【C++】矩阵的压缩存储,还原,转置
2017-11-25 15:01
686 查看
矩阵的格式相当于是一个二维数组,如下图
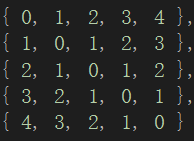
上图就是一个特殊的矩阵,对称矩阵
一、对称矩阵
对称矩阵中的元素有一定的规律,就是行下标row与列下标col 互换后得到的新坐标的元素与换坐标前的元素相同。
因此我们在存放对称矩阵的元素时只需将它的下三角或上三角的元素存储就可以了。

我们可以用一个类来管理这个矩阵,用容器vector来存储它的下三角的元素。(vector相当于是一个一维数组,使用时要引用头文件 #include<vector>)
(1)构造函数,将元素存入(压缩存储)
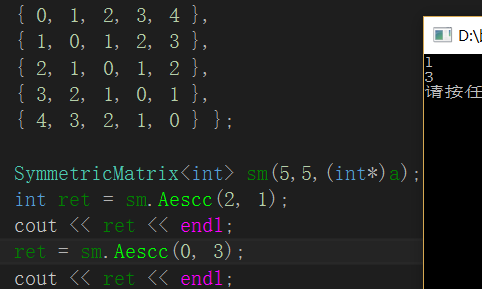
如图,当访问(2,1)时取到元素1
当访问(0,3)时,取得(3,0)处元素3
(3)打印对称矩阵
打印时要用到两层循环,再在函数内调用访问函数Aescc()就可以了
(4)对称矩阵完整代码:
二、稀疏矩阵
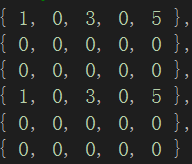
该矩阵是一个6行5列的稀疏矩阵,在存储稀疏矩阵时,我们采用压缩存储,只存储有效元素,上图中我们存入元素后为{1,3,5,1,3,5};其它元素为无效元素不进行存储,这样更节省空间。
因为稀疏矩阵没有规律,所以不能像对称矩阵那样只存储元素,我们还要存储它的下标,否则无法还原稀疏矩阵。
则我们要创建一个包含它的行坐标row 列坐标col 与元素 data 的结构体。
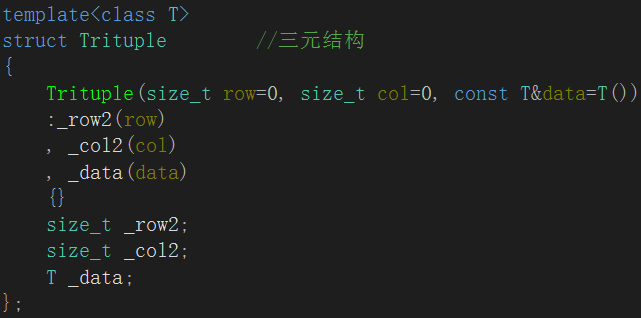
该结构体是一个模板类型的,构造函数给的是带缺省的,可以不传参。
(1)有效元素的存储,构造函数
存储结果
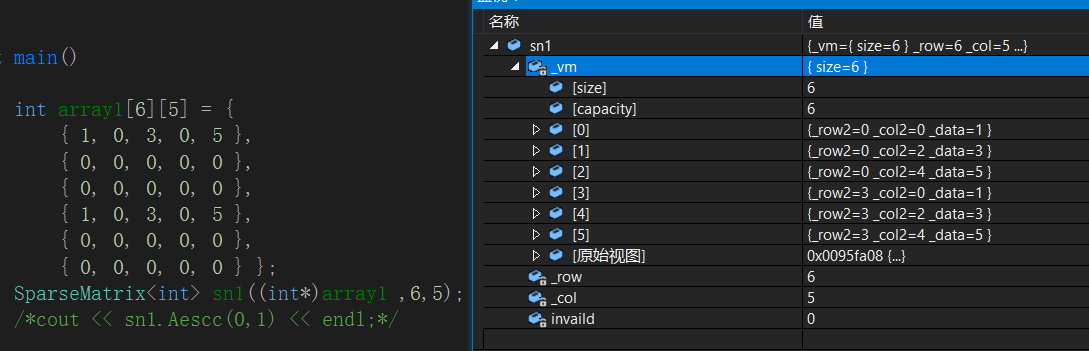
(2)元素访问
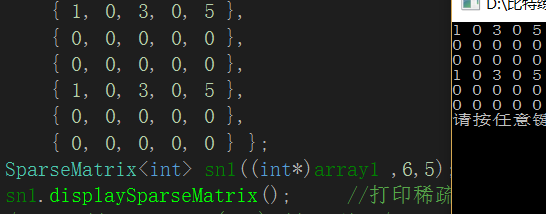
(3)打印稀疏矩阵
打印函数,两层循环,第一层循环控制行数,第二层控制列数,在引入一个索引index。当index<有效元素的个数时,并且有效元素的行坐标_row2==i和有效元素的列坐标_col2==j,我们就打印这个元素,否则输出无效值。当每输出_col个元素就换行。
我们还可以重载输出运算符,这样更方便
(4)转置(一般方法)时间复杂度比较大为(O(_col*_row*size));size是有效元素的个数
每到一个坐标,进入有效元素里找一遍,如果该坐标的行等于有效元素的列,并且该坐标的列等于有效元素的行,就输出这个有效元素。否则输出无效值。
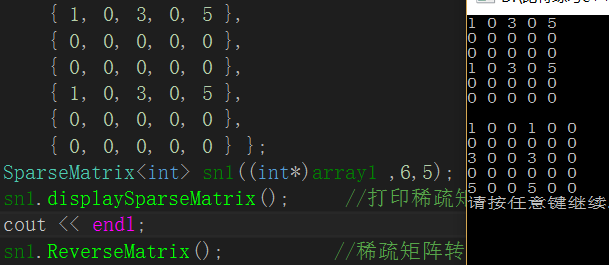
(5)快速转置

(6)稀疏矩阵加法
要实现两个矩阵的加法,我们与要重载+。
我们可以通过偏移量来确定元素位置,
<1>当偏移量相等时,并且两个矩阵在该位置的值都为有效值,则两个值相加,当这两个值相加得到的值不为无效值时,存入到新创建的矩阵tmp中并将左边矩阵的有效元素的下标加1,右边矩阵的有效元素下标加1。
