linux高可用性架构概述
2017-11-18 21:38
218 查看
高可用集群的衡量标准
HA(High Available), 高可用性群集是通过系统的可靠性(reliability)和可维护性(maintainability)来度量的。工程上,通常用平均无故障时间(MTTF)来度量系统的可靠性,用平均维修时间(MTTR)来度量系统的可维护性。于是可用性被定义为:HA=MTTF/(MTTF+MTTR)*100%
具体HA衡量标准:
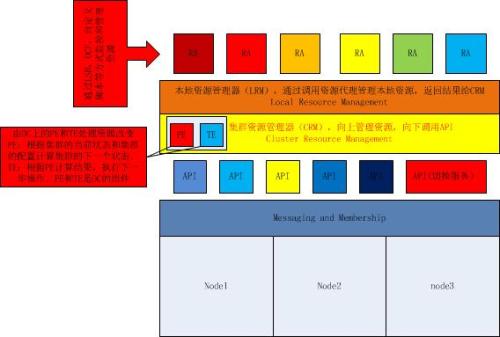
99% 一年宕机时间不超过4天99.9% 一年宕机时间不超过10小时99.99% 一年宕机时间不超过1小时99.999% 一年宕机时间不超过6分钟高可用集群可分为三个层次结构,分别由红色部分的Messaging与Membership层,蓝色部分的Cluster Resource Manager(CRM)层,绿色部分的Local Resource Manager(LRM)与Resource Agent(RA)组成,下面我们就来具体说明(如下图),
1.位于最底层的是信息和成员关系层(Messaging and Membership),Messaging主要用于节点之间传递心跳信息,也称为心跳层。节点之间传递心跳信息可以通过广播,组播,单播等方式。成员关系(Membership)层,这层最重要的作用是主节点(DC)通过Cluster Consensus Menbership Service(CCM或者CCS)这种服务由Messaging层提供的信息,来产生一个完整的成员关系。这层主要实现承上启下的作用,承上,将下层产生的信息生产成员关系图传递给上层以通知各个节点的工作状态;启下,将上层对于隔离某一设备予以具体实施。
2.集群资源管理层(Cluster Resource Manager),真正实现集群服务的层。在该层中每个节点都运行一个集群资源管理器(CRM,cluster Resource Manager),它能为实现高可用提供核心组件,包括资源定义,属性等。在每一个节点上CRM都维护有一个CIB(集群信息库 XML文档)和LRM(本地资源管理器)组件。对于CIB,只有工作在DC(主节点)上的文档是可以修改的,其他CIB都是复制DC上的那个文档而来的。对于LRM,是执行CRM传递过来的在本地执行某个资源的执行和停止的具体执行人。当某个节点发生故障之后,是由DC通过PE(策略引擎)和TE(实施引擎)来决定是否抢夺资源。
3.资源代理层(Resource Agents),集群资源代理(能够管理本节点上的属于集群资源的某一资源的启动,停止和状态信息的脚本),资源代理分为:LSB(/etc/init.d/*),OCF(比LSB更专业,更加通用),Legacy heartbeat(v1版本的资源管理)。
核心组件的具体说明:
1.ccm组件(Cluster Consensus Menbership Service):作用,承上启下,监听底层接受的心跳信息,当监听不到心跳信息的时候就重新计算整个集群的票数和收敛状态信息,并将结果转递给上层,让上层做出决定采取怎样的措施,ccm还能够生成一个各节点状态的拓扑结构概览图,以本节点做为视角,保证该节点在特殊情况下能够采取对应的动作。
2.crmd组件(Cluster Resource Manager,集群资源管理器,也就是pacemaker):实现资源的分配,资源分配的每个动作都要通过crm来实现,是核心组建,每个节点上的crm都维护一个cib用来定义资源特定的属性,哪些资源定义在同一个节点上。
3.cib组件(集群信息基库,Cluster Infonation Base):是XML格式的配置文件,在内存中的一个XML格式的集群资源的配置文件,主要保存在文件中,工作的时候常驻在内存中并且需要通知给其它节点,只有DC上的cib才能进行修改,其他节点上的cib都是拷贝DC上。配置cib文件的方法有,基于命令行配置和基于前台的图形界面配置。
4.lrmd组件(Local Resource Manager,本地资源管理器):用来获取本地某个资源的状态,并且实现本地资源的管理,如当检测到对方没有心跳信息时,来启动本地的服务进程等。
5.PE/TE组件:
PE(Policy Engine):策略引擎,来定义资源转移的一整套转移方式,但只是做策略者,并不亲自来参加资源转移的过程,而是让TE来执行自己的策略。TE(Transition Engine): 就是来执行PE做出的策略的并且只有DC上才运行PE和TE。6.stonithd组件
STONITH(Shoot The Other Node in the Head,”爆头“), 这种方式直接操作电源开关,当一个节点发生故障时,另 一个节点如果能侦测到,就会通过网络发出命令,控制故障节点的电源开关,通过暂时断电,而又上电的方式使故障节点被重启动, 这种方式需要硬件支持。
STONITH应用案例(主从服务器),主服务器在某一端时间由于服务繁忙,没时间响应心跳信息,如果这个时候备用服务器一下子把服务资源抢过去,但是这个时候主服务器还没有宕掉,这样就会导致资源抢占,就这样用户在主从服务器上都能访问,如果仅仅是读操作还没事,要是有写的操作,那就会导致文件系统崩溃,这样一切都玩了,所以在资源抢占的时候,可以采用一定的隔离方法来实现,就是备用服务器抢占资源的时候,直接把主服务器给STONITH,就是我们常说的”爆头 ”。是节点隔离工具。7.DC:可以理解为事务协调员,这个是当多个节点之间彼此收不到对方的心跳信息时,这样各个节点都会认为对方发生故障了,于是就会产尘分裂状况(分组)。并且都运行着相关服务,因此就会发生资源争夺的状况。因此,事务协调员在这种情况下应运而生。事务协调员会根据每个组的法定票数来决定哪些节点启动服务,哪些节点停止服务。 例如高可用集群有3个节点,其中2个节点可以正常传递心跳信息,与另一个节点不能相互传递心跳信息,因此,这样3个节点就被分成了2组,其中每一个组都会推选一个DC,用来收集每个组中集群的事务信息,并形成CIB,且同步到每一个集群节点上。同时DC还会统计每个组的法定票数(quorum),当该组的法定票数大于二分之一时,则表示启动该组节点上的服务;否则停止该节点上的服务。对于某些性能比较强的节点来说,它可以投多张票,因此每个节点的法定票数并不是只有一票,需要根据服务器的性能来确定。DC一般位于主节点上。8.fencing:资源级别的隔离,类似通过向交换机发出隔离信号,特意让数据无法通过此接口。CRM软件:heartbeat v1自带的集群资源管理为haresourceheartbeat v2自带的集群资源管理有haresource和crmheartbeat v3中的集群管理软件独立为pacemaker红帽RHCS集群提供的集群资源管理软件为rgmanagerMessaging and Membership软件:heartbeat v1的信息基础层heartbeat v2的信息基础层heartbeat v3cman红帽的信息基础层corosync基于open ais的信息基础层常见linux高可用性集群的组合方式及配置接口:
heartbeat v1 + haresources heartbeat v2 + crm heartbeat v3 + pacemaker + crmsh corosync v1 + pacemaker (corosync v1版本时没有投票系统,corosync v2有投票系统,当系统发生网络分区、脑裂时则将会将所有的资源转移至可用的其他主机之上) corosync v2 +pacemaker cman +rgmanager(RHCS集群) corosync v1 + cman +pacemaker (cman作为插件提供投票系统)资源:启动一个服务需要的子项目。例如启动一个httpd服务,需要ip,也需要服务脚本、还需要文件系统(用来存储数据的),这些我们都可以统称为资源。因此,实现一个高可用集群一般需要ip、服务(脚本)和文件系统(存储数据),当然有些高可用集群不需要存储设备的。资源也是有类型的,可以分为这样几类:(1)、primitive:可以理解为主资源,有时候看到的会是native,都是一个意思,该资源只在主节点上有。(当然备份节点一旦将资源夺过来了,也就成了主节点,因此,主节点是相对来说的)(2)、group:组资源,将多个资源绑定在一个同一个组上面且运行在同一个节点上。(3)、clone:是将primitive资源克隆n份且运行在每一个节点上(4)、master/slave:也是将primitive克隆2份、其中master和slave节点各运行一份,且只能在这2个节点上运行。 对于某些集群服务来说,启动相关的资源是有先后顺序的。