop(泛指Hadoop生态圈)的集群。
Hadoop的特点是:
1:容错性:假设计算和存储会出现失败,所以维护多个工作数据副本,确保出现失败后针对这类的节点重新进行分布式处理;
2:高效性:以并行处理,所以速度快,并且可以在节点间动态的平衡数据;
3:可伸缩:可以处理PB级数据(1PB = 1000 TB);
4:可靠性:按位存储和计算数据;
5:低成本:可以部署在低廉的硬件上。
下面重点介绍一下HDFS、MapReduce和HBase,这三个组件是当前项目正在用到的,其他的组件后面补充:
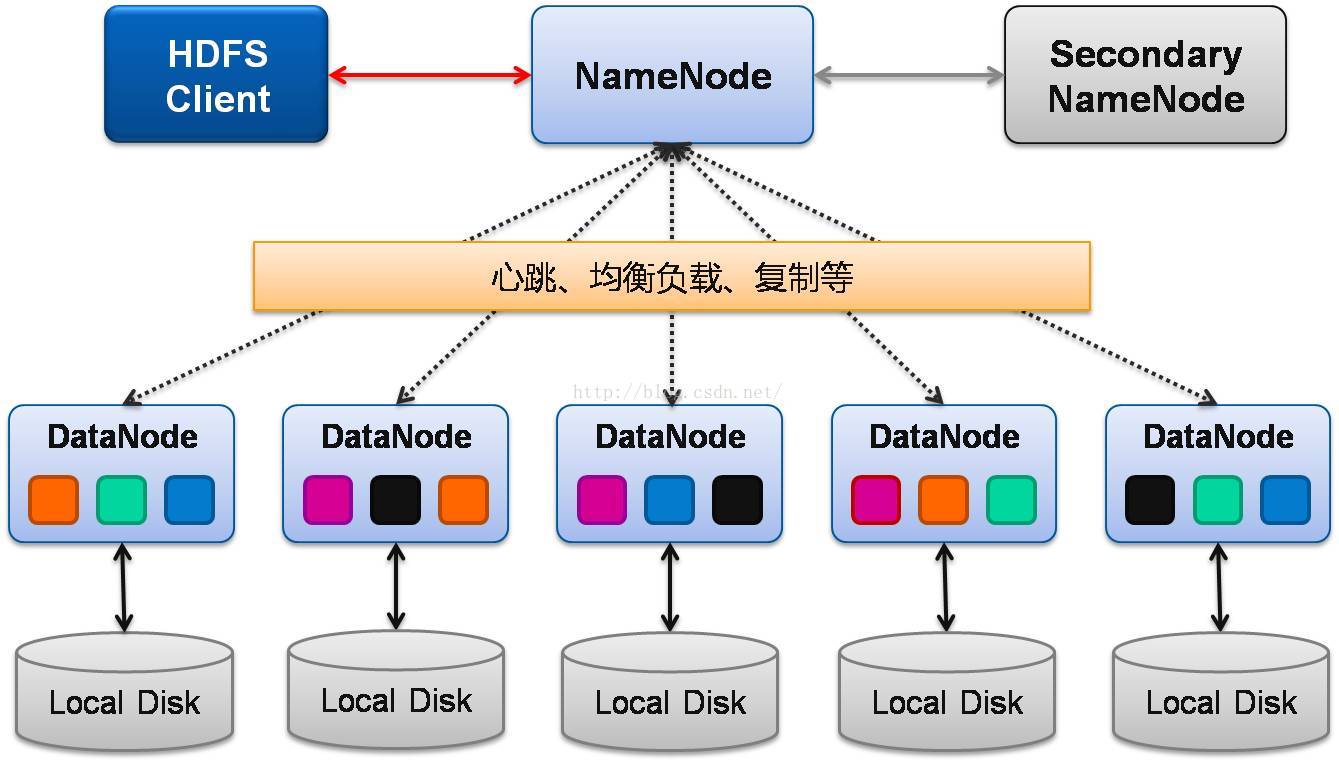
《1》HDFS主要包括组件:
一个NameNode来提供内部元数据服务,可以操作所有文件数据,因为只有一个NameNode节点,固容易单点失败;
一个Secondary NameNode:主要和NameNode进行通讯,周期性的保存NameNode的元数据快照,当NameNode节点挂掉,可以手动的设置Secondary NameNode 替换NameNode;
N个DataNode存储块,HDFS中数据以块为单位存储,然后将这些复制到多个计算机(DataNode)中,块大小和快复制数量由客户机决定:
一个HDFS Client:管理和访问HDFS系统。
其中DataNode会周期性的发送心跳包给NameNode,包括当前节点的运行状态和存储情况;HDFS按快存储,为了实现容错性,NameNode会复制多个数据副本到其他节点,为避免节点数据存储不均衡,NameNode会根据策略,均衡负载。
《2》HDFS的优点:容错性:数据自动保存多个副本,副本丢失后会自动恢复;
适合批处理:移动计算而非移动数据,会把数据的存储位置暴露给计算框架;
高吞吐量:适合大数据的处理,可以处理PB级别的数据;
流式文件访问:一次写入,多次读写,保证数据的一致性;
可以部署在低廉的硬件上。
《3》HDFS的缺点:
不适合延迟数据访问:为达到高的数据吞吐量,以高延迟作为代价;
无法高效存储大量小文件:对小文件进行压缩处理,例如将一万个小文件压缩到一起存储;
不支持多用户写入和任意修改文件:一个文件只有一个写入者,不能修改文件,只能在文件底部追加。
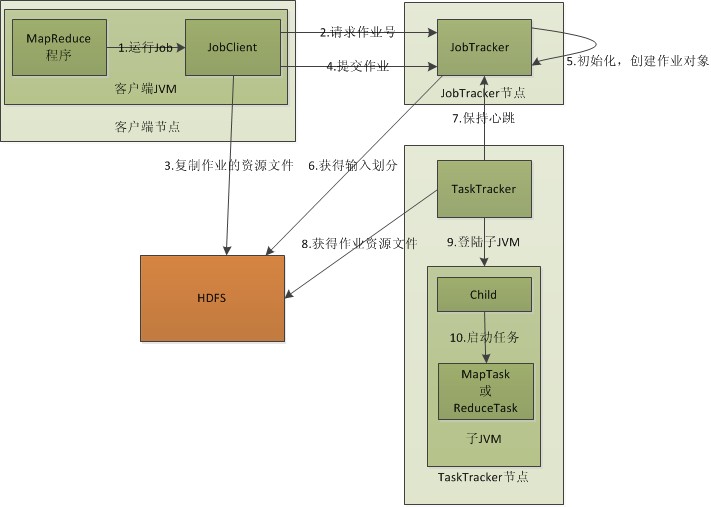
MapReduce中有两个发挥重要作用的线程:
JobTracker:主线程,主要作用是作业控制和资源管理,可以类比于HDFS的NameNode;
TaskTracker:主要是执行子任务,并向JobTracker汇报心跳,可以类比于HDFS的DataNode。
MapReduce的主要工作流程:
JobClient接收到作业后,先向JobTracker申请JobId,申请到JobId后JobClient将作业运行中需要的资源文件复制到HDFS上,并将作业提交给JobTracker;
JobTracker接收到作业后将作业放入作业队列等待调度,当调度到该作业时,会根据数据划分信息,为每个分片创建Map任务,并将Map任务分配给TaskTracker执行;
Map任务主要是处理分片的数据,Reduce任务主要是将Map任务的处理结果汇总输出到磁盘;
TaskTracker周期向JobTracker发送心跳,告诉它自己还在运行,心跳包还包括了map任务完成的进度等信息;
运行的TaskTracker从HDFS中获取运行中需要的资源,获得资源后启动新的JVM虚拟机运行任务;