<2>当左边矩阵有效元素的偏移量大,则将右边矩阵的有效元素存入tmp并将右边矩阵的有效元素的下标加1.
<3>当右边矩阵有效元素的偏移量大,则将左边矩阵的有效元素存入tmp并将左边矩阵的有效元素的下标加1.
<4>循环结束,则矩阵的有效元素有可能没有加完,将剩下的有效元素存入tmp,完成加法。
<5>返回tmp。
相加后的值

(7)稀疏矩阵的完整代码
上图就是一个特殊的矩阵,对称矩阵
一、对称矩阵
对称矩阵中的元素有一定的规律,就是行下标row与列下标col 互换后得到的新坐标的元素与换坐标前的元素相同。
因此我们在存放对称矩阵的元素时只需将它的下三角或上三角的元素存储就可以了。
我们可以用一个类来管理这个矩阵,用容器vector来存储它的下三角的元素。(vector相当于是一个一维数组,使用时要引用头文件 #include<vector>)
(1)构造函数,将元素存入(压缩存储)
SymmetricMatrix(size_t row,size_t col,T*array)
:_row(row)
, _col(col)
{
int index = 0;
_v.resize(((1 + row)*row) >> 1); //元素总个数为 ((1+row)*row)/2
for (size_t i = 0; i < row;i++)
for (size_t j = 0; j <= i; j++) //每一行只存储到行下标与列下表相等的地方结束
_v[index++] = array[i*col + j]; //每存一个数让index向后移动
}(2)元素访问T& Aescc(size_t row,size_t col)
{
if (row < col)
swap(row,col);
return _v[(((row + 1)*row) >> 1)+col];
}当行下标row小于列下标col时,表示访问的是上三角的元素,而对称矩阵中上三角中的元素与行列坐标相反的下三角中的元素相同,因此,将行坐标与列坐标互换,再取出元素就行了。如图,当访问(2,1)时取到元素1
当访问(0,3)时,取得(3,0)处元素3
(3)打印对称矩阵
void BackS
4000
ymmetricMatrix( )
{
for (size_t i = 0; i < _row; i++)
{
for (size_t j = 0; j < _col; j++)
{
cout << Aescc(i, j) << " ";
}
cout << endl;
}
}打印时要用到两层循环,再在函数内调用访问函数Aescc()就可以了
(4)对称矩阵完整代码:
#include<iostream>
#include<vector>
#include<assert.h>
using namespace std;
#if 1
template<class T> //对称矩阵
class SymmetricMatrix
{
public:
SymmetricMatrix(size_t row,size_t col,T*array)
