RabbitMQ集群与高可用部署
2017-11-22 13:48
459 查看
部署环境
系统环境
172.16.10.10 计算机名:node1.rabbitmq
172.16.10.11 计算机名:node2.rabbitmq
172.16.10.12 计算机名:node3.rabbitmq
所有服务器操作系统为:CentOS Linux release 7.3.1611 (Core)
hosts文件如下:
172.16.10.10 node1.rabbitmq node1
172.16.10.11 node2.rabbitmq node2
172.16.10.12 node3.rabbitmq node3
软件环境
rabbitmq部署方法:yum -y install rabbitmq-server
rabbitmq安装版本:rabbitmq-server-3.3.5-34.el7.noarch
注意:
部署集群要求所有节点的rabbitmq-server版本需要相同,如果是源码安装的话还要求rabbitmq-server所依赖的软件环境也要相同
集群方案
因我们要实现集群高可用的功能,所以我们采用镜像模式,此模式下有任何一台服务器宕机不会影响正常的生产和消费,但集群内部的通讯会占用较大的带宽
部署集群
在部署集群开始前我们还需要再次确保服务器和软件环境正确,接下来按下面步骤部署镜像集群
将node1节点的/var/lib/rabbitmq/.erlang.cookie复制到其它集群节点,因为各集群节点之间通讯必须共享相同的erlang cookie,这就是rabbitmq底层的工作原理。
systemctl start rabbitmq-server
scp /var/lib/rabbitmq/.erlang.cookie 172.16.10.11:/var/lib/rabbitmq/
scp /var/lib/rabbitmq/.erlang.cookie 172.16.10.12:/var/lib/rabbitmq/
注意:此文件是在rabbitmq-server服务第一次启动是才会生成的,并且些文件的权限为400,属主和属组为rabbitmq。所以我们需要在node1上面启动一次rabbitmq-server服务,再执行复制
将node2和node3节点启动,分别在node2和node3执行下面的命令
chown rabbitmq:rabbitmq /var/lib/rabbitmq/.erlang.cookie
systemctl start rabbitmq-server
将node2和node3加入到集群环境,分别在node2和node3执行下面命令
rabbitmqctl stop_app
rabbitmqctl join_cluster rabbit@node1
rabbitmqctl start_app
验证集群配置,在集群中任意一个node上面执行下在命令,查看到的结果一样
rabbitmqctl cluster_status(结果如下图所示)
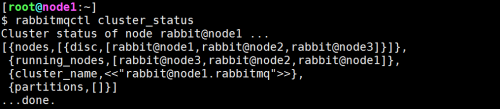
在所有节点启用rabbitmq_management插件,在所有节点执行以下命令
rabbitmq-plugins enable rabbitmq_management
systemctl restart rabbitmq-server
将服务加入开机自启动
systemctl enable rabbitmq-server
最后在任何一节点执行以下命令rabbitmqctl set_policy -p nirvana-device ha-all "^\.*" '{"ha-mode":"all"}'配置指定虚拟主机的所有队列为镜像模式,-p指定虚拟主机,不指定默认为 / 这样配置后我们将会有两个镜像节点,只要保障有一台rabbitmq正常工作那么集群就可以提供服务
配置HAProxy+Keepalived
为了实现我们的RabbitMQ集群高可用,我们需要在前端加一个HAProxy来代理RabbitMQ访问,另外防止HAProxy单节点故障,所以我们使用HAProxy+Keepalived+RabbitMQ的方案来实现整套集群环境
安装HAPoryx和Keepalived
因测试环境服务器有限,我们将HAProxy和Keepalived部署在node1和node2上面,并使用172.16.10.100为VIP,在node1和node2上面行以下命令安装
yum install haproxy keepalived
Node1的Keepalived配置
chmod 755 /etc/keepalived/haproxy_check.sh
HAPorxy配置文件(Node1和Node2相同)
增加一行配置local2.* /var/log/haproxy.log
重启rsyslog服务systemctl restart rsyslog到目前为止,RabbitMQ集群部署完毕,最后就是测试集群
系统环境
172.16.10.10 计算机名:node1.rabbitmq
172.16.10.11 计算机名:node2.rabbitmq
172.16.10.12 计算机名:node3.rabbitmq
所有服务器操作系统为:CentOS Linux release 7.3.1611 (Core)
hosts文件如下:
172.16.10.10 node1.rabbitmq node1
172.16.10.11 node2.rabbitmq node2
172.16.10.12 node3.rabbitmq node3
软件环境
rabbitmq部署方法:yum -y install rabbitmq-server
rabbitmq安装版本:rabbitmq-server-3.3.5-34.el7.noarch
注意:
部署集群要求所有节点的rabbitmq-server版本需要相同,如果是源码安装的话还要求rabbitmq-server所依赖的软件环境也要相同
集群方案
因我们要实现集群高可用的功能,所以我们采用镜像模式,此模式下有任何一台服务器宕机不会影响正常的生产和消费,但集群内部的通讯会占用较大的带宽
部署集群
在部署集群开始前我们还需要再次确保服务器和软件环境正确,接下来按下面步骤部署镜像集群
将node1节点的/var/lib/rabbitmq/.erlang.cookie复制到其它集群节点,因为各集群节点之间通讯必须共享相同的erlang cookie,这就是rabbitmq底层的工作原理。
systemctl start rabbitmq-server
scp /var/lib/rabbitmq/.erlang.cookie 172.16.10.11:/var/lib/rabbitmq/
scp /var/lib/rabbitmq/.erlang.cookie 172.16.10.12:/var/lib/rabbitmq/
注意:此文件是在rabbitmq-server服务第一次启动是才会生成的,并且些文件的权限为400,属主和属组为rabbitmq。所以我们需要在node1上面启动一次rabbitmq-server服务,再执行复制
将node2和node3节点启动,分别在node2和node3执行下面的命令
chown rabbitmq:rabbitmq /var/lib/rabbitmq/.erlang.cookie
systemctl start rabbitmq-server
将node2和node3加入到集群环境,分别在node2和node3执行下面命令
rabbitmqctl stop_app
rabbitmqctl join_cluster rabbit@node1
rabbitmqctl start_app
验证集群配置,在集群中任意一个node上面执行下在命令,查看到的结果一样