MapReduce的核心函数Map和Reduce
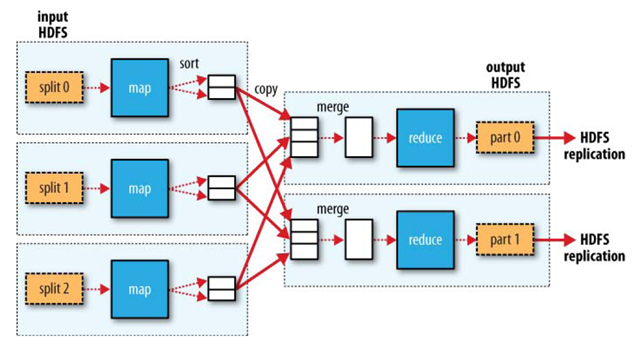
(1)Map函数:每个输入分片会让一个Map任务来处理,处理结果暂时放在环形缓冲区中,溢出后交给Reduce。分而治之;
(2)Reduce函数:接收Map任务的处理结果,汇总后输出到HDFS。
MapReduce和YARN
MapReduce中JobTracker是单节点,容易出现单节点故障,并且当要处理的任务过多时会有很大的内存开销;TaskTracker部分,当两个大内存消耗任务一起调度,会出现内存泄露的问题,但当只有Map任务和Reduce任务时,会出现资源浪费。
Yarn为了解决这个问题,将JobTracker的两个任务“作业控制”和“资源管理”分开,各司其职,减少了JobTracker的压力。Yarn主要包含三个组件:
Resource Manager:负责全局资源分配;
Node Manager:每台机器的代理,监控应用程序的资源使用情况,并汇报给Resource Manager;
Application Master:每个节点一个,负责当前节点的调度。
《1》HBase的数据模型

HBase是聚合行数据库,在建表的时候只用声明列簇,不用说明具体的列,列可以再后面在新增修改删除。HBase的一张表的数据类似于Java中的Map,value里面又嵌套map,这样就能做到保存比较复杂的数据结构。HBase表结构主要包括下面的名词:
RowKey:是用来检索记录的主键
列簇:HBase 表中的每个列都归属于某个列簇。列簇是表的 Schema 的一部分(而列不是),必须在使用表之前定义。列名都以列簇作为前缀,例如 courses:history、courses:math 都属于 courses 这个列簇。
Cell:HBase 中通过 Row 和 Columns 确定的一个存储单元称为 Cell,Cell 中的数据是没有类型的,全部是字节码形式存储;
时间戳:每个 Cell 都保存着同一份数据的多个版本。 版本通过时间戳来索引,时间戳的类型是 64 位整型。时间戳可以由HBase赋值,也可由客户赋值,不同版本的数据按照时间倒序排序。
HBase最主要的不同是面向列,查询中的选择规则是通过列来定义的,因此整个数据库是自动索引化的。按列存储每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量,一个字段的数据聚集存储,那就更容易为这种聚集存储设计更好的压缩/解压算法。和传统关系型数据库的差别主要如下图:
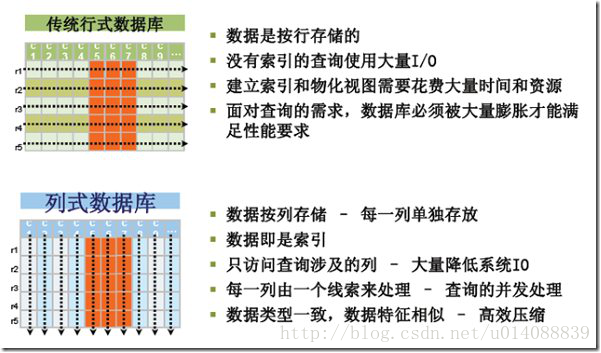
《2》HBase数据库结构

HBase是由三种类型的服务器以主从模式构成的。由以下类型节点组成:HMaster节点、HRegionServer节点、ZooKeeper集群,而在底层,它将数据存储于HDFS中,因而涉及到HDFS的NameNode、DataNode等。
1、HBase Client:HBase客户端,通过RPC方式和HMaster、HRegionServer通信;
2、HMaster节点:管理HRegionServer和HRegion,数据库的创建和删除等操作;
3、HRegionServer:负责数据的读写服务,通过其实现数据的访问,是根据DataNode分布的;
4、ZooKeeper集群:协调系统,存放整个 HBase集群的元数据以及集群的状态信息,实现HMaster主从节点的失效备援;