:_row(row)
, _col(col)
{
int index = 0;
_v.resize(((1 + row)*row) >> 1);
for (size_t i = 0; i < row;i++)
for (size_t j = 0; j <= i; j++)
_v[index++] = array[i*col + j];
}
T& Aescc(size_t row,size_t col) { if (row < col) swap(row,col); return _v[(((row + 1)*row) >> 1)+col]; }
void BackSymmetricMatrix( )
{
for (size_t i = 0; i < _row; i++)
{
for (size_t j = 0; j < _col; j++)
{
cout << Aescc(i, j) << " ";
}
cout << endl;
}
}
private:
vector<T> _v;
size_t _row;
size_t _col;
};
int main() //测试代码
{
int a[5][5] = {
{ 0, 1, 2, 3, 4 },
{ 1, 0, 1, 2, 3 },
{ 2, 1, 0, 1, 2 },
{ 3, 2, 1, 0, 1 },
{ 4, 3, 2, 1, 0 } };
SymmetricMatrix<int> sm(5,5,(int*)a);
/*int ret = sm.Aescc(2, 1);
cout << ret << endl;
ret = sm.Aescc(0, 3);
cout << ret << endl;*/
sm.BackSymmetricMatrix();
system("pause");
return 0;
}
二、稀疏矩阵
该矩阵是一个6行5列的稀疏矩阵,在存储稀疏矩阵时,我们采用压缩存储,只存储有效元素,上图中我们存入元素后为{1,3,5,1,3,5};其它元素为无效元素不进行存储,这样更节省空间。
因为稀疏矩阵没有规律,所以不能像对称矩阵那样只存储元素,我们还要存储它的下标,否则无法还原稀疏矩阵。
则我们要创建一个包含它的行坐标row 列坐标col 与元素 data 的结构体。
该结构体是一个模板类型的,构造函数给的是带缺省的,可以不传参。
(1)有效元素的存储,构造函数
SparseMatrix(T*_array,size_t row, size_t col)
:_row(row)
, _col(col)
, invaild(0)
{
for (size_t i = 0; i < row; i++)
{
for (size_t j = 0; j < col; j++)
{
if (_array[i*col + j] != invaild) //当不是无效值时才存
_vm.push_back(Trituple<T>(i, j, _array[i*col + j]));
}
}
