谈谈个人网站的建立(六)—— 数据库同步
2017-11-20 10:16
363 查看
欢迎访问我的个人网站O(∩_∩)O哈哈~希望大佬们能给个star,个人网站网址:http://www.wenzhihuai.com,个人网站代码地址:https://github.com/Zephery/newblog。
先来回顾一下上一篇的小集群架构,tomcat集群,nginx进行反向代理,服务器异地:
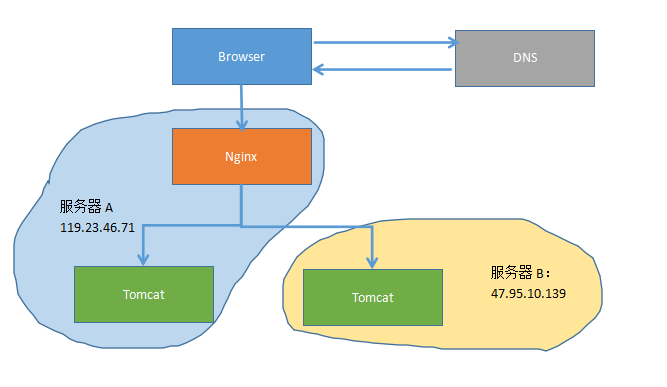
由上一篇讲到,部署的时候,将war部署在不同的服务器里,通过spring-session实现了session共享,基本的分布式部署还算是完善了点,但是想了想数据库的访问会不会延迟太大,毕竟一个服务器在北京,一个在深圳,然后试着ping了一下:

果然,36ms。。。看起来挺小的,但是对比一下sql执行语句的时间:
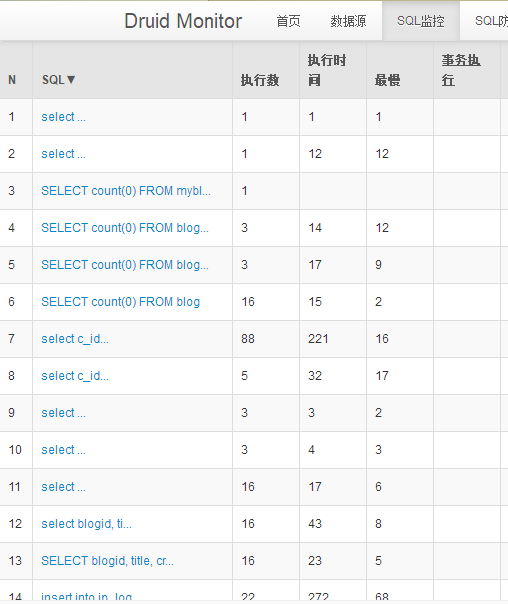
大部分都能在10ms内完成,而最长的语句是insert语句,可见,由于异地导致的36ms延时还是比较大的,捣鼓了一下,最后还是选择换个架构,每个服务器读取自己的数据库,然后数据库底层做一下主主复制,让数据同步。最终架构如下:

(1)master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events);
(2)slave将master的binary log events拷贝到它的中继日志(relay log);
(3)slave重做中继日志中的事件,将改变反映它自己的数据。
[align=center]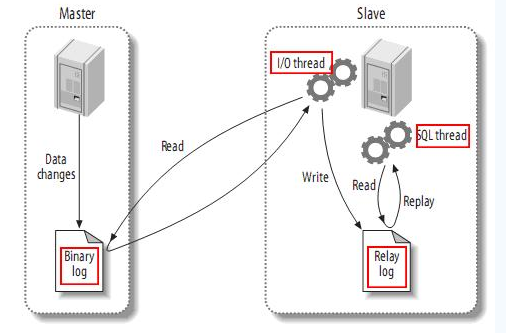[/align]
该过程的第一部分就是master记录二进制日志。在每个事务更新数据完成之前,master在二日志记录这些改变。MySQL将事务串行的写入二进制日志,即使事务中的语句都是交叉执行的。在事件写入二进制日志完成后,master通知存储引擎提交事务。
下一步就是slave将master的binary log拷贝到它自己的中继日志。首先,slave开始一个工作线程——I/O线程。I/O线程在master上打开一个普通的连接,然后开始binlog dump process。Binlog dump process从master的二进制日志中读取事件,如果已经跟上master,它会睡眠并等待master产生新的事件。I/O线程将这些事件写入中继日志。
SQL slave thread处理该过程的最后一步。SQL线程从中继日志读取事件,更新slave的数据,使其与master中的数据一致。只要该线程与I/O线程保持一致,中继日志通常会位于OS的缓存中,所以中继日志的开销很小。
此外,在master中也有一个工作线程:和其它MySQL的连接一样,slave在master中打开一个连接也会使得master开始一个线程。复制过程有一个很重要的限制——复制在slave上是串行化的,也就是说master上的并行更新操作不能在slave上并行操作。
MySql的基本复制方式有主从复制、主主复制,主主复制即把主从复制的配置倒过来再配置一遍即可,下面的配置则是主从复制的过程,到时候可自行改为主主复制。其他的架构如:一主库多备库、环形复制、树或者金字塔型都是基于这两种方式,可参考《高性能MySql》。
重启Mysql之后,查看主库状态,show master status。

其中,File为日志文件,指定Slave从哪个日志文件开始读复制数据,Position为偏移,从哪个POSITION号开始读,Binlog_Do_DB为要备份的数据库。
重启slave,同时启动复制,还需要调整一下命令。
可以看见slave已经开始进行同步了。我们使用show slave status\G来查看slave的状态。