5、HRegion:HBase使用RowKey将表水平切割成多个HRegion,从HMaster的角度,每个HRegion都纪录了它的StartKey和EndKey。每个HRegion分散在不同的RegionServer中。
《3》HBase的特点
1、存储大:一个表可以有上亿行,上百万列。
2、面向列:面向列表(簇)的存储和权限控制,列(簇)独立检索。
3、稀疏:对于为NULL的列,并不占用存储空间,表可以设计的非常稀疏。
4、无模式:每一行都有一个可以排序的主键和任意多的列,列可以根据需要动态增加,同一张表中不同的行可以有截然不同的列。
5、数据多版本:每个单元中的数据可以有多个版本,默认情况下,版本号自动分配,版本号就是单元格插入时的时间戳Timestamp。
6、数据类型单一:HBase中的数据都是字符串类型,没有其他选择。
参考文档:
(1)http://blog.csdn.net/babyfish13/article/details/52527665;
(2)https://www.cnblogs.com/kubixuesheng/p/5525306.html;
(3)https://baike.baidu.com/item/Hadoop/3526507?fr=aladdin#3_1;
(4)http://www.blogjava.net/DLevin/archive/2015/08/22/426877.html
分布式系统是一组通过网络进行通信,为了完成共同的任务为协调工作的计算机节点组成的系统。目的是利用更多的机器,更多更快的处理和存储数据。分布式和集群的差别在于集群中每个节点是相似的,提供相似的功能,而分布式是把任务分为多个子任务,并把子任务分布在不同机器上。
Hadoop2框架如下图:
Hadoop的核心架构主要包括组件:
HDFS:Hadoop Distributed File System分布式文件系统,主要存储Hadoop集群中各存储节点存储的数据;
MapReduce:处理大量半结构化数据集合的编程模型,先将输入流分片,然后将分片数据交给map()处理,最后将map()处理结果交给Reduce()汇总输出;
YARN:分布式计算框架,包含三个组件(1)Resource Manager:负责全局资源分配管理 (2)Node Manager:每台机器的代理,监控应用程序的资源应用情况,并汇报给Resorce Manager。 (3)Application Master:负责当前节点的调度;
Tez:分布式计算框架,将Map和Reduce进一步拆分,拆分后的元操作任意灵活组合,形成一个大的DAG作业;
Spark:内存计算框架,与MapReduce的持久存储相比,Spark使用弹性分布式数据集,确保数据实时处理;
HBase:构建在HDFS系统上的分布式、面向列的存储系统。不是关系型数据库,不支持SQL;
ZooKeeper:分布式协调服务,主要实现数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master选举、分布式锁和分布式队列等功能;
Flume:一个高可靠、高可用的开源分布式海量日志收集系统,日志数据可以通过Flume流向存储终端目的地;
Sqoop:数据库TEL工具,主要用于Hadoop(Hive)和传统型数据库(mysql等)的数据传递;
Hive:数据仓库工具,将结构化的文件映射成一张数据库表,提供查询功能;