}传参时将二维数组转换成一维数组进行访问存储结果
(2)元素访问
T&Aescc(size_t row,size_t col)
{
for (size_t i = 0; i < _vm.size(); i++)
{
if (_vm[i]._row2 == row&&_vm[i]._col2 == col)
return _vm[i]._data;
}
return invaild;
}每传一个坐标进入访问函数,就去遍历存入的有效元素,如果传入的行坐标与有效元素的行坐标相等,并且列坐标与有效元素的列坐标相等,则返回这个有效元素。当将所有的有效元素搜索完时还未找到,返回无效值。(3)打印稀疏矩阵
void displaySparseMatrix() //打印稀疏矩阵
{
size_t index = 0;
for (size_t i = 0; i < _row; i++)
{
for (size_t j = 0; j < _col; j++)
{
if (index<_vm.size()&&_vm[index]._row2 == i&&_vm[index]._col2 == j)
{
cout << _vm[index]._data << " ";
index++;
}
else
cout << invaild<<" ";
}
cout << endl;
}
}打印函数,两层循环,第一层循环控制行数,第二层控制列数,在引入一个索引index。当index<有效元素的个数时,并且有效元素的行坐标_row2==i和有效元素的列坐标_col2==j,我们就打印这个元素,否则输出无效值。当每输出_col个元素就换行。
我们还可以重载输出运算符,这样更方便
friend ostream& operator<<(ostream&_cout, SparseMatrix<T>&m)
{
size_t index = 0;
for (size_t i = 0; i < m._row; i++)
{
for (size_t j = 0; j < m._col; j++)
{
if (index<m._vm.size() && m._vm[index]._row2 == i&&m._vm[index]._col2 == j)
{
_cout << m._vm[index]._data << " ";
index++;
}
else
_cout << m.invaild << " ";
}
cout << endl;
}
return _cout;
}当需要打印稀疏矩阵时,直接调用 cout<< sn1<<endl;(sn1为稀疏矩阵对象),这样输出更简单。(4)转置(一般方法)时间复杂度比较大为(O(_col*_row*size));size是有效元素的个数
void ReverseMatrix() //矩阵转置
{
for (size_t i = 0; i < _col; i++)
{
for (size_t j = 0; j < _row; j++)
{
int flag = 0; //标记
size_t index = _vm.size();