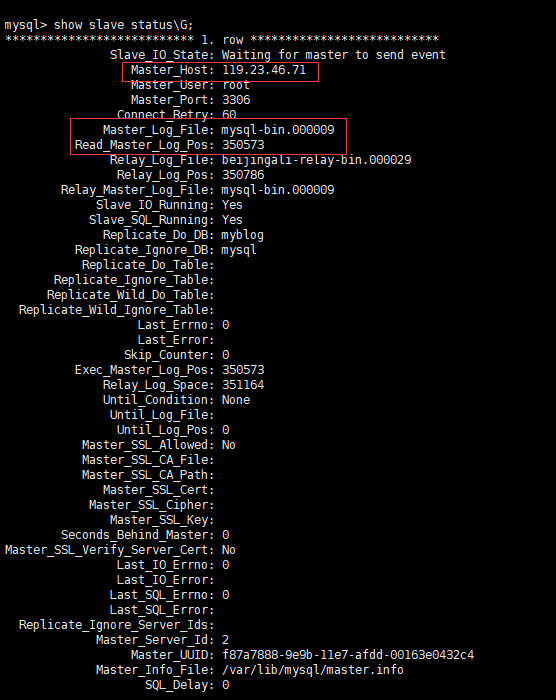
其中日志文件和POSITION不一致是合理的,配置好了的话,即使重启,也不会影响到主从复制的配置。
某天在Github上漂游,发现了阿里的canal,同时才知道上面这个业务是叫异地跨机房同步,早期,阿里巴巴B2B公司因为存在杭州和美国双机房部署,存在跨机房同步的业务需求。不过早期的数据库同步业务,主要是基于trigger的方式获取增量变更,不过从2010年开始,阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务。下面是基本的原理:
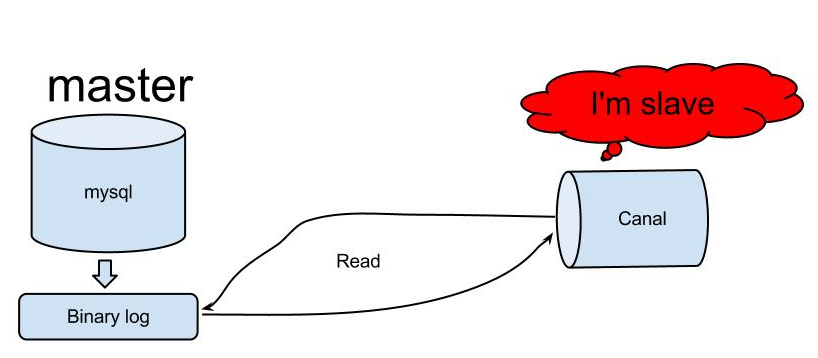
原理相对比较简单:
1.canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议
2.mysql master收到dump请求,开始推送binary log给slave(也就是canal)
3.canal解析binary log对象(原始为byte流)
其中,配置过程如下:https://github.com/alibaba/canal,可以搭配Zookeeper使用。在ZKUI中能够查看到节点:

一般情况下,还要配合阿里的另一个开源产品使用otter,相关文档还是找找GitHub吧,个人搭建完了之后,用起来还是不如直接使用mysql的主主复制,而且异地机房同步这种大企业才有的业务。
公司又要996了,实在是忙不过来,感觉自己写的还是急躁了点,困==
欢迎访问我的个人网站O(∩_∩)O哈哈~希望能给个star
个人网站网址:http://www.wenzhihuai.com
个人网站代码地址:https://github.com/Zephery/newblog
先来回顾一下上一篇的小集群架构,tomcat集群,nginx进行反向代理,服务器异地:
由上一篇讲到,部署的时候,将war部署在不同的服务器里,通过spring-session实现了session共享,基本的分布式部署还算是完善了点,但是想了想数据库的访问会不会延迟太大,毕竟一个服务器在北京,一个在深圳,然后试着ping了一下:
果然,36ms。。。看起来挺小的,但是对比一下sql执行语句的时间:
大部分都能在10ms内完成,而最长的语句是insert语句,可见,由于异地导致的36ms延时还是比较大的,捣鼓了一下,最后还是选择换个架构,每个服务器读取自己的数据库,然后数据库底层做一下主主复制,让数据同步。最终架构如下:
一、MySql的复制
数据库复制的基本问题就是让一台服务器的数据与其他服务器保持同步。MySql目前支持两种复制方式:基于行的复制和基于语句的复制,这两者的基本过程都是在主库上记录二进制的日志、在备库上重放日志的方式来实现异步的数据复制。其过程分为三步:(1)master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events);
(2)slave将master的binary log events拷贝到它的中继日志(relay log);
(3)slave重做中继日志中的事件,将改变反映它自己的数据。
[align=center][/align]
该过程的第一部分就是master记录二进制日志。在每个事务更新数据完成之前,master在二日志记录这些改变。MySQL将事务串行的写入二进制日志,即使事务中的语句都是交叉执行的。在事件写入二进制日志完成后,master通知存储引擎提交事务。