Pig:操作Hadoop的轻量级脚本语言,用来并行的处理数据流的引擎;
Shark:Spark和Hive之上的SQL查询引擎;
Oozie:管理Hadoop作业的工作流调度系统
Ambari:主要用于创建、管理、监控Hadoop(泛指Hadoop生态圈)的集群。
Hadoop的特点是:
1:容错性:假设计算和存储会出现失败,所以维护多个工作数据副本,确保出现失败后针对这类的节点重新进行分布式处理;
2:高效性:以并行处理,所以速度快,并且可以在节点间动态的平衡数据;
3:可伸缩:可以处理PB级数据(1PB = 1000 TB);
4:可靠性:按位存储和计算数据;
5:低成本:可以部署在低廉的硬件上。
下面重点介绍一下HDFS、MapReduce和HBase,这三个组件是当前项目正在用到的,其他的组件后面补充:
一:Hadoop核心组件之HDFS
HDFS (分布式文件系统)和传统的分级文件系统一样,可以对数据进行增删改查、移动,重命名等,但是HDFS的架构是基于一组特定的节点的构建的。如下图:《1》HDFS主要包括组件:
一个NameNode来提供内部元数据服务,可以操作所有文件数据,因为只有一个NameNode节点,固容易单点失败;
一个Secondary NameNode:主要和NameNode进行通讯,周期性的保存NameNode的元数据快照,当NameNode节点挂掉,可以手动的设置Secondary NameNode 替换NameNode;
N个DataNode存储块,HDFS中数据以块为单位存储,然后将这些复制到多个计算机(DataNode)中,块大小和快复制数量由客户机决定:
一个HDFS Client:管理和访问HDFS系统。
其中DataNode会周期性的发送心跳包给NameNode,包括当前节点的运行状态和存储情况;HDFS按快存储,为了实现容错性,NameNode会复制多个数据副本到其他节点,为避免节点数据存储不均衡,NameNode会根据策略,均衡负载。
《2》HDFS的优点:容错性:数据自动保存多个副本,副本丢失后会自动恢复;
适合批处理:移动计算而非移动数据,会把数据的存储位置暴露给计算框架;
高吞吐量:适合大数据的处理,可以处理PB级别的数据;
流式文件访问:一次写入,多次读写,保证数据的一致性;
可以部署在低廉的硬件上。
《3》HDFS的缺点:
不适合延迟数据访问:为达到高的数据吞吐量,以高延迟作为代价;
无法高效存储大量小文件:对小文件进行压缩处理,例如将一万个小文件压缩到一起存储;
不支持多用户写入和任意修改文件:一个文件只有一个写入者,不能修改文件,只能在文件底部追加。
二:Hadoop核心组件之MapReduce
MapReduce是面向大数据并行处理的计算模型、框架和平台。借助函数式编程思想,用Map和Reduce两个函数编程实现基本的并行计算任务,提供抽象的操作和并行计算接口。MapReduce中有两个发挥重要作用的线程:
JobTracker:主线程,主要作用是作业控制和资源管理,可以类比于HDFS的NameNode;
TaskTracker:主要是执行子任务,并向JobTracker汇报心跳,可以类比于HDFS的DataNode。
MapReduce的主要工作流程:
JobClient接收到作业后,先向JobTracker申请JobId,申请到JobId后JobClient将作业运行中需要的资源文件复制到HDFS上,并将作业提交给JobTracker;