while (index--)
{
if (_vm[index]._row2 == j&&_vm[index]._col2==i)
{
flag = 1;
cout << _vm[index]._data << " ";
}
}
if (flag==0)
cout << invaild << " ";
}
cout << endl;
}
}两层循环打印出一个稀疏矩阵,转置后的行数为原来矩阵的列数,转置后的列数为原来矩阵的行数。每到一个坐标,进入有效元素里找一遍,如果该坐标的行等于有效元素的列,并且该坐标的列等于有效元素的行,就输出这个有效元素。否则输出无效值。
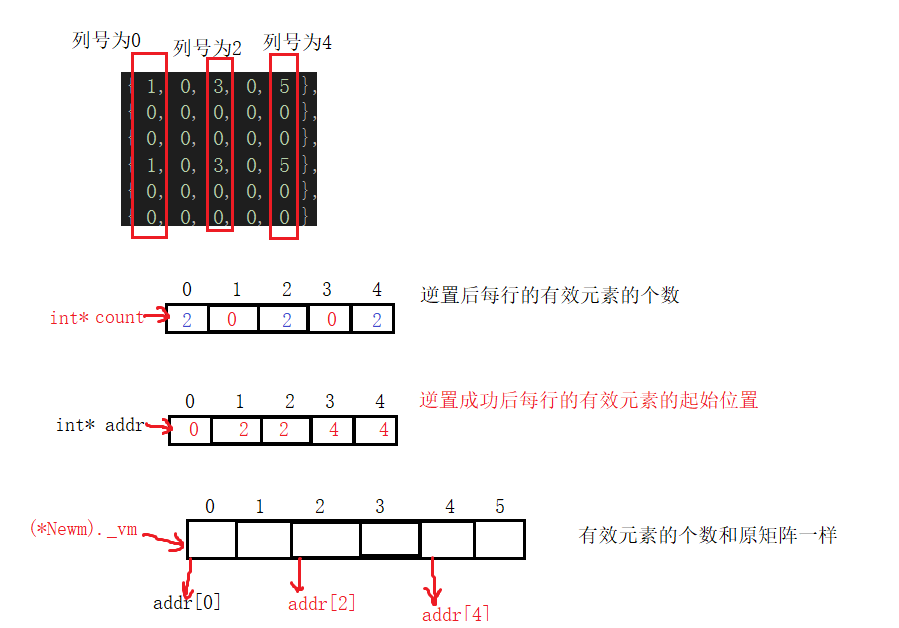
(5)快速转置
SparseMatrix<T>& FastReverseMatrix() //快速逆置
{
SparseMatrix<T> *Newm=new SparseMatrix<T>;
(*Newm)._row = _col;
(*Newm)._col = _row;
(*Newm).invaild = invaild;
(*Newm)._vm.resize(_vm.size());
//逆置成功后每一行有效元素的个数
int *count = new int[_row];
memset(count, 0, _row*sizeof(int));
for (size_t i = 0; i < _vm.size(); i++)
count[_vm[i]._col2]++;
//逆置成功后后每行的有效元素的起始地址
int *addr = new int[_col];
memset(addr, 0, _col*sizeof(int));
for (size_t i = 1; i < _col; i++)
addr[i] = addr[i - 1] + count[i - 1];
for (size_t i = 0; i < _vm.size(); i++)
{
int &rowAddr = addr[_vm[i]._col2];
(*Newm)._vm[rowAddr] = _vm[i];
swap((*Newm)._vm[rowAddr]._row2, (*Newm)._vm[rowAddr]._col2);
rowAddr++;
}
return (*Newm);
}(6)稀疏矩阵加法
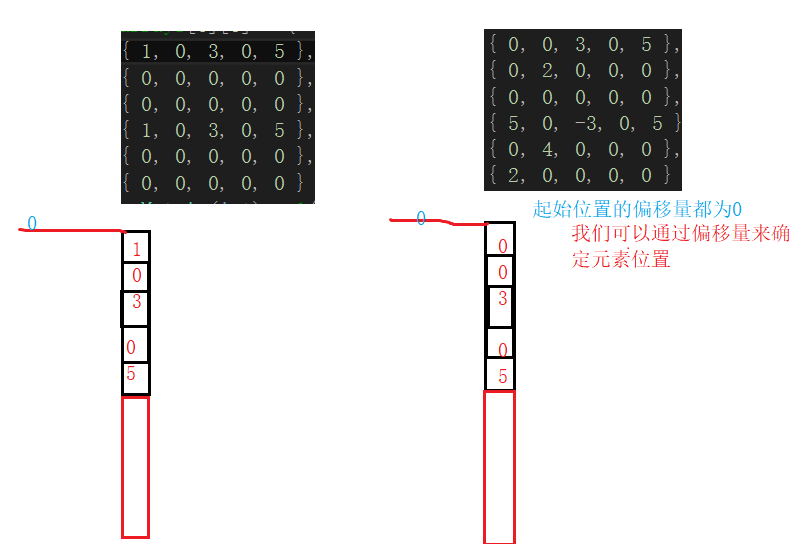
要实现两个矩阵的加法,我们与要重载+。
我们可以通过偏移量来确定元素位置,
<1>当偏移量相等时,并且两个矩阵在该位置的值都为有效值,则两个值相加,当这两个值相加得到的值不为无效值时,存入到新创建的矩阵tmp中并将左边矩阵的有效元素的下标加1,右边矩阵的有效元素下标加1。
<2>当左边矩阵有效元素的偏移量大,则将右边矩阵的有效元素存入tmp并将右边矩阵的有效元素的下标加1.
<3>当右边矩阵有效元素的偏移量大,则将左边矩阵的有效元素存入tmp并将左边矩阵的有效元素的下标加1.