例如启动一个mysql集群服务,首先应该先挂载共享存储设备,否则即时mysql服务启动起来了,用户也访问不了数据。因此,一般说来,我们需要将资源进行约束。资源约束有如下几类:(1)、位置约束(location):资源对节点的倾向程度,通常可以使用一个分数(score)来定义,当score为正值时,表示资源倾向与此节点;负值表示资源倾向逃离于此节点。也可以将score定义为-inf(负无穷大)和inf(正无穷大)。例如:有三个节点rs1、rs2、rs3当rs1是主节点且发生故障时,则比较rs2和rs3的score值,谁是正值,则资源将会转移到哪个节点上去。(2)、排列约束(colocation):用来定义资源是否可以在一起,通常也是使用一个score来定义的。当score是正值表示资源可以在一起;否则表示不可以在一起。通过定义资源类型为group也可以来将所有资源绑定在一起。(3)、顺序约束(order):用来定义资源启动和停止的顺序。例如,首先应该先挂载共享存储,在启动httpd或mysqld服务才行。资源粘性:用来定义资源是否倾向留在当前节点。通常使用score来定义,当score为正数表示乐意留在当前节点,负数表示不乐意留在当前节点。当某个高可用集群即包含资源粘性又包含位置约束,一旦该节点发生故障后,资源就会转移到另一个节点上去。但是当之前的节点恢复正常时,需要比较所有的资源粘性之和与所有位置约束之和谁大谁小,这样资源才会留在大的一方。 资源转移将有故障节点的VIP设置到另一个节点上去,并在另一个节点启用相应的服务,挂载相应的存储设备等等都可以叫做资源转移。
HA(High Available), 高可用性群集是通过系统的可靠性(reliability)和可维护性(maintainability)来度量的。工程上,通常用平均无故障时间(MTTF)来度量系统的可靠性,用平均维修时间(MTTR)来度量系统的可维护性。于是可用性被定义为:HA=MTTF/(MTTF+MTTR)*100%
具体HA衡量标准:
99% 一年宕机时间不超过4天99.9% 一年宕机时间不超过10小时99.99% 一年宕机时间不超过1小时99.999% 一年宕机时间不超过6分钟高可用集群可分为三个层次结构,分别由红色部分的Messaging与Membership层,蓝色部分的Cluster Resource Manager(CRM)层,绿色部分的Local Resource Manager(LRM)与Resource Agent(RA)组成,下面我们就来具体说明(如下图),
1.位于最底层的是信息和成员关系层(Messaging and Membership),Messaging主要用于节点之间传递心跳信息,也称为心跳层。节点之间传递心跳信息可以通过广播,组播,单播等方式。成员关系(Membership)层,这层最重要的作用是主节点(DC)通过Cluster Consensus Menbership Service(CCM或者CCS)这种服务由Messaging层提供的信息,来产生一个完整的成员关系。这层主要实现承上启下的作用,承上,将下层产生的信息生产成员关系图传递给上层以通知各个节点的工作状态;启下,将上层对于隔离某一设备予以具体实施。
2.集群资源管理层(Cluster Resource Manager),真正实现集群服务的层。在该层中每个节点都运行一个集群资源管理器(CRM,cluster Resource Manager),它能为实现高可用提供核心组件,包括资源定义,属性等。在每一个节点上CRM都维护有一个CIB(集群信息库 XML文档)和LRM(本地资源管理器)组件。对于CIB,只有工作在DC(主节点)上的文档是可以修改的,其他CIB都是复制DC上的那个文档而来的。对于LRM,是执行CRM传递过来的在本地执行某个资源的执行和停止的具体执行人。当某个节点发生故障之后,是由DC通过PE(策略引擎)和TE(实施引擎)来决定是否抢夺资源。
3.资源代理层(Resource Agents),集群资源代理(能够管理本节点上的属于集群资源的某一资源的启动,停止和状态信息的脚本),资源代理分为:LSB(/etc/init.d/*),OCF(比LSB更专业,更加通用),Legacy heartbeat(v1版本的资源管理)。
核心组件的具体说明:
1.ccm组件(Cluster Consensus Menbership Service):作用,承上启下,监听底层接受的心跳信息,当监听不到心跳信息的时候就重新计算整个集群的票数和收敛状态信息,并将结果转递给上层,让上层做出决定采取怎样的措施,ccm还能够生成一个各节点状态的拓扑结构概览图,以本节点做为视角,保证该节点在特殊情况下能够采取对应的动作。
2.crmd组件(Cluster Resource Manager,集群资源管理器,也就是pacemaker):实现资源的分配,资源分配的每个动作都要通过crm来实现,是核心组建,每个节点上的crm都维护一个cib用来定义资源特定的属性,哪些资源定义在同一个节点上。
3.cib组件(集群信息基库,Cluster Infonation Base):是XML格式的配置文件,在内存中的一个XML格式的集群资源的配置文件,主要保存在文件中,工作的时候常驻在内存中并且需要通知给其它节点,只有DC上的cib才能进行修改,其他节点上的cib都是拷贝DC上。配置cib文件的方法有,基于命令行配置和基于前台的图形界面配置。
4.lrmd组件(Local Resource Manager,本地资源管理器):用来获取本地某个资源的状态,并且实现本地资源的管理,如当检测到对方没有心跳信息时,来启动本地的服务进程等。
5.PE/TE组件:
PE(Policy Engine):策略引擎,来定义资源转移的一整套转移方式,但只是做策略者,并不亲自来参加资源转移的过程,而是让TE来执行自己的策略。TE(Transition Engine): 就是来执行PE做出的策略的并且只有DC上才运行PE和TE。6.stonithd组件
STONITH(Shoot The Other Node in the Head,”爆头“), 这种方式直接操作电源开关,当一个节点发生故障时,另 一个节点如果能侦测到,就会通过网络发出命令,控制故障节点的电源开关,通过暂时断电,而又上电的方式使故障节点被重启动, 这种方式需要硬件支持。
STONITH应用案例(主从服务器),主服务器在某一端时间由于服务繁忙,没时间响应心跳信息,如果这个时候备用服务器一下子把服务资源抢过去,但是这个时候主服务器还没有宕掉,这样就会导致资源抢占,就这样用户在主从服务器上都能访问,如果仅仅是读操作还没事,要是有写的操作,那就会导致文件系统崩溃,这样一切都玩了,所以在资源抢占的时候,可以采用一定的隔离方法来实现,就是备用服务器抢占资源的时候,直接把主服务器给STONITH,就是我们常说的”爆头 ”。是节点隔离工具。7.DC:可以理解为事务协调员,这个是当多个节点之间彼此收不到对方的心跳信息时,这样各个节点都会认为对方发生故障了,于是就会产尘分裂状况(分组)。并且都运行着相关服务,因此就会发生资源争夺的状况。因此,事务协调员在这种情况下应运而生。事务协调员会根据每个组的法定票数来决定哪些节点启动服务,哪些节点停止服务。 例如高可用集群有3个节点,其中2个节点可以正常传递心跳信息,与另一个节点不能相互传递心跳信息,因此,这样3个节点就被分成了2组,其中每一个组都会推选一个DC,用来收集每个组中集群的事务信息,并形成CIB,且同步到每一个集群节点上。同时DC还会统计每个组的法定票数(quorum),当该组的法定票数大于二分之一时,则表示启动该组节点上的服务;否则停止该节点上的服务。对于某些性能比较强的节点来说,它可以投多张票,因此每个节点的法定票数并不是只有一票,需要根据服务器的性能来确定。DC一般位于主节点上。8.fencing:资源级别的隔离,类似通过向交换机发出隔离信号,特意让数据无法通过此接口。CRM软件:heartbeat v1自带的集群资源管理为haresourceheartbeat v2自带的集群资源管理有haresource和crmheartbeat v3中的集群管理软件独立为pacemaker红帽RHCS集群提供的集群资源管理软件为rgmanagerMessaging and Membership软件:heartbeat v1的信息基础层heartbeat v2的信息基础层heartbeat v3cman红帽的信息基础层corosync基于open ais的信息基础层常见linux高可用性集群的组合方式及配置接口:
heartbeat v1 + haresources heartbeat v2 + crm heartbeat v3 + pacemaker + crmsh corosync v1 + pacemaker (corosync v1版本时没有投票系统,corosync v2有投票系统,当系统发生网络分区、脑裂时则将会将所有的资源转移至可用的其他主机之上) corosync v2 +pacemaker cman +rgmanager(RHCS集群) corosync v1 + cman +pacemaker (cman作为插件提供投票系统)资源:启动一个服务需要的子项目。例如启动一个httpd服务,需要ip,也需要服务脚本、还需要文件系统(用来存储数据的),这些我们都可以统称为资源。因此,实现一个高可用集群一般需要ip、服务(脚本)和文件系统(存储数据),当然有些高可用集群不需要存储设备的。资源也是有类型的,可以分为这样几类:(1)、primitive:可以理解为主资源,有时候看到的会是native,都是一个意思,该资源只在主节点上有。(当然备份节点一旦将资源夺过来了,也就成了主节点,因此,主节点是相对来说的)(2)、group:组资源,将多个资源绑定在一个同一个组上面且运行在同一个节点上。(3)、clone:是将primitive资源克隆n份且运行在每一个节点上(4)、master/slave:也是将primitive克隆2份、其中master和slave节点各运行一份,且只能在这2个节点上运行。 对于某些集群服务来说,启动相关的资源是有先后顺序的。例如启动一个mysql集群服务,首先应该先挂载共享存储设备,否则即时mysql服务启动起来了,用户也访问不了数据。因此,一般说来,我们需要将资源进行约束。资源约束有如下几类:(1)、位置约束(location):资源对节点的倾向程度,通常可以使用一个分数(score)来定义,当score为正值时,表示资源倾向与此节点;负值表示资源倾向逃离于此节点。也可以将score定义为-inf(负无穷大)和inf(正无穷大)。例如:有三个节点rs1、rs2、rs3当rs1是主节点且发生故障时,则比较rs2和rs3的score值,谁是正值,则资源将会转移到哪个节点上去。(2)、排列约束(colocation):用来定义资源是否可以在一起,通常也是使用一个score来定义的。当score是正值表示资源可以在一起;否则表示不可以在一起。通过定义资源类型为group也可以来将所有资源绑定在一起。(3)、顺序约束(order):用来定义资源启动和停止的顺序。例如,首先应该先挂载共享存储,在启动httpd或mysqld服务才行。资源粘性:用来定义资源是否倾向留在当前节点。通常使用score来定义,当score为正数表示乐意留在当前节点,负数表示不乐意留在当前节点。当某个高可用集群即包含资源粘性又包含位置约束,一旦该节点发生故障后,资源就会转移到另一个节点上去。但是当之前的节点恢复正常时,需要比较所有的资源粘性之和与所有位置约束之和谁大谁小,这样资源才会留在大的一方。 资源转移将有故障节点的VIP设置到另一个节点上去,并在另一个节点启用相应的服务,挂载相应的存储设备等等都可以叫做资源转移。

相关文章推荐
- Linux虚拟化: 虚拟 Linux 虚拟化方法、架构和实现概述
- Unix&Linux系统架构概述
- Linux SPI总线和设备驱动架构之一:系统概述
- Linux SPI总线和设备驱动架构之一:系统概述
- Linux内核架构概述
- Linux SPI总线和设备驱动架构之一:系统概述
- Linux SPI总线和设备驱动架构之一:系统概述
- Linux cpuidle framework(1)_概述和软件架构
- Linux SPI总线和设备驱动架构之一:系统概述
- Linux功耗管理(18)_Linux cpuidle framework(1)_概述和软件架构
- Linux PM QoS framework(1)_概述和软件架构
- Linux高可用性方案之Heartbeat架构
- Linux中的无线架构概述
- linux IIC子系统分析(二)—— linux i2c 架构概述
- XenServer架构之高可用性概述
- linux集群架构(一),集群概述、高可用配置
- linux集群架构(一),集群概述、高可用配置
- Linux SPI总线和设备驱动架构之一:系统概述
- Linux下架构高可用性网络----HA+LB+lvs 推荐
- Linux cpuidle framework(1)_概述和软件架构