JobTracker接收到作业后将作业放入作业队列等待调度,当调度到该作业时,会根据数据划分信息,为每个分片创建Map任务,并将Map任务分配给TaskTracker执行;
Map任务主要是处理分片的数据,Reduce任务主要是将Map任务的处理结果汇总输出到磁盘;
TaskTracker周期向JobTracker发送心跳,告诉它自己还在运行,心跳包还包括了map任务完成的进度等信息;
运行的TaskTracker从HDFS中获取运行中需要的资源,获得资源后启动新的JVM虚拟机运行任务;
MapReduce的核心函数Map和Reduce
(1)Map函数:每个输入分片会让一个Map任务来处理,处理结果暂时放在环形缓冲区中,溢出后交给Reduce。分而治之;
(2)Reduce函数:接收Map任务的处理结果,汇总后输出到HDFS。
MapReduce和YARN
MapReduce中JobTracker是单节点,容易出现单节点故障,并且当要处理的任务过多时会有很大的内存开销;TaskTracker部分,当两个大内存消耗任务一起调度,会出现内存泄露的问题,但当只有Map任务和Reduce任务时,会出现资源浪费。
Yarn为了解决这个问题,将JobTracker的两个任务“作业控制”和“资源管理”分开,各司其职,减少了JobTracker的压力。Yarn主要包含三个组件:
Resource Manager:负责全局资源分配;
Node Manager:每台机器的代理,监控应用程序的资源使用情况,并汇报给Resource Manager;
Application Master:每个节点一个,负责当前节点的调度。
三、Hadoop核心组件之HBase
HBase是一种构建在HDFS之上的分布式、面向列的存储系统。在需要实时读写、随机访问超大规模数据集时,可以使用HBase。HBase不是关系型数据库,不支持SQL。《1》HBase的数据模型
HBase是聚合行数据库,在建表的时候只用声明列簇,不用说明具体的列,列可以再后面在新增修改删除。HBase的一张表的数据类似于Java中的Map,value里面又嵌套map,这样就能做到保存比较复杂的数据结构。HBase表结构主要包括下面的名词:
RowKey:是用来检索记录的主键
列簇:HBase 表中的每个列都归属于某个列簇。列簇是表的 Schema 的一部分(而列不是),必须在使用表之前定义。列名都以列簇作为前缀,例如 courses:history、courses:math 都属于 courses 这个列簇。
Cell:HBase 中通过 Row 和 Columns 确定的一个存储单元称为 Cell,Cell 中的数据是没有类型的,全部是字节码形式存储;
时间戳:每个 Cell 都保存着同一份数据的多个版本。 版本通过时间戳来索引,时间戳的类型是 64 位整型。时间戳可以由HBase赋值,也可由客户赋值,不同版本的数据按照时间倒序排序。
HBase最主要的不同是面向列,查询中的选择规则是通过列来定义的,因此整个数据库是自动索引化的。按列存储每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量,一个字段的数据聚集存储,那就更容易为这种聚集存储设计更好的压缩/解压算法。和传统关系型数据库的差别主要如下图:
《2》HBase数据库结构
HBase是由三种类型的服务器以主从模式构成的。由以下类型节点组成:HMaster节点、HRegionServer节点、ZooKeeper集群,而在底层,它将数据存储于HDFS中,因而涉及到HDFS的NameNode、DataNode等。