<4>循环结束,则矩阵的有效元素有可能没有加完,将剩下的有效元素存入tmp,完成加法。
<5>返回tmp。
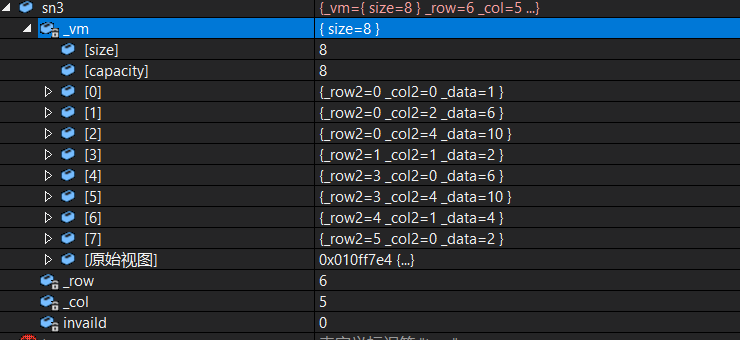
SparseMatrix<T>& operator+( SparseMatrix<T>& d) //重载+,实现两个矩阵的加法
{
assert(d._row==_row&&d._col==_col);
SparseMatrix<T> *tmp=new SparseMatrix<T>;
(*tmp)._col = _col;
(*tmp)._row = _row;
(*tmp).invaild = invaild;
size_t leftMatrix = 0;
size_t rightMatrix = 0;
size_t Addrleft = 0;
size_t Addrright = 0;
while (leftMatrix < _vm.size() && rightMatrix < d._vm.size())
{
Addrleft = _vm[leftMatrix]._row2*_col + _vm[leftMatrix]._col2;
Addrright = d._vm[rightMatrix]._row2*_col + d._vm[rightMatrix]._col2;
if (Addrleft>Addrright)
{
(*tmp)._vm.push_back(d._vm[rightMatrix]);
rightMatrix++;
}
else if (Addrleft < Addrright)
{
(*tmp)._vm.push_back(_vm[leftMatrix]);
leftMatrix++;
}
else
{
Trituple<T> ret;
ret._col2 = _vm[leftMatrix]._col2;
ret._row2 = _vm[leftMatrix]._row2;
ret._data = _vm[leftMatrix]._data + d._vm[rightMatrix]._data;
if (ret._data!=invaild)
(*tmp)._vm.push_back(ret);
leftMatrix++;
rightMatrix++;
}
}
while (leftMatrix < _vm.size())
{
(*tmp)._vm.push_back(_vm[leftMatrix]);
leftMatrix++;
}
while (rightMatrix < d._vm.size())
{
(*tmp)._vm.push_back(d._vm[rightMatrix]);
rightMatrix++;
}
return (*tmp);
}测试相加后的值
(7)稀疏矩阵的完整代码
//稀疏矩阵
template<class T>
class SparseMatrix
{
public:
template<class T>
struct Trituple //三元结构
{
Trituple(size_t row = 0, size_t col = 0, const T&data = T())
:_row2(row)
, _col2(col)
, _data(data)
{}
size_t _row2;
size_t _col2;
T _data;
};
SparseMatrix()
{ }
SparseMatrix(T*_array,size_t row, size_t col)
:_row(row)
, _col(col)
, invaild(0)
{
for (size_t i = 0; i < row; i++)
{
for (size_t j = 0; j < col; j++)
{
if (_array[i*col + j] != invaild)
_vm.push_back(Trituple<T>(i, j, _array[i*col + j]));
}
}
}
T&Aescc(size_t row,size_t col) { for (size_t i = 0; i < _vm.size(); i++) { if (_vm[i]._row2 == row&&_vm[i]._col2 == col) return _vm[i]._data; } return invaild; }