rabbitmqctl cluster_status(结果如下图所示)
在所有节点启用rabbitmq_management插件,在所有节点执行以下命令
rabbitmq-plugins enable rabbitmq_management
systemctl restart rabbitmq-server
将服务加入开机自启动
systemctl enable rabbitmq-server
最后在任何一节点执行以下命令rabbitmqctl set_policy -p nirvana-device ha-all "^\.*" '{"ha-mode":"all"}'配置指定虚拟主机的所有队列为镜像模式,-p指定虚拟主机,不指定默认为 / 这样配置后我们将会有两个镜像节点,只要保障有一台rabbitmq正常工作那么集群就可以提供服务
配置HAProxy+Keepalived
为了实现我们的RabbitMQ集群高可用,我们需要在前端加一个HAProxy来代理RabbitMQ访问,另外防止HAProxy单节点故障,所以我们使用HAProxy+Keepalived+RabbitMQ的方案来实现整套集群环境
安装HAPoryx和Keepalived
因测试环境服务器有限,我们将HAProxy和Keepalived部署在node1和node2上面,并使用172.16.10.100为VIP,在node1和node2上面行以下命令安装
yum install haproxy keepalived
Node1的Keepalived配置
! Configuration File for keepalived
global_defs {
router_id node1
}
vrrp_script chk_haproxy {
script "/etc/keepalived/haproxy_check.sh"
interval 2
weight 20
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
track_script {
chk_haproxy
}
virtual_ipaddress {
172.16.10.100/24
}
}Node2的Keepalived配置! Configuration File for keepalived
global_defs {
router_id node2
}
vrrp_script chk_haproxy {
script "/etc/keepalived/haproxy_check.sh"
interval 2
weight 20
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
track_script {
chk_haproxy
}
virtual_ipaddress {
172.16.10.100/24
}
}haproxy_check.sh脚本配置#!/bin/bash A=`ps -C haproxy --no-header | wc -l` if [ $A -eq 0 ];then haproxy -f /etc/haproxy/haproxy.cfg sleep 2 if [ `ps -C haproxy --no-header | wc -l` -eq 0 ];then pkill keepalived fi fi注意:此脚本需要有执行权限
chmod 755 /etc/keepalived/haproxy_check.sh
HAPorxy配置文件(Node1和Node2相同)
global log 127.0.0.1 local2 chroot /var/lib/haproxy pidfile /var/run/haproxy.pid maxconn 4000 user haproxy group haproxy daemon stats socket /var/lib/haproxy/stats defaults mode http log global option httplog option dontlognull option http-server-close option forwardfor except 127.0.0.0/8 option redispatch retries 3 timeout http-request 10s timeout queue 1m timeout connect 10s timeout client 1m timeout server 1m timeout http-keep-alive 10s timeout check 10s maxconn 4000 listen rabbitmq_cluster bind 0.0.0.0:5670 mode tcp option tcplog timeout client 3h timeout server 3h timeout connect 3h balance roundrobin server node1 172.16.10.10:5672 check inter 5000 rise 2 fall 3 server node2 172.16.10.11:5672 check inter 2000 rise 2 fall 3 server node2 172.16.10.12:5672 check inter 2000 rise 2 fall 3 listen rabbitmq_cluster bind 0.0.0.0:15670 balance roundrobin server node1 172.16.10.10:15672 check inter 5000 rise 2 fall 3 server node2 172.16.10.11:15672 check inter 2000 rise 2 fall 3 server node2 172.16.10.12:15672 check inter 2000 rise 2 fall 3开启HAProxy日志(Node1和Node2相同)编辑/etc/rsyslog.conf,打开以下四行注释$ModLoad imudp$UDPServerRun 514$ModLoad imtcp$InputTCPServerRun 514
增加一行配置local2.* /var/log/haproxy.log
重启rsyslog服务systemctl restart rsyslog到目前为止,RabbitMQ集群部署完毕,最后就是测试集群

相关文章推荐
- Rabbitmq集群HA高可用环境部署
- Rabbitmq集群高可用部署详细
- 高可用rabbitmq集群服务部署步骤
- Rabbitmq集群高可用部署详细
- Rabbitmq集群高可用部署详细
- [ Openstack ] Openstack-Mitaka 高可用之 Rabbitmq-server 集群部署
- 非常不错的rabbitmq集群高可用部署
- Rabbitmq集群高可用部署详细
- Rabbitmq集群高可用部署详细
- Rabbitmq集群高可用部署详细
- 高可用rabbitmq集群服务部署步骤
- 高可用rabbitmq集群服务部署步骤
- kubernetes kubeadm部署高可用集群
- MySQL分片高可用集群之Cobar部署使用 推荐
- LVS+keepalived高可用负载均衡集群部署(二)---LAMP网站服务器与LVS服务器
- RabbitMQ 集群与高可用配置
- kubeadm部署k8s1.9高可用集群--4部署master节点
- 分布式高并发高可用FastDFS文件服务器集群部署----
- linux上部署zookeeper伪集群【实测可用】
- MySQL分片高可用集群之Cobar部署使用