下一步就是slave将master的binary log拷贝到它自己的中继日志。首先,slave开始一个工作线程——I/O线程。I/O线程在master上打开一个普通的连接,然后开始binlog dump process。Binlog dump process从master的二进制日志中读取事件,如果已经跟上master,它会睡眠并等待master产生新的事件。I/O线程将这些事件写入中继日志。
SQL slave thread处理该过程的最后一步。SQL线程从中继日志读取事件,更新slave的数据,使其与master中的数据一致。只要该线程与I/O线程保持一致,中继日志通常会位于OS的缓存中,所以中继日志的开销很小。
此外,在master中也有一个工作线程:和其它MySQL的连接一样,slave在master中打开一个连接也会使得master开始一个线程。复制过程有一个很重要的限制——复制在slave上是串行化的,也就是说master上的并行更新操作不能在slave上并行操作。
MySql的基本复制方式有主从复制、主主复制,主主复制即把主从复制的配置倒过来再配置一遍即可,下面的配置则是主从复制的过程,到时候可自行改为主主复制。其他的架构如:一主库多备库、环形复制、树或者金字塔型都是基于这两种方式,可参考《高性能MySql》。
二、配置过程
2.1 创建所用的复制账号
由于是个自己的小网站,就不做过多的操作了,直接使用root账号2.2 配置master
接下来要对mysql的serverID,日志位置,复制方式等进行操作,使用vim打开my.cnf。[client] default-character-set=utf8 [mysqld] character_set_server=utf8 init_connect= SET NAMES utf8 datadir=/var/lib/mysql socket=/var/lib/mysql/mysql.sock symbolic-links=0 log-error=/var/log/mysqld.log pid-file=/var/run/mysqld/mysqld.pid # master log-bin=mysql-bin # 设为基于行的复制 binlog-format=ROW # 设置server的唯一id server-id=2 # 忽略的数据库,不使用备份 binlog-ignore-db=information_schema binlog-ignore-db=cluster binlog-ignore-db=mysql # 要进行备份的数据库 binlog-do-db=myblog
重启Mysql之后,查看主库状态,show master status。
其中,File为日志文件,指定Slave从哪个日志文件开始读复制数据,Position为偏移,从哪个POSITION号开始读,Binlog_Do_DB为要备份的数据库。
2.3 配置slave
从库的配置跟主库类似,vim /etc/my.cnf配置从库信息。[client] default-character-set=utf8 [mysqld] character_set_server=utf8 init_connect= SET NAMES utf8 datadir=/var/lib/mysql socket=/var/lib/mysql/mysql.sock symbolic-links=0 log-error=/var/log/mysqld.log pid-file=/var/run/mysqld/mysqld.pid # slave log-bin=mysql-bin # 服务器唯一id server-id=3 # 不备份的数据库 binlog-ignore-db=information_schema binlog-ignore-db=cluster binlog-ignore-db=mysql # 需要备份的数据库 replicate-do-db=myblog # 其他相关信息 slave-skip-errors=all slave-net-timeout=60 # 开启中继日志 relay_log = mysql-relay-bin # log_slave_updates = 1 # 防止改变数据 read_only = 1