void displaySparseMatrix() //打印稀疏矩阵 { size_t index = 0; for (size_t i = 0; i < _row; i++) { for (size_t j = 0; j < _col; j++) { if (index<_vm.size()&&_vm[index]._row2 == i&&_vm[index]._col2 == j) { cout << _vm[index]._data << " "; index++; } else cout << invaild<<" "; } cout << endl; } }
void ReverseMatrix() //矩阵转置 { for (size_t i = 0; i < _col; i++) { for (size_t j = 0; j < _row; j++) { int flag = 0; //标记 size_t index = _vm.size(); while (index--) { if (_vm[index]._row2 == j&&_vm[index]._col2==i) { flag = 1; cout << _vm[index]._data << " "; } } if (flag==0) cout << invaild << " "; } cout << endl; } }
friend ostream& operator<<(ostream&_cout, SparseMatrix<T>&m) { size_t index = 0; for (size_t i = 0; i < m._row; i++) { for (size_t j = 0; j < m._col; j++) { if (index<m._vm.size() && m._vm[index]._row2 == i&&m._vm[index]._col2 == j) { _cout << m._vm[index]._data << " "; index++; } else _cout << m.invaild << " "; } cout << endl; } return _cout; }
SparseMatrix<T>& operator+( SparseMatrix<T>& d) //重载+,实现两个矩阵的加法 { assert(d._row==_row&&d._col==_col); SparseMatrix<T> *tmp=new SparseMatrix<T>; (*tmp)._col = _col; (*tmp)._row = _row; (*tmp).invaild = invaild; size_t leftMatrix = 0; size_t rightMatrix = 0; size_t Addrleft = 0; size_t Addrright = 0; while (leftMatrix < _vm.size() && rightMatrix < d._vm.size()) { Addrleft = _vm[leftMatrix]._row2*_col + _vm[leftMatrix]._col2; Addrright = d._vm[rightMatrix]._row2*_col + d._vm[rightMatrix]._col2; if (Addrleft>Addrright) { (*tmp)._vm.push_back(d._vm[rightMatrix]); rightMatrix++; } else if (Addrleft < Addrright) { (*tmp)._vm.push_back(_vm[leftMatrix]); leftMatrix++; } else { Trituple<T> ret; ret._col2 = _vm[leftMatrix]._col2; ret._row2 = _vm[leftMatrix]._row2; ret._data = _vm[leftMatrix]._data + d._vm[rightMatrix]._data; if (ret._data!=invaild) (*tmp)._vm.push_back(ret); leftMatrix++; rightMatrix++; } } while (leftMatrix < _vm.size()) { (*tmp)._vm.push_back(_vm[leftMatrix]); leftMatrix++; } while (rightMatrix < d._vm.size()) { (*tmp)._vm.push_back(d._vm[rightMatrix]); rightMatrix++; } return (*tmp); }
SparseMatrix<T>& FastReverseMatrix() //快速逆置
{
SparseMatrix<T> *Newm=new SparseMatrix<T>;
(*Newm)._row = _col;