1、HBase Client:HBase客户端,通过RPC方式和HMaster、HRegionServer通信;
2、HMaster节点:管理HRegionServer和HRegion,数据库的创建和删除等操作;
3、HRegionServer:负责数据的读写服务,通过其实现数据的访问,是根据DataNode分布的;
4、ZooKeeper集群:协调系统,存放整个 HBase集群的元数据以及集群的状态信息,实现HMaster主从节点的失效备援;
5、HRegion:HBase使用RowKey将表水平切割成多个HRegion,从HMaster的角度,每个HRegion都纪录了它的StartKey和EndKey。每个HRegion分散在不同的RegionServer中。
《3》HBase的特点
1、存储大:一个表可以有上亿行,上百万列。
2、面向列:面向列表(簇)的存储和权限控制,列(簇)独立检索。
3、稀疏:对于为NULL的列,并不占用存储空间,表可以设计的非常稀疏。
4、无模式:每一行都有一个可以排序的主键和任意多的列,列可以根据需要动态增加,同一张表中不同的行可以有截然不同的列。
5、数据多版本:每个单元中的数据可以有多个版本,默认情况下,版本号自动分配,版本号就是单元格插入时的时间戳Timestamp。
6、数据类型单一:HBase中的数据都是字符串类型,没有其他选择。
参考文档:
(1)http://blog.csdn.net/babyfish13/article/details/52527665;
(2)https://www.cnblogs.com/kubixuesheng/p/5525306.html;
(3)https://baike.baidu.com/item/Hadoop/3526507?fr=aladdin#3_1;
(4)http://www.blogjava.net/DLevin/archive/2015/08/22/426877.html

相关文章推荐
- hadoop学习笔记1(Hadoop的源起与体系介绍)
- Hadoop学习笔记之一:Hadoop介绍
- Hadoop学习笔记一 简要介绍
- 云计算学习笔记---Hadoop简介,hadoop实现原理,NoSQL介绍...与传统关系型数据库对应关系,云计算面临的挑战
- Hadoop学习笔记—20.网站日志分析项目案例(一)项目介绍
- Hadoop学习笔记—1.基本介绍与环境配置
- Hadoop学习笔记 --- 文件格式介绍
- Hadoop学习笔记—20.网站日志分析项目案例(一)项目介绍
- Hadoop2.6.0学习笔记(一)MapReduce介绍
- Hadoop学习笔记—20.网站日志分析项目案例(一)项目介绍
- Hadoop学习笔记一 简要介绍
- Hadoop 学习笔记五 ---Hadoop系统通信协议介绍
- Hadoop学习笔记一 简要介绍
- Hadoop学习笔记(一)——Hadoop体系结构
- Hadoop学习笔记一 简要介绍
- Hadoop学习笔记之二:HDFS体系架构
- Hadoop学习笔记(一)——Hadoop体系结构
- Hadoop2.6.0学习笔记(八)Hadoop启动脚本介绍
- Hadoop学习笔记—1.基本介绍与环境配置
- 数据、进程-云计算学习笔记---Hadoop简介,hadoop实现原理,NoSQL介绍...与传统关系型数据库对应关系,云计算面临的挑战-by小雨