重启slave,同时启动复制,还需要调整一下命令。
mysql> CHANGE MASTER TO MASTER_HOST = '119.23.46.71', MASTER_USER = 'root', MASTER_PASSWORD = 'helloroot', MASTER_PORT = 3306, MASTER_LOG_FILE = 'mysql-bin.000009', MASTER_LOG_POS = 346180;
可以看见slave已经开始进行同步了。我们使用show slave status\G来查看slave的状态。
其中日志文件和POSITION不一致是合理的,配置好了的话,即使重启,也不会影响到主从复制的配置。
某天在Github上漂游,发现了阿里的canal,同时才知道上面这个业务是叫异地跨机房同步,早期,阿里巴巴B2B公司因为存在杭州和美国双机房部署,存在跨机房同步的业务需求。不过早期的数据库同步业务,主要是基于trigger的方式获取增量变更,不过从2010年开始,阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务。下面是基本的原理:
原理相对比较简单:
1.canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议
2.mysql master收到dump请求,开始推送binary log给slave(也就是canal)
3.canal解析binary log对象(原始为byte流)
其中,配置过程如下:https://github.com/alibaba/canal,可以搭配Zookeeper使用。在ZKUI中能够查看到节点:
一般情况下,还要配合阿里的另一个开源产品使用otter,相关文档还是找找GitHub吧,个人搭建完了之后,用起来还是不如直接使用mysql的主主复制,而且异地机房同步这种大企业才有的业务。
公司又要996了,实在是忙不过来,感觉自己写的还是急躁了点,困==
欢迎访问我的个人网站O(∩_∩)O哈哈~希望能给个star
个人网站网址:http://www.wenzhihuai.com
个人网站代码地址:https://github.com/Zephery/newblog

相关文章推荐
- 谈谈个人网站的建立(二)—— lucene的使用
- 谈谈个人网站的建立(一)——建站历史和技术架构
- 谈谈个人网站的建立(三)—— 定时任务
- 谈谈个人网站的建立(四)—— 日志系统的建立
- 谈谈个人网站的建立(五)—— 小集群的部署
- 谈谈个人网站的建立(一)——建站历史和技术架构
- 谈谈个人网站的建立(一)——建站历史和技术架构
- 谈谈个人网站的建立(八)—— 缓存的使用
- 建立个人网站——申请空间、域名、数据库
- 谈谈个人网站的建立(七)—— 那些建站必备的插件
- 谈谈个人网站的建立(四)—— 日志系统的建立
- 建立个人网站——申请空间、域名、数据库
- 谈谈个人网站的建立(一)——建站历史和技术架构
- 谈谈个人网站的建立(一)——建站历史和技术架构
- 谈谈个人网站的建立(三)—— 定时任务
- 建立个人网站
- IP地址查询网站的建立(基于qqwry数据库建立)
- Linux系统中Apache+PHP+MySQL建立数据库驱动的动态网站
- 建立个人网站经验分享
- 博客文章同步到新的个人网站:http://114.215.157.129:8081/RobotBlog/index.jsp