(*Newm)._col = _row;
(*Newm).invaild = invaild;
(*Newm)._vm.resize(_vm.size());
//逆置成功后每一行有效元素的个数
int *count = new int[_col];
memset(count, 0, _col*sizeof(int));
for (size_t i = 0; i < _vm.size(); i++)
count[_vm[i]._col2]++;
//逆置成功后后每行的有效元素的起始地址
int *addr = new int[_col];
memset(addr, 0, _col*sizeof(int));
for (size_t i = 1; i < _col; i++)
addr[i] = addr[i - 1] + count[i - 1];
for (size_t i = 0; i < _vm.size(); i++)
{
int &rowAddr = addr[_vm[i]._col2];
(*Newm)._vm[rowAddr] = _vm[i];
swap((*Newm)._vm[rowAddr]._row2, (*Newm)._vm[rowAddr]._col2);
rowAddr++;
}
return (*Newm);
}
private:
vector <Trituple<T>>
a9d4
_vm;
size_t _row;
size_t _col;
T invaild;
};
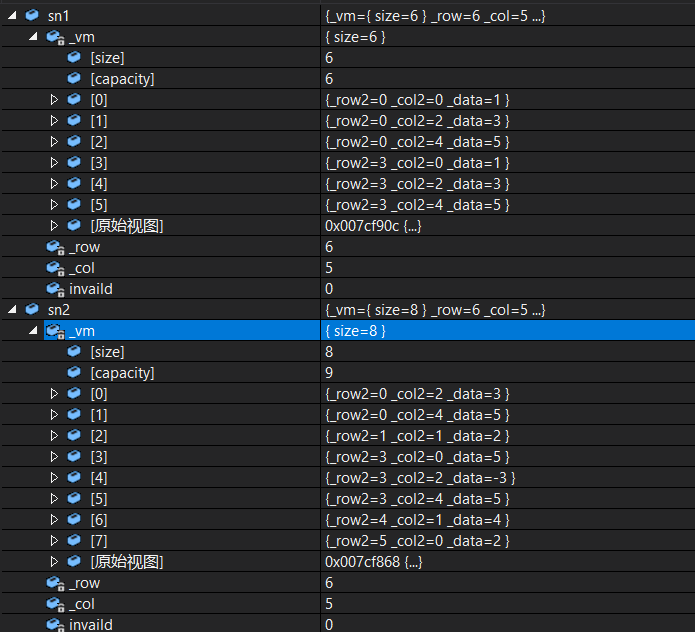
void test1() //测试矩阵加法
{
int array1[6][5] = {
{ 1, 0, 3, 0, 5 },
{ 0, 0, 0, 0, 0 },
{ 0, 0, 0, 0, 0 },
{ 1, 0, 3, 0, 5 },
{ 0, 0, 0, 0, 0 },
{ 0, 0, 0, 0, 0 } };
SparseMatrix<int> sn1((int*)array1, 6, 5); //存储一个稀疏矩阵
sn1.displaySparseMatrix(); //打印稀疏矩阵
cout << endl;
int array2[6][5] = {
{ 0, 0, 3, 0, 5 },
{ 0, 2, 0, 0, 0 },
{ 0, 0, 0, 0, 0 },
{ 5, 0, -3, 0, 5 },
{ 0, 4, 0, 0, 0 },
{ 2, 0, 0, 0, 0 } };
SparseMatrix<int> sn2((int*)array2, 6, 5); //存储一个稀疏矩阵
cout << sn2 << endl;
SparseMatrix<int> sn3 = sn1 + sn2;
cout << sn3;
}
void test2() //测试矩阵快速转置函数
{
int array1[6][5] = {
{ 1, 0, 3, 0, 5 },
{ 0, 0, 0, 0, 0 },
{ 0, 0, 0, 0, 0 },
{ 1, 0, 3, 0, 5 },
{ 0, 0, 0, 0, 0 },
{ 0, 0, 0, 0, 0 } };
SparseMatrix<int> sn1((int*)array1, 6, 5); //存储一个稀疏矩阵
SparseMatrix<int> sn2=sn1.FastReverseMatrix();
cout << sn2;
}
int main()
{
test1();
//test2();
system("pause");
return 0;
}

相关文章推荐
- 【数据结构】稀疏矩阵的压缩存储和转置算法(C++代码)
- 稀疏矩阵的压缩存储及转置,快速转置法,C++代码实现
- C++实现稀疏矩阵的压缩存储、转置、快速转置
- C++实现矩阵压缩存储与(快速)转置
- C/C++ 第八周串和数组 (一)对称矩阵压缩存储的实现与应用 项目3—(2)
- 稀疏矩阵的压缩存储及转置
- 稀疏矩阵三元组方式压缩存储 c++模板类实现
- 稀疏矩阵的压缩存储以及快速转置
- 【代码】稀疏矩阵的压缩存储与转置算法
- 稀疏矩阵的压缩存储和转置
- 稀疏矩阵-压缩存储-列转置法- 一次定位快速转置法
- 稀疏矩阵的压缩存储和转置
- 稀疏矩阵的压缩存储及转置算法
- 数据结构 对称矩阵的压缩存储与稀疏矩阵的转置
- 矩阵的压缩存储以及转置
- 稀疏矩阵压缩存储及转置,加法运算(采用三元表)
- C++ 实现稀疏矩阵的压缩存储的实例
- 稀疏矩阵的压缩存储与转置
- C++实现稀疏矩阵的压缩存储
- 【数据结构】稀疏结构及稀疏矩阵的压缩存储,矩阵的(快